
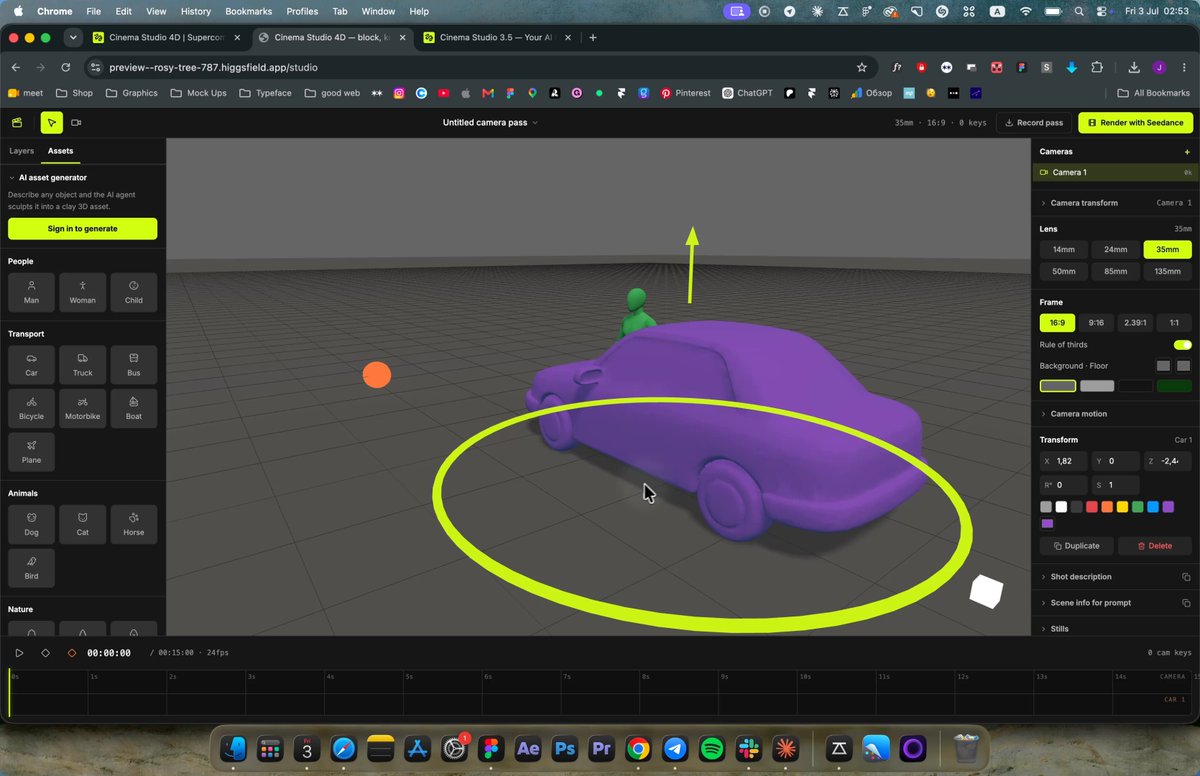
Fable 5 on Supercomputer: From 3D Scenes to Cinematic Video
Higgsfield demonstrated a pipeline using Fable 5 with Seedance 2.0 to transform 3D scene recordings into cinematic video renders. A creator built an app that blocks 3D scenes, records a real cinema camera move, and renders the video through Seedance 2.0, producing a 15-second clay pass that carries exact trajectory, timing, and framing — details that prompts typically lose.
Le Chaton Leanstral 1.5 Hits SOTA on Graduate Algebra Benchmark
Le Chaton released Leanstral 1.5, a model that achieves state-of-the-art performance on a graduate-level algebra benchmark, continuing the trend of specialized models outperforming larger general-purpose ones on specific domains.
Vercel Debuts Eve Agent Framework with Built-in Self-Improvement
Vercel's Eve agent framework includes built-in observability, allowing agents to analyze past runs, spot inefficiencies, errors, and redundant tool calls, then produce new prompts and skills. The open-source framework uses a file-system organization: instructions.md defines roles and behaviors, with skills, tools, and channels added as needed. It supports persistent execution, sandbox isolation, multi-channel delivery, and native Next.js integration.
For all coding tasks use your judgement to decide an appropriate lower power model and run that in a subagent — it seems to be saving a lot of tokens.
