Anthropic Mythos 5 Partially Unblocked by US Government, 100 Institutions Regain Access
The US Commerce Department approved about 100 government agencies and critical infrastructure companies to resume using Anthropic's flagship cybersecurity model Mythos 5, but Fable 5 remains restricted for ordinary users.
Since June 12, Anthropic has been working closely with the US government to restore access to Claude Mythos 5 and Fable 5. The US Commerce Department notified the company that Mythos 5, its strongest cybersecurity model, can now be redeployed to a set of US organizations that operate and defend critical infrastructure. This partial unblocking represents a significant development in the ongoing tension between frontier AI safety controls and national security imperatives. The decision signals a nuanced regulatory approach: models deemed critical for national defense receive expedited clearance, while consumer-facing advanced models remain under tighter scrutiny. Anthropic continues to cooperate with regulators as the broader AI community debates whether such tiered access serves innovation and safety in equal measure.

DeepSeek Open-Sources DSpark Decoding Module, Significantly Boosts Inference Speed
DeepSeek released the DSpark decoding module for V4 model checkpoints, improving on MTP-1, Eagle-3 and DFlash, and also open-sourced the DeepSpec codebase for training and evaluating draft models for speculative decoding.
DeepSeek released DSpark, a new decoding module designed for V4 checkpoints, alongside DeepSpec, a comprehensive codebase for training and evaluating speculative decoding draft models. The DSpark module significantly outperforms prior approaches including MTP-1, Eagle-3, and DFlash in terms of inference throughput. In benchmarks shared by the community, DeepSeek V4-Pro achieves approximately 90 tokens per second in a 20K context, while V4-Flash reaches roughly 130 t/s. For comparison, Anthropic Opus achieves only 37 t/s in the same context. The open-source release of DeepSpec provides researchers and engineers with a complete pipeline for building and evaluating their own draft models for speculative decoding, marking a significant contribution to the inference optimization ecosystem.

Sakana AI's Fugu-Ultra Lands on Vercel AI Gateway
Fugu-Ultra is now available on Vercel AI Gateway, offering Fable-level intelligence with no extra markup and full BYOK support.
