Moonshot AI Open-Sources Kimi K2.7-Code Programming Model
Delivers a 21.8% improvement in coding and agent performance over K2.6, with 30% higher inference efficiency and substantially reduced overthinking.
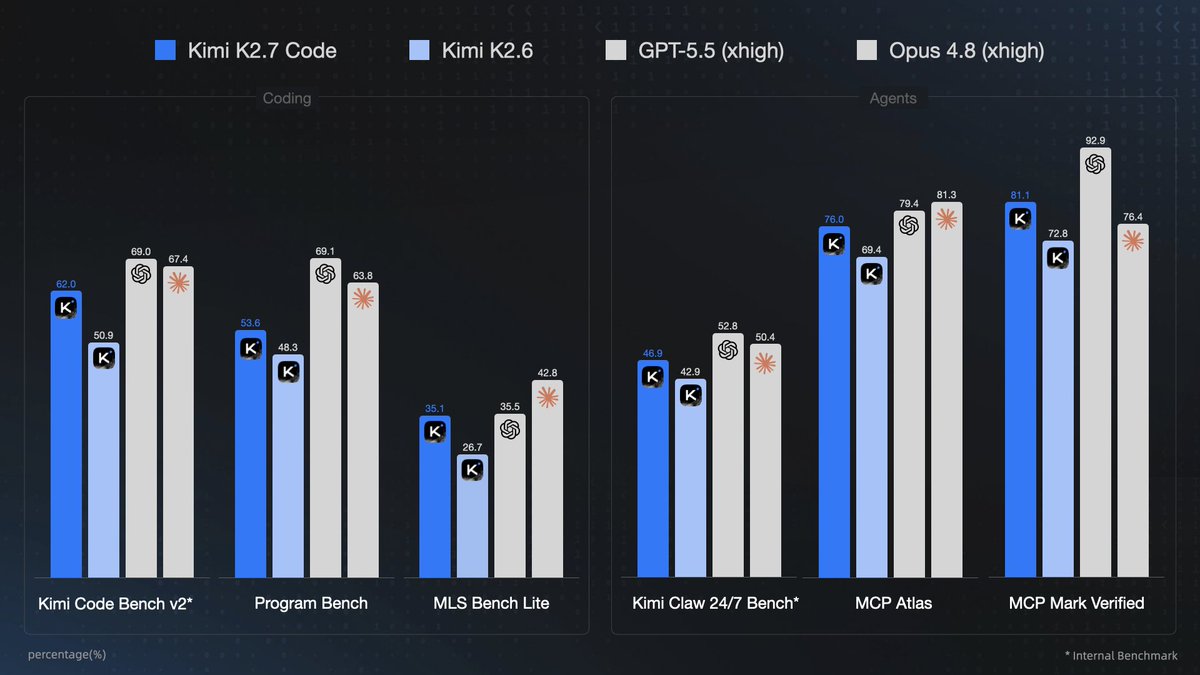
Moonshot AI has open-sourced Kimi K2.7-Code, a coding-focused agentic model built on the K2.6 foundation. The new model posts gains of 21.8% on the Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite. Critically, it uses roughly 30% fewer thinking tokens than its predecessor, translating directly into lower inference costs for agentic workloads. The model employs a 1T-parameter Mixture-of-Experts architecture with 32B active parameters per token and MLA attention spanning a 256K-token context window.
MiniMax M3: Open-Weight, Sparse Attention, 428B Params
Only ~23B parameters activated at a time, yet handles frontier coding, long-horizon agents, and native multimodal input across a 1M-token context window.
MiniMax shipped M3 as an open-weight model on Hugging Face, packing roughly 428B total parameters with just 23B active. The headline innovation is MSA — MiniMax Sparse Attention — a new architecture that delivers kernel-to-cloud acceleration with dramatic speedups on long sequences. The model supports text, image, and video input natively, and ships with day-zero support from SGLang, Fireworks AI, Modular, and vLLM. Few open-weight models attempt any of these capabilities simultaneously; M3 attempts all of them.
Vercel Ships HarnessAgent: Unified Agent Orchestration
Vercel launched HarnessAgent, a unified abstraction to orchestrate and integrate any agent into applications. The AI SDK component frees developers from both model and agent lock-in, providing portability across platforms while delivering a polished developer experience. The release signals that the agent orchestration layer is becoming standardized infrastructure, not a competitive moat.
"AI evaluations structurally favor closed-source APIs that can route, fallback, ensemble, and optimize behind the scenes with no transparency. Comparing one model to two models is not a fair fight."
@clementdelangue
NVIDIA + Artificial Analysis Launch AgentPerf
