Sakana AI Brings 11 Papers to ICML 2026, From Multi-Agent to Black-Box Optimization
Sakana AI will present a substantial body of work at ICML 2026 in Seoul, spanning multi-agent coordination, evolutionary algorithms, and foundation model techniques. Among the highlights, the paper "Bridging Spherical Black-Box Optimizers" proposes a unifying framework for connecting disparate optimization algorithms on spherical manifolds, aiming to close the gap between theory and practical deployment in high-dimensional model tuning.
Original Scaling Laws Paper Had a Bug, Leading to Years of Compute Waste
A researcher has revealed that a bug in the foundational scaling laws paper produced systematically wrong conclusions, causing labs to train models far larger than necessary for their data budgets. The bug meant optimal model sizes were underestimated, leading companies to burn enormous compute on oversized, undertrained models. This revelation comes before the industry even started properly accounting for inference cost in the total cost equation, compounding the inefficiency.
Claude Fable 5 Reasoning Distilled into Qwen3-4B with 100% Self-Consistency
A team from the University of Waterloo distilled 2.3 million reasoning traces from Claude Fable 5 into the compact Qwen3-4B model, achieving perfect self-consistency across 512 samples with zero-bit output errors. The result demonstrates that frontier-level chain-of-thought reasoning can be effectively transferred to much smaller, open-weight models through careful distillation, dramatically reducing inference costs while preserving output quality.
What if the model is the router? I think people underestimate the ability of frontier models now, but especially in the near future, to delegate work on their own as needed to dumber, cheaper models.
Ethan Mollick
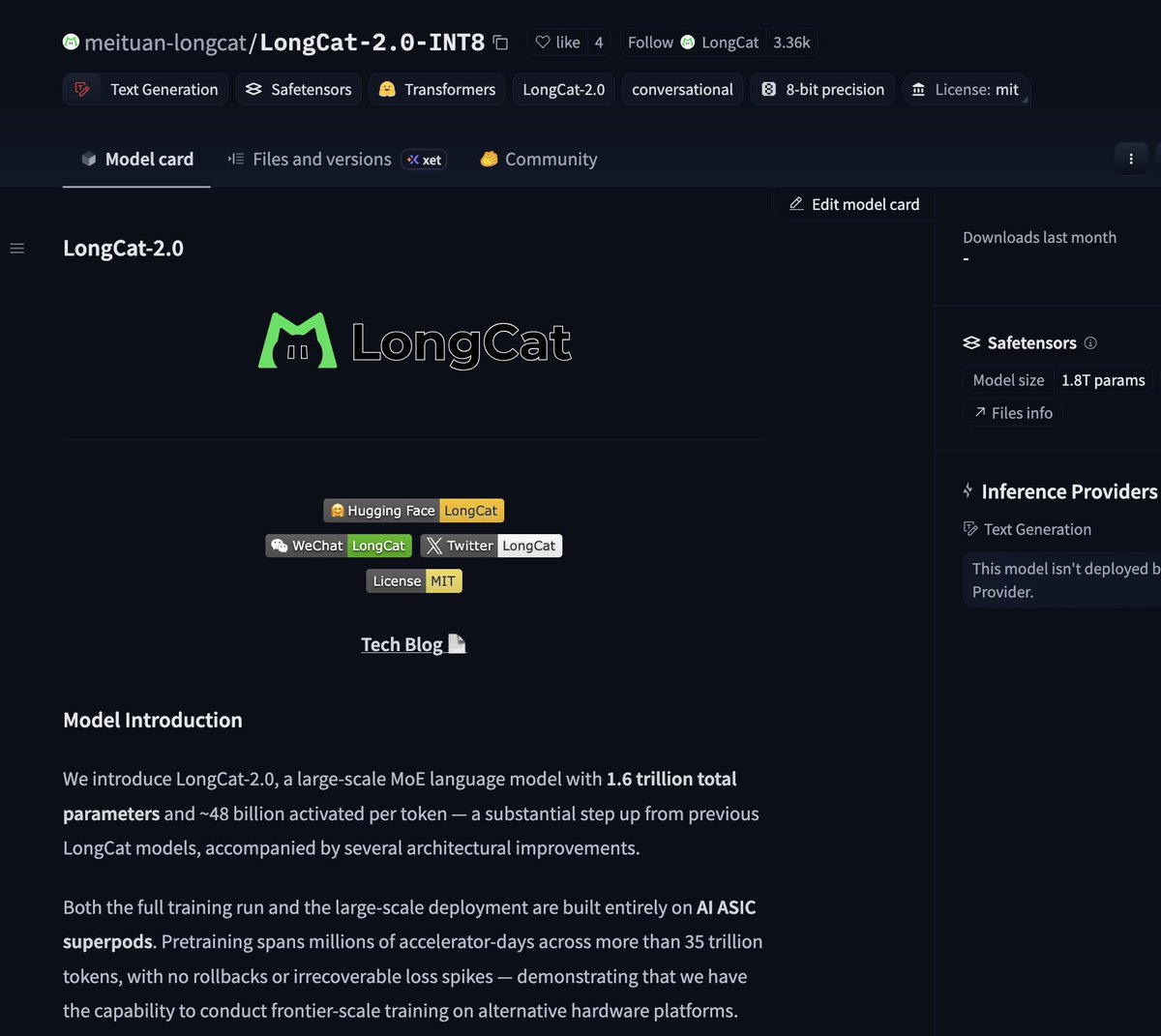
LongCat Weights Released: Largest Model Pretrained on Non-Western Chips
The LongCat model weights are now available on Hugging Face, representing the largest known pretraining run executed on non-Western hardware. The release offers a rare window into the capabilities of Huawei's chip stack at scale, decoupled from Meituan's data expertise. Evaluators are expected to scrutinize not just the model's benchmark scores but what the results say about the maturity of the underlying silicon ecosystem. The open-weight release invites the global research community to independently assess both the model quality and the hardware stack that produced it.