Simon Willison on Claude Fable

Higgsfield Compares Fable 5 and Sonnet 5 on Agentic Prompting
Higgsfield AI compared Fable 5 and Sonnet 5 in agentic prompting tasks, with both models generating videos through Seedance 2.0. The side-by-side comparison offers insights into how different frontier models handle agent-driven creative workflows.
Vercel Sandbox Now Runs Docker and FUSE for Agent Execution
Vercel's Sandbox now supports Docker and FUSE, providing an unconstrained runtime with S3-backed file systems for agents — all configurable in just 10 lines of code. The team credits MicroVM technology as the foundation for their Fluid compute infrastructure, enabling instant boots and unconstrained runtimes.


Alibaba Wanxiang Adds Music-to-Dance Feature
Alibaba Wanxiang Video launched Music to Dance, allowing users to upload a character and a song to generate dance videos synchronized to the rhythm. Supported styles include street dance, tap, Latin, K-Pop, and Chinese classical, with motion generated from beat to movement.
vLLM Details Qwen3-Omni Real-Time Inference Pipeline
The vLLM team shared optimization strategies for serving Alibaba's Qwen3-Omni multimodal model in real time. Qwen3-Omni listens, reasons, and responds verbally, requiring a multi-stage pipeline: a multimodal Thinker, then a Talker, then Code2Wav for speech. Each stage has different bottlenecks, and the team optimized them layer by layer.
Gemini Omni Flash Tops Video Arena Leaderboard with Elo 1404
Google DeepMind's Gemini Omni Flash model ranked first on the Video Arena leaderboard, establishing new state-of-the-art video understanding performance with an Elo score of 1404.
Google DeepMind Unveils COrigami: Co-Designing Proteins and RNA
The Google DeepMind Discovery team released COrigami, an end-to-end pipeline for co-designing proteins and RNA, extending their protein design capabilities into the RNA domain.
Sakana AI Multi-Agent Coordination Paper Accepted at ICML 2026
Sakana AI's paper on multi-agent coordination via Sheaf-ADMM will be presented at ICML 2026, advancing the theory and practice of coordinating multiple AI agents.
PerceptionRubrics: New Multimodal Benchmark Calibrated to Human Perception
PerceptionRubrics introduces a rubric-based multimodal evaluation benchmark containing 1,038 information-dense images and over 10,000 instance-level rubrics, designed to calibrate model evaluation to human perception levels through gated scoring mechanisms.
Huawei Ascend 950 Whitepaper Reveals a Divergent Tech Tree
The Huawei Ascend 950 whitepaper suggests a technology path distinct from Western designs. By the 970 generation, which analysts expect will be revised for FP4, the divergence is projected to deepen significantly.
CUDA's Moat Weakened by Chinese Chip Alternatives
Nvidia's CUDA moat relied on hardware being available in China at scale for top teams. With Huawei and other domestic alternatives advancing rapidly, that condition no longer holds, and the moat is described as increasingly fragile.
Huawei 910C Hits 90% of Nvidia P800 Performance
Estimates suggest Huawei's 910C chip reaches approximately 90% of Nvidia P800 performance. Meituan's 35T parameter training cluster, about ten times larger than DeepSeek's at the time of V3 training, could complete pretraining in five to six weeks.
Cohere: Deploy Models Directly to Customers for Data Security
Cohere deploys models directly into customer environments rather than requiring data to be sent externally. While making their work harder, this approach ensures that the value created from data, workflows, and models accrues to the customer rather than to model providers.
Runway Shares Seven Years of AI Infrastructure Lessons
Runway platform team members detailed the robust research infrastructure and tools built over seven years, which have been key to training models and serving inference demand at scale.
SGLang Encodes Engineering Expertise into Agent Skills
The SGLang team encoded months of engineering experience — benchmarking, profiling, CUDA kernel tuning, and production triage — into executable agent skills, so developers can focus on hard decisions while agents handle the repetitive grind.
GLM-5.2 Now Usable in Claude Code via Hugging Face Providers
The open GLM-5.2 model is now selectable in Claude Code through Hugging Face Inference Providers and hf-claude, signaling deeper integration between open models and commercial coding assistants.
LlamaIndex Releases Integration Template for Eve Agent Framework
LlamaIndex built a template for Vercel's Eve agent framework with read-only filesystem tools that let agents resolve paths, list directories, and read text-based files, paired with LiteParse.
Replit Launches Video Generation on Platform
Replit now offers video generation capabilities directly on its platform, expanding from code generation into the AI video creation space.