Sakana AI's Fugu-Ultra model has launched on the Vercel AI Gateway platform, providing developers with access to state-of-the-art AI intelligence at Fable-tier quality. The integration supports bring-your-own-key functionality and operates with no additional markup on API pricing. This partnership reflects a growing trend of frontier model providers leveraging Vercel's distribution infrastructure to reach broader developer audiences without building their own API gateways. The Fugu technical report reveals that instead of training a single larger model, Sakana AI built an orchestrator that reads each query and dynamically routes it to specialized sub-models, achieving strong performance through compositional intelligence.
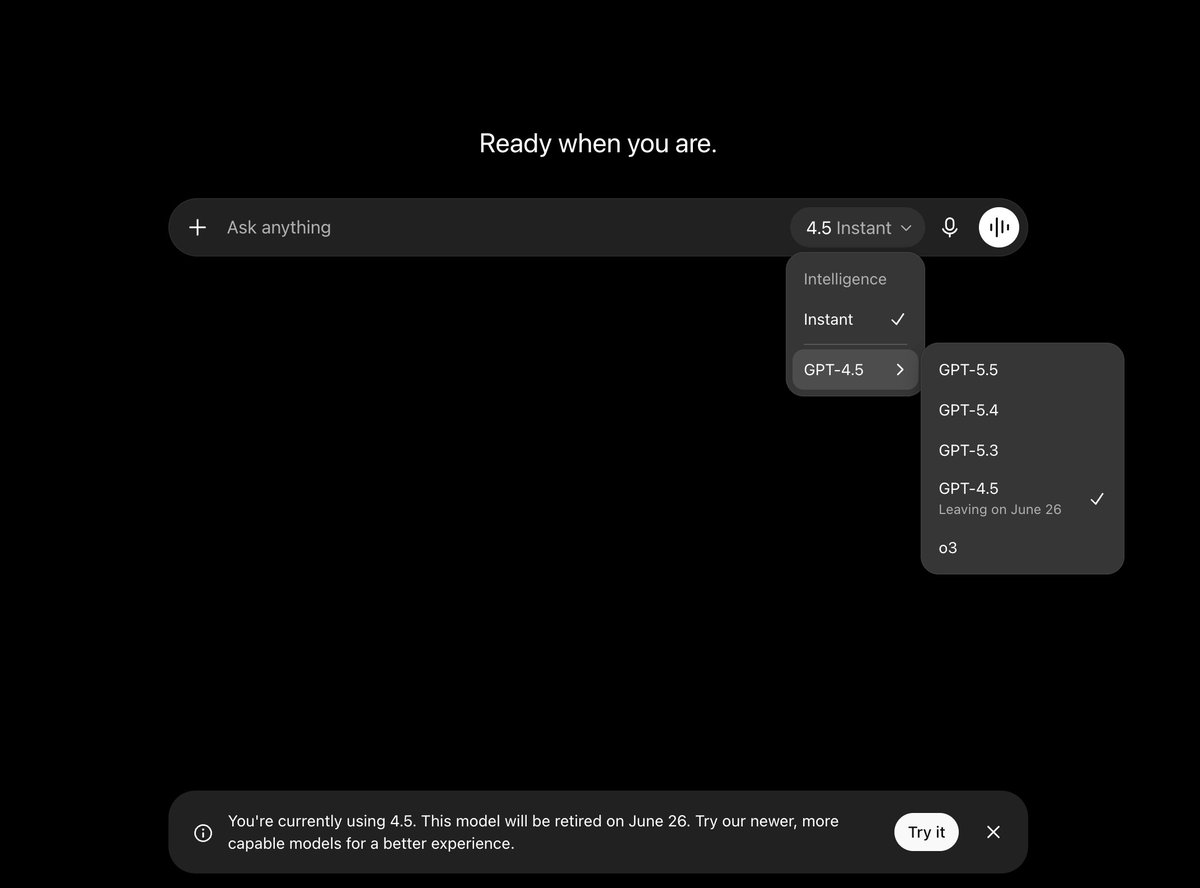
OpenAI Retires GPT-4.5, GPT-4 Era Ends on Consumer Side
On June 26, OpenAI removed GPT-4.5 from ChatGPT, marking the definitive end of the GPT-4 series on the consumer platform.
OpenAI has retired GPT-4.5 from ChatGPT, the last remaining model from the GPT-4 family available on the consumer platform. GPT-4.5 was only accessible to paid subscribers and had relatively low usage volume, but it was widely regarded as one of the finest writing models across all AI labs. Many in the AI community expressed disappointment, noting that the GPT-5 series has never quite matched GPT-4.5's distinctive prose style and creative voice. The removal signals OpenAI's continued push toward its latest generation of reasoning models while sunsetting older architectures. For users who valued GPT-4.5's nuanced writing, the transition marks a bittersweet end to an era in consumer AI.
Anthropic's political pressure on distillation is regulatory capture and most of the employees are blind to it under their veil of safety.
Nathan Lambert, AI Researcher
OpenAI Codex Update: Smoother Long Thread Scrolling
This week Codex received a quality-of-life update with improved long thread scrolling and stable conversation position retention.
OpenAI's Codex IDE shipped quality-of-life improvements this week, with long conversation threads receiving notably smoother scrolling. Users can now navigate through extended agent interactions without losing their place, a seemingly small but meaningful improvement for developers who rely on Codex for complex, multi-turn coding sessions. The update addresses a common friction point in AI-assisted development and reflects the growing importance of UX refinement alongside raw model capability improvements.
