US Government and Anthropic Demonstrate Immense Power to Control Model Access
Andrew Ng warns that recent actions restricting frontier model use reveal a troubling new reality — one that, once seen, will be hard to unsee.

Over the last two weeks, both the U.S. Government and Anthropic took significant actions that demonstrated their power to control access to AI by restricting what others can do with frontier models. Andrew Ng argues this represents a critical inflection point whose implications extend far beyond any single policy decision. The ability to determine who may use the most advanced models reshapes the competitive landscape and raises fundamental questions about openness in artificial intelligence research and deployment.
Penn Experiment: Managers Achieve Highest Coding Success with Claude Code
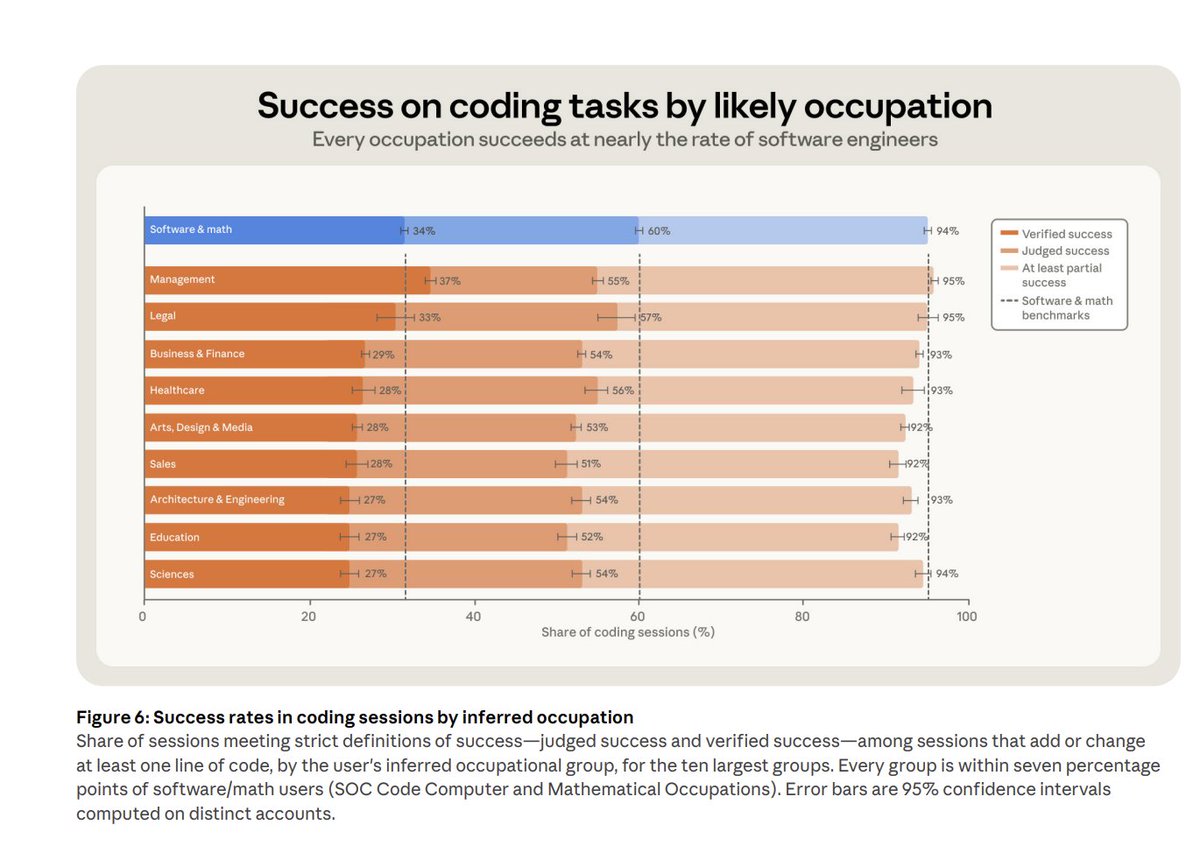
Ethan Mollick argues that management is an AI superpower: clearly specifying what you want, how to do it, and what good looks like is key to using coding agents effectively.
A striking experiment at the University of Pennsylvania revealed that MBA students with management backgrounds achieved the highest success rates when programming with Claude Code. The findings challenge conventional assumptions about who benefits most from AI coding tools. In the EMBA course, students built functioning startups from scratch in just four days — output that normally would take an entire semester. The critical variable was not technical skill but the ability to articulate clear requirements and evaluate outputs against well-defined criteria. Mollick proposes a delegation decision model based on human completion time, AI success probability, and AI processing time. Citing recent OpenAI research showing GPT-5.2 matches or exceeds human expert performance on 72% of tasks, he emphasizes that better prompting and clearer instructions can further amplify AI success rates. The experiment underscores a broader shift: as AI agents become more capable, the bottleneck is moving from technical implementation to the clarity of human intent.