Compute Is Easier to Acquire Than Frontier Models, Two Years of Evidence Shows
A striking observation after two years of AI industry evolution: the path from having no compute to holding a solid chunk of global capacity is far shorter than the path from having abundant compute but no frontier model to having both. The implication is clear: algorithmic and architectural breakthroughs remain the true bottleneck. Hardware procurement, while capital-intensive, can be solved with money and partnerships. Building a genuinely competitive foundation model requires something far harder to buy: research talent, training infrastructure expertise, and the institutional knowledge that only comes from repeated, expensive failures.
Seedance 2.0 Goes Open Source with 4K Video Generation
Higgsfield AI released the full Seedance 2.0 project as open source, showcasing cinematic 4K video generation. The model supports prompt-driven scene composition and has already been used to create short films and experimental visual content.
GLM-5.2 Now Available Inside Claude Code via Hugging Face Inference
ZAI announced that the GLM-5.2 model is now selectable within Claude Code through Hugging Face Inference Providers, further bridging the gap between open-weight models and developer tooling.
Llama Index Ships Retrieval Harness for Modern Agentic Pipelines
Jerry Liu released a comprehensive Retrieval Harness providing persistent data infrastructure for agent-oriented retrieval workloads, addressing the growing need for reliable memory and search in multi-turn agent interactions.
Tau Law V2: Huawei LogicFolding Opens New Efficiency Tier for AI Chips
At comparable performance levels, Huawei's LogicFolding technology raises the energy efficiency ceiling for high-end AI chips while enabling a new tier of low-temperature, high-efficiency operation modes.
AI Learns from 10,000 Tumor Transcriptomes to Improve Immunotherapy
Shared by Yann LeCun, a study used AI trained on transcriptome data from 10,000 tumor samples across 33 cancer types to predict and improve immunotherapy outcomes, marking a significant clinical application of large-scale ML.
Diffusers Releases New Version with Ideogram4 and Video Pipelines
The latest Diffusers release adds multiple new image and video generation pipelines including Ideogram4 and MotifVideo, expanding the library's coverage of state-of-the-art generative model architectures.
We are leaving the Old Code Age, the Paleocodic, the artisanal code era, where if you needed a novel program, you would commission a local codesmith to hand-craft a work of code for you, bespoke.
Ethan Mollick
Moonshot Lab Bets on Breakthrough Architectures Over System Integration
Moonshot's lead says the lab can barely keep up with model research, prioritizing novel architectures over engineering integration. The lab is described as one of the only teams to fully internalize DeepSeek's lessons.
Blackwell Bandwidth + DeepSeek MegamOE Make 300 tps on GLM 5.2 Feasible
With NVIDIA Blackwell's increased memory and communication bandwidth combined with DeepSeek's megamoe operator, achieving 300 tokens per second on GLM 5.2 is within reach, while 150 tps is expected to become the new normal.
Baidu, Not OpenAI, Published the First Scaling Laws Paper
A reminder that Chinese AI research has never been as far behind as commonly assumed: Baidu was the first to publish on scaling laws, challenging the narrative that algorithmic breakthroughs require proximity to frontier labs.
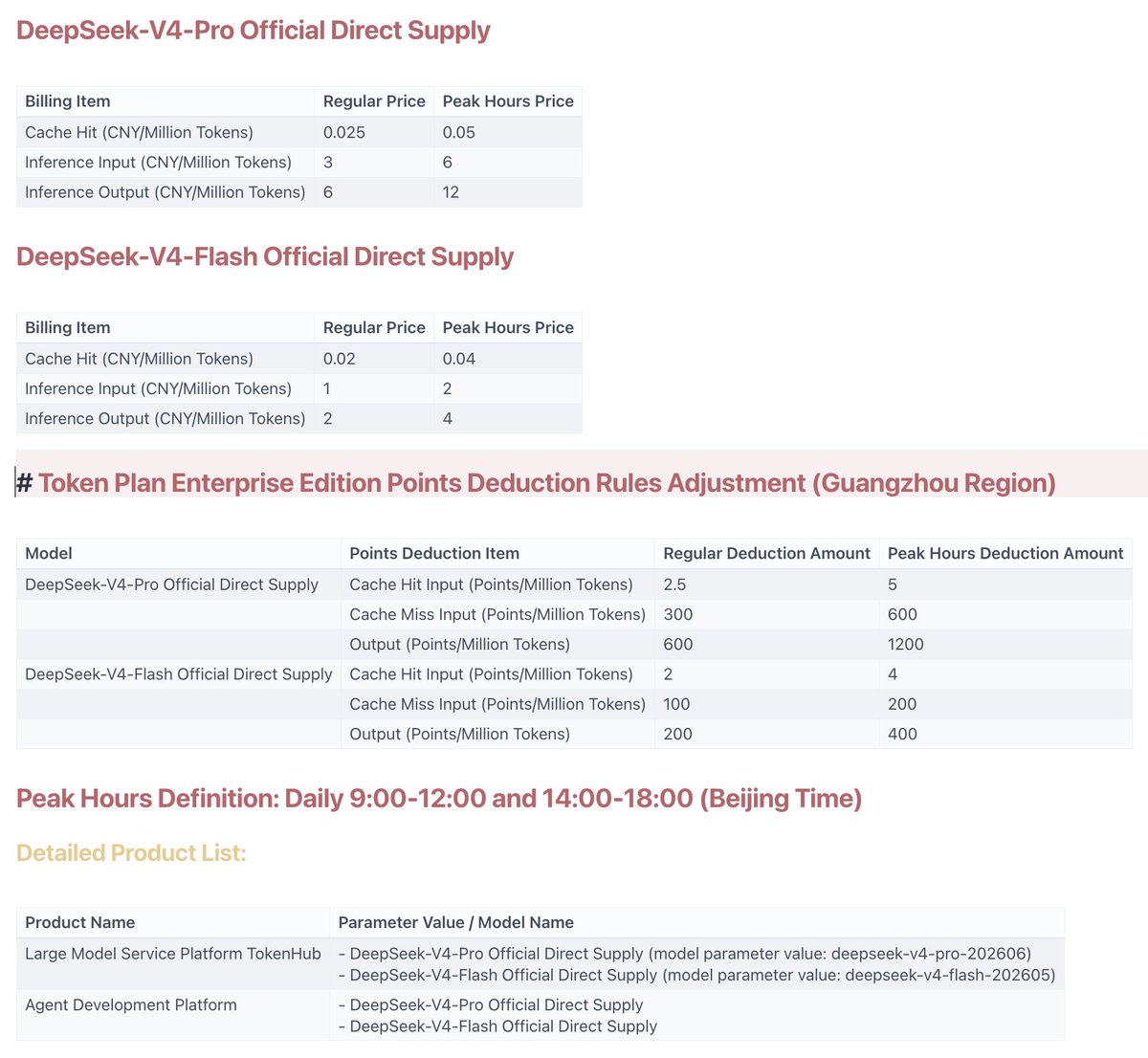
V4 Translates Chinese PDF at 138 Tokens Per Second, 61s Inference
V4-flash handled a 13.5K-token Chinese PDF translation at 138 tokens per second with minimal reasoning overhead. V4-pro delivered slightly better quality at 84 t/s over a 2-minute 55-second run.
GLM 5.2 Is 5x Cheaper Than Opus 4.8, Tops PostTrainBench
Cost comparison data shows GLM 5.2 undercuts Opus 4.8 by 5x and Fable 5 by 11x in pricing, while ranking first on the PostTrainBench benchmark, challenging assumptions about cost-quality trade-offs.
V4 Optimized for Both Blackwell and Huawei Chips in Full-Stack Hedge
DeepSeek V4 reportedly targets optimization for both NVIDIA Blackwell and Huawei silicon. While Huawei's chips weren't designed for V4, this dual-hardware approach serves as a comprehensive supply chain hedge against export restrictions.
Paper Proposes Domain-Specific Frontier Propagation Ratios for Small Models
A new paper suggests different domains exhibit different ratios of frontier propagation to model scale, enabling intelligent use of small sub-agent LLMs for exhaustive search in select branches.
Signs of Excessive On-Policy RL Detected in Recent Training Runs
Industry observers report telltale signs of over-reliance on on-policy reinforcement learning in recent model releases, raising questions about training methodology and reproducibility.