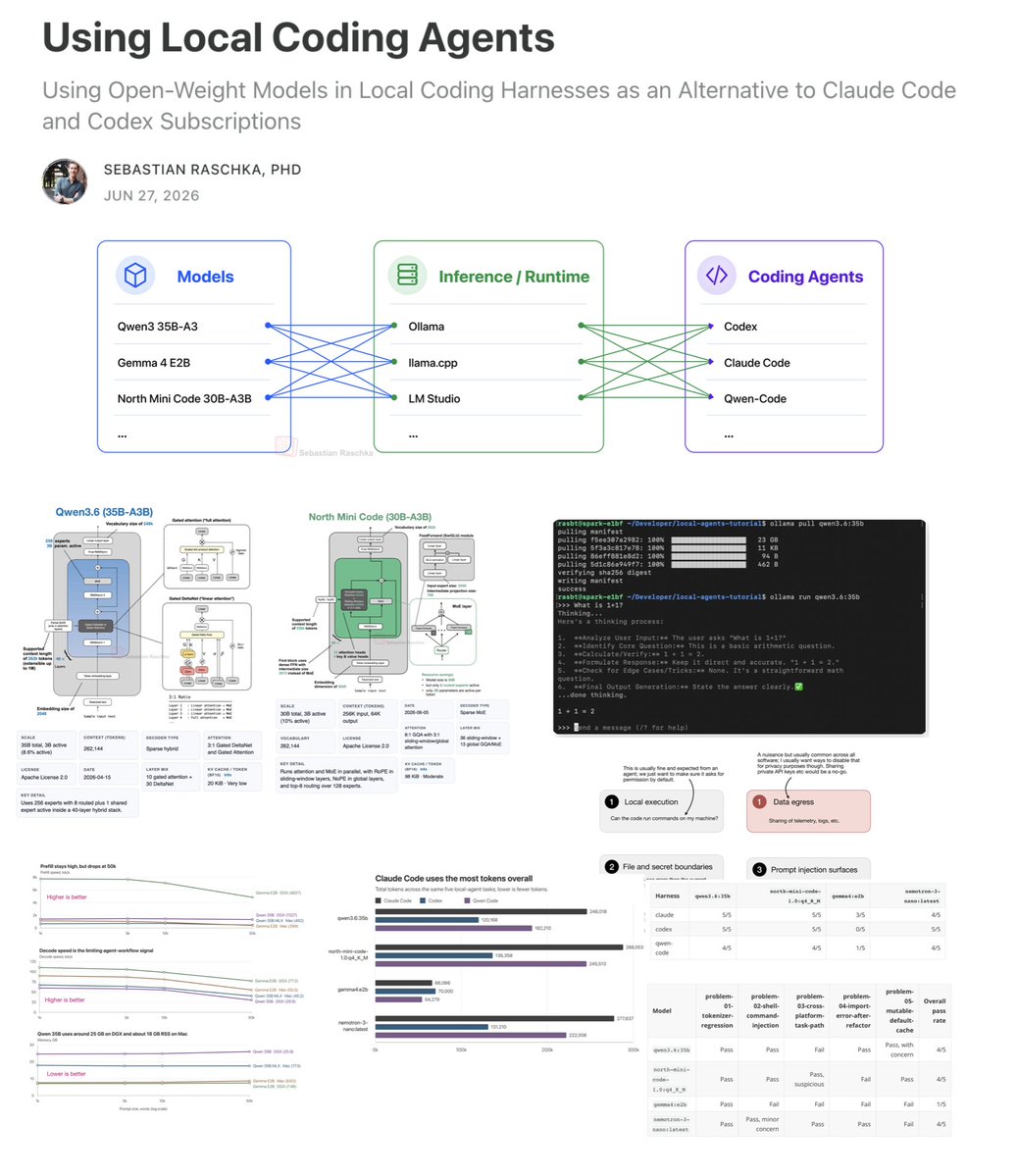
Sebastian Raschka Releases 100% Local Coding Agent Tutorial
A comprehensive guide on setting up a local coding agent using open-weight models, with every step running entirely on local hardware.
Sebastian Raschka published a detailed tutorial on configuring local coding agents with open-weight models, designed to run entirely on local hardware without cloud dependencies. Drawing from frequent community requests about his personal setup, Raschka documented the full pipeline from model selection and local server setup to integrating code execution tools. The article serves as both a practical reference and a motivation piece for developers interested in self-hosted AI coding assistants, emphasizing that capable local agents no longer require enterprise-grade infrastructure.