1991: Transformer, Pretraining, Distillation and World Models Took Shape in Months
Sakana AI's hardmaru revisits the concentrated burst of foundational AI breakthroughs published by Schmidhuber's team at TU Munich in 1991.
In a single remarkable year, Jürgen Schmidhuber's team at TU Munich produced a series of papers that now read like a blueprint for modern AI. In March 1991 they published the first Transformer variant — a linear Transformer. April brought deep neural network pretraining and distillation. June introduced residual learning, the core mechanism behind LSTM and ResNet. By August, they had published generative adversarial networks and neural network world models. These concepts form the foundational building blocks of today's large language models and generative AI systems. Hardmaru notes these ideas shaped his thinking from his time at Google Brain through to current work on recursive self-improvement at Sakana AI. The post serves as a reminder that many of the ideas powering systems like ChatGPT have deeper roots than commonly acknowledged, and that concentrated, curiosity-driven research can yield decades of returns.
Cost per Task Varies 800x: Open-Source Models Deliver the Best Value
Fresh benchmark data reveals a staggering cost disparity across AI models: Claude Fable 5 tops the quality charts but averages over $31 per task, compared to approximately $0.04 for DeepSeek V4 Flash (max). The strongest price-to-performance options are open-weight models such as GLM-5.2 (max) and DeepSeek V4 Flash, which achieve near-frontier quality at a tiny fraction of the cost. The 800x spread between the priciest and cheapest models has ignited debate about the economics of AI deployment. For startups and research labs operating under tight budgets, the message is clear: open models now offer capabilities within striking distance of the most expensive proprietary alternatives at a cost difference measured in orders of magnitude. This shift is accelerating the commoditization of inference and reshaping procurement decisions across the industry.
What we achieved with AlphaFold changed the world, and showed the field what was possible with AI for science and medicine, lighting the way for how AI can benefit humanity.
— Demis Hassabis, DeepMind Founder
SGLang Powers Grok on xAI's Hundred-Thousand GPU Cluster
The SGLang inference engine co-authored by Ying Sheng is serving the Grok model on a cluster of hundreds of thousands of GPUs at xAI, a striking demonstration of the framework's production-grade scalability.
Large-Scale Chinese Study: AI Homework Use Hurts Academic Performance
A study in China found that using AI to complete homework reduces mental effort and leads to lower exam scores. AI tutoring alongside classroom instruction proved beneficial, but direct homework substitution consistently harmed learning outcomes.
GLM 5.2 Nears Opus Level, Defying Data Disadvantage Assumptions
Commentators note GLM 5.2's gap with Opus is negligible, possibly achieved through distillation without billion-dollar budgets. The result challenges claims that Chinese labs face catastrophic disadvantages in high-quality training data.
GLM Team Reveals OPD Training Cost Is Negligible Versus Pretraining
Technical details from the GLM-5.2 release suggest the entire online preference distillation training pipeline costs nearly nothing compared to pretraining and expert reinforcement learning, a finding that could reshape post-training strategy across the field.
OpenAI o3 Aids Families Facing Rare Genetic Disease Diagnosis
Greg Brockman shared that the o3 model, released over a year ago, is being deployed to help families navigate rare genetic diseases, demonstrating the enduring practical value of older models in high-impact medical applications.
Claude Code Fixes Usage Limit Bug, Resets Affected Users
About 3% of Claude Code Max and Pro users encountered an erroneous weekly usage limit display that blocked some from sending messages. The bug is now fixed and affected users' limits have been fully reset.
Llama Index Releases World's Fastest PDF-to-Markdown Parser
Jerry Liu announced Llama Index has built the fastest PDF-to-Markdown parser available, outperforming all existing open-source and model-free alternatives on both speed and accuracy metrics. The tool targets document ingestion pipelines for RAG and agentic workflows.
Inside Anthropic: Nearly Every Engineer Runs 100+ Self-Improving Agents
The creator of Claude Code revealed that internally at Anthropic, almost all engineers run more than 100 agents continuously, with each agent operating in self-improving loops. This insight into Anthropic's engineering culture highlights how deeply agentic workflows are embedded in frontier AI development.
Ethan Mollick: Companies Undervalue Advanced AI; Build Flexible Architectures
Even when weaker models appear sufficient for hitting KPIs at a lower price, Mollick contends companies should architect their systems to flexibly swap in smarter models. The ability to experiment with higher-intelligence systems may reveal value that simple cost-per-token calculations miss entirely.
Supervised Fine-Tuning Research Remains Severely Understudied
An AI researcher highlights that SFT, despite being a foundational post-training technique, suffers from a surprisingly sparse body of serious empirical literature. The field needs more rigorous study of SFT methods to match the attention given to reinforcement learning from human feedback and other post-training approaches.
Open-Source 9B Model Hits 90.2% Accuracy on Document Structure Extraction
Vik Paruchuri released a 9B-parameter model for structured data extraction from documents, achieving near-frontier performance on internal benchmarks. The model is fully open-source and designed for production document processing pipelines.
Vercel CEO: AI Agents Are Bringing the Original Vision of the Web to Life
Guillermo Rauch argues that agentic AI is driving healthy software practices — open APIs, documentation, testing suites, CLI interfaces, and standardized formats like Markdown and JSON — in ways that echo the original vision of the World Wide Web as an interconnected, programmable ecosystem.
US-China AI Model API Price Comparison Chart Goes Viral
A widely shared chart visually comparing API prices of major American and Chinese AI models underscores the dramatic cost differences reshaping global model adoption patterns.
Action Masking Emerges as Universal Technique in Agentic RL
After surveying the agentic RL literature, researcher C. Wolfe identifies action masking as one of the few cross-cutting techniques, now evolving with world-model methods like ECHO and PaW.
Jensen Huang Explains AI Agents with Workshop Worker Analogy
The model thinks, the harness gives it form, tools and skills let it act, and the runtime provides a place to get work done — a compact mental model from the NVIDIA CEO.
Continuous Batching Lands in TRL for GRPO: Faster and More VRAM-Efficient
Sergio Paniego shipped continuous batching support in TRL for GRPO. At 64 generations it runs faster than standard generation and consumes significantly less VRAM.
Artificial Analysis Launches AA-Briefcase for Agentic Knowledge Work
AA-Briefcase is a new benchmark designed for the next era of agentic knowledge work capabilities, targeting tasks that require sustained reasoning over multiple documents.
Recraft API Cuts Prices 12.5% and Boosts Speed by 50%
Recraft v4.1 and Utility series prices drop 12.5 to 16%, while standard model latency halves from 12s to 6s. Pro models see comparable improvements.
Single DGX Spark Runs 16 Parallel Gemma-4 Model Instances
A DGX Spark with 128GB unified memory drove 16 simultaneous Gemma-4-26B inferences at an aggregate throughput of 300 tokens per second, highlighting edge inference progress.
Replit Partners with LinkedIn to Showcase AI-Built Projects
Replit becomes a featured partner in LinkedIn's Connected Apps launch, allowing users to display projects built on Replit directly on their LinkedIn profiles.
Greg Brockman: Codex App Is Very Good
A terse but emphatic endorsement from OpenAI's co-founder for the Codex coding application, generating significant attention across the developer community.
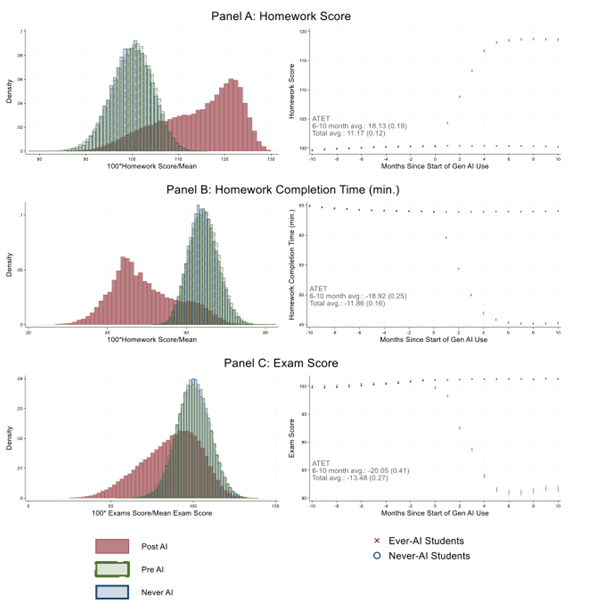
AI as Homework Substitute Is Actively Harmful, AI as Tutor Is Not
The consistent message across multiple studies is that AI-assisted learning depends entirely on how the tool is integrated. When AI supports classroom instruction — providing explanations, generating practice problems, offering hints — results improve. When students use AI to shortcut homework, the cognitive engagement drops and test scores follow. The large-scale Chinese study adds robust empirical weight to this pattern, tracking thousands of students whose homework time shrank as AI use increased. The finding challenges the ed-tech industry to design tools that scaffold learning rather than replace the mental effort that drives it.