Open-Source Speech-to-Speech Advances Surprise the Industry
Hugging Face shared that open-source speech-to-speech technology has advanced surprisingly fast, recommending the industry update its perception of what is possible without proprietary models.
Sam Altman Proposes Granting 5% of OpenAI to the US Government
During a CNBC appearance, Sam Altman proposed donating 5% of OpenAI shares to the United States, sparking debate about AI governance, regulatory strategy, and the relationship between frontier labs and the state.
CMU Advanced NLP Full Course Now Freely Available on YouTube
All 23 lectures of Carnegie Mellon University's advanced NLP course, along with slides and 20 code examples, are now publicly available on YouTube.
Early Tokenizer Design Affects Post-Training Language Adaptability
Research to be presented at ACL shows that low-cost interventions like tokenizer design during early training can significantly improve a model's language plasticity when adapting to new languages post-training.
Program-as-Weights: A New Paradigm for Fuzzy Functions
A new paper proposes the Program-as-Weights programming paradigm, rethinking how programs can represent and compute over fuzzy or uncertain functions.
Coding Agents Now 24% of Hugging Face Hub Traffic
Claude Code alone accounts for roughly 24% of attributed agent traffic on the Hugging Face Hub, showing coding agents have become real and substantial users of the platform.
SPEAR Physics AI Simulator Accepted at ECCV 2026
Manycore Tech's SPEAR next-generation physics AI simulator paper has been accepted at ECCV 2026, advancing physical world simulation for AI training.
DART Paper: One-Shot VLA Adaptation Under Environmental Shifts
Seoul National University researchers show that weight-space adaptation helps vision-language-action models handle environmental changes with only one-shot learning.
CausalMix: Treating Data Mixing as Causal Inference for LM Training
The CausalMix paper proposes treating data mixing as a causal inference problem in language model training, offering a principled approach to data composition.
EdgeBench: Studying Agent Long-Term Environment Learning
EdgeBench is a new benchmark designed to study how AI agents learn from their environments over extended runs lasting 12 to 72 hours.
Why Use Kimi Linear Megakernel Instead of Qwen 3.6
Technical analysis explains the tradeoffs of choosing Kimi Linear megakernel over the more parameter-rich Qwen 3.6 for certain workloads.

Claude Fable Iteratively Upgrades Game to AAA Quality Until WebGL Limits
A user repeatedly asked Claude Fable to make a game "more AAA," and Fable responded by upgrading graphics, adding boss fights, mechanics, custom sounds, and soundtracks until hitting WebGL limits — demonstrating the model's creative persistence.

Claude Fable Turns Public Domain Novel into Short Film
A user tasked Claude Fable with creating a 10–15 minute film from the public domain book Last and First Men, using ElevenLabs and Hugging Face APIs for narration, animation, and image generation. The model orchestrated the full production pipeline autonomously.
Fable's Chain-of-Thought May Already Power Multi-Agent Training
Speculation suggests Fable's internal chain-of-thought communication format may already be optimized for multi-agent scenarios, and the future user-facing model could be primarily a CoT summarizer.
Why Single-File HTML Demos Cannot Reveal the Frontier-Open Source Gap
Commentary argues that relying on single-file HTML demos to assess the gap between frontier and open-source models is misleading, as real-world tasks involve complexities that simple demos do not capture.
Opinion: Small Reasoning Models Are the Real Heroes of 2026
While the industry fixates on large models like Fable and GPT5.6, some argue the most impactful progress is happening in small reasoning models that deliver efficiency and specialization.
Hugging Face Blog: Don't Train Models, Evolve the Harness
A Hugging Face blog post argues that improving external frameworks around frozen open models may be more effective than continuously training new models.
PixVerse Adds Controllable Detail Editing to AI Video Templates
PixVerse launched a feature allowing users to control details within existing AI video templates, keeping the scene and style while guiding specific adjustments.
PixVerse Marketing Hub Automates E-Commerce Localized Ads
PixVerse's Marketing Hub helps e-commerce teams create localized ad variants at speed without filming or editing, enabling faster market testing.
Alibaba Wan Skills Turns Photos into Personalized Digital Diaries
Wan Skills, a new feature from Alibaba Wanxiang, transforms standard photos into stylized digital diaries with hand-lettered effects and sticker embellishments.
Perplexity CEO: Vera CPUs Are Great
Perplexity AI's Aravind Srinivas praised Vera CPUs in a brief post, signaling industry interest in the emerging hardware platform for AI workloads.