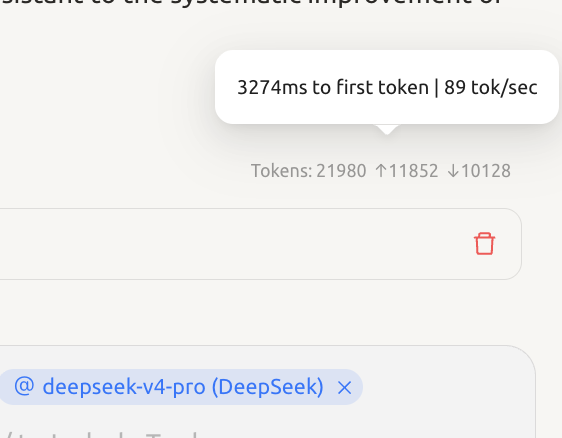
DeepSeek V4-Pro Hits 90 Tokens/s, Crushing Opus at 37 t/s
In a 20K context, DeepSeek V4-Pro runs at about 90 t/s, V4-Flash at 130 t/s, while Anthropic Opus manages only 37 t/s. If V4 gets an update bringing it closer to GLM efficiency, it could tear through the market.

Seedance 2.0 Shows Stunning Text Clarity at Native 4K
A CodePilot promotional video rendered at native 4K using Seedance 2.0 demonstrated text clarity and material quality far exceeding what 1080P super-resolution could deliver.

New Licensing Regime May End Vague Model Releases by AI Labs
Ethan Mollick commented that a new licensing regime could mean frontier labs can no longer release models in a deliberately vague manner, potentially bringing an end to the era of cryptic model teasers from the major AI companies.

DeepSeek Pursues Largest Open-Source Models, Not Consumer Hardware
Despite strong open-source contributions, DeepSeek consistently targets the largest open-source LLMs, with code clearly optimized for high-performance clusters rather than consumer-grade hardware like 4090s. It is a funny company, doing tremendous work for open source without pandering to the local AI crowd.
Agents Are Hard to Debug: Non-Determinism Meets Distributed Systems
Vercel CEO Guillermo Rauch noted that debugging AI agents is uniquely difficult because models are non-deterministic by design and agents are complex distributed systems involving multi-step computation across different components. Two identical prompts do not guarantee the same output.
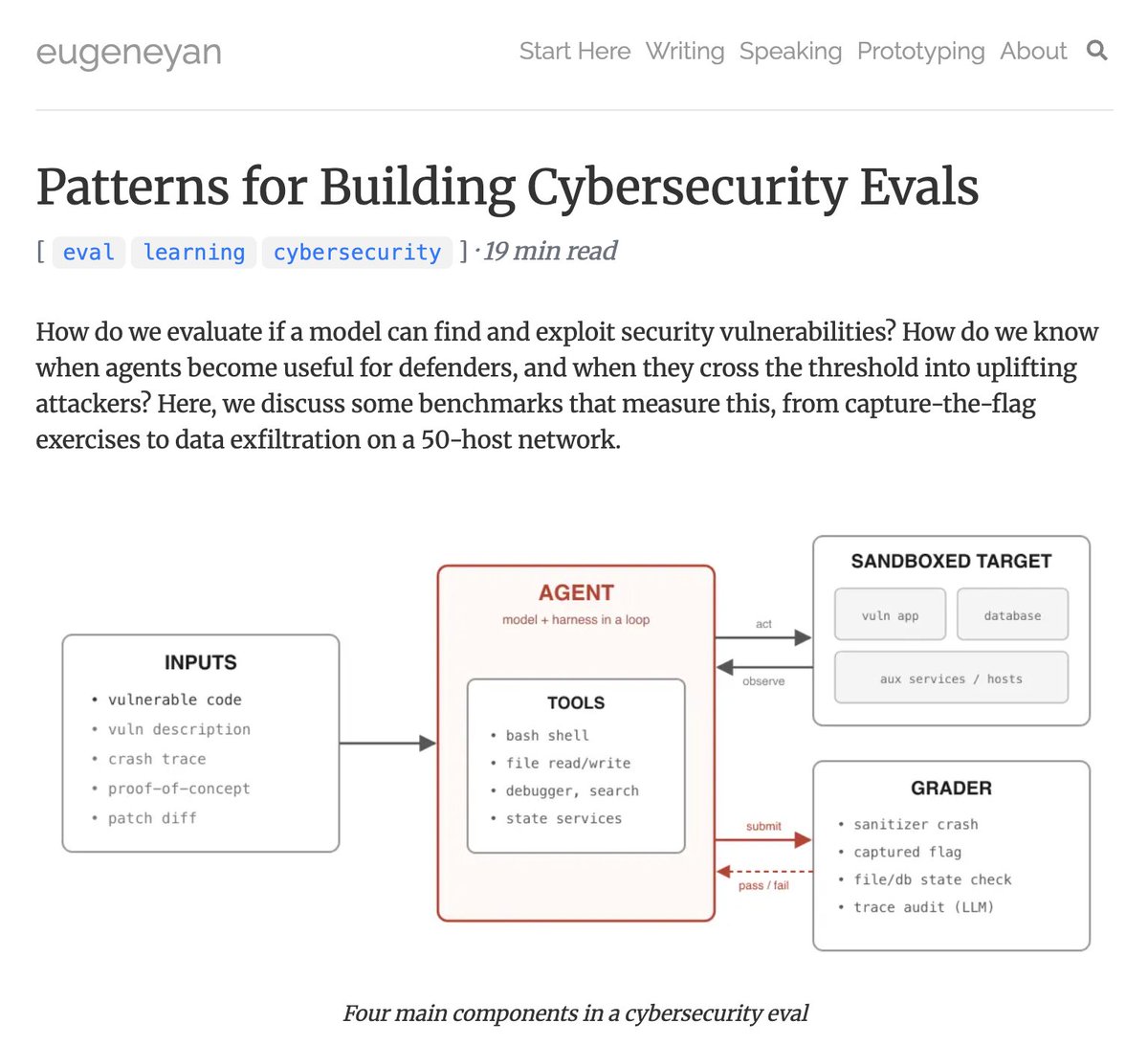
Cybersecurity Evals Now Stretch Beyond 24 Hours, Testing Model Endurance
A detailed write-up on building realistic cybersecurity evaluations reveals that modern eval tasks can take 24+ hours for a human to solve, pushing the boundaries of long-horizon AI agent assessment with multi-step environment resets.
Every Enterprise Will Have Its Own AI Model Flywheel
Perplexity CEO Aravind Srinivas predicts enterprises will develop model-harness-sandbox-eval flywheels driven by their unique domain knowledge, customer workflows, and trust, with token value per watt optimization at the core.
Human Judgment in Engineering Now More Crucial Than Ever
Vercel CEO argues that in the AI era, deciding what to build, choosing the right architecture, and managing tech debt matter more than ever. You can do anything now, but you cannot do everything.
Runway API Adds One-Click Translation for Ad Assets
Static ads and graphic assets can now be translated into multiple languages via a single API call using Runway's new localization Recipe, streamlining global campaign workflows.
BrowserBC Turns Human Browser Traces into Reusable Agent Skills
An open-source system that converts a single human browser recording into reusable agent skills, dramatically lowering the barrier to building browser-based AI agents.
hf-claude: Use 100+ Open Models Inside Claude Code
A new tool lets developers access over 100 open-source models including GLM 5.2, MiniMax-M3, and DeepSeek V4 Pro directly within the Claude Code interface.
CLI-Universe: Engine for Synthesizing Verifiable Terminal Agent Tasks
A principled engine that synthesizes terminal agent tasks from real-world materials, designed for training and evaluating command-line AI agents with verifiable ground truth.
MiniMax and Together AI to Discuss Scaling Agents at aiDotEngineer
Next week, MiniMax Research Lead and Together AI VP of Kernels will present both sides of building and operating agents at scale, covering training decisions and inference infrastructure.
Nathan Lambert Faces Pushback for Criticizing AI Regulatory Capture
The researcher reports receiving more hate than usual for speaking out about regulatory capture and unintentional attacks on open-source, while noting that many privately share his concerns.
Optimizer Design: Newton-Schulz vs Shampoo Compared in Detail
A deep dive comparing how Newton-Schulz and Shampoo handle pole factors, analyzing the impact of adaptive preconditioners on weight decay and discussing strategies for independent shrinkage via decoupled decay and learning rate scheduling.
Optimizer Mines: Interactive Notes on Training Algorithms
An interactive blog exploring optimizer architecture choices, showing that Newton-Schulz and Shampoo share the same sign direction but differ in scaling, with detailed analysis of square root correction in weight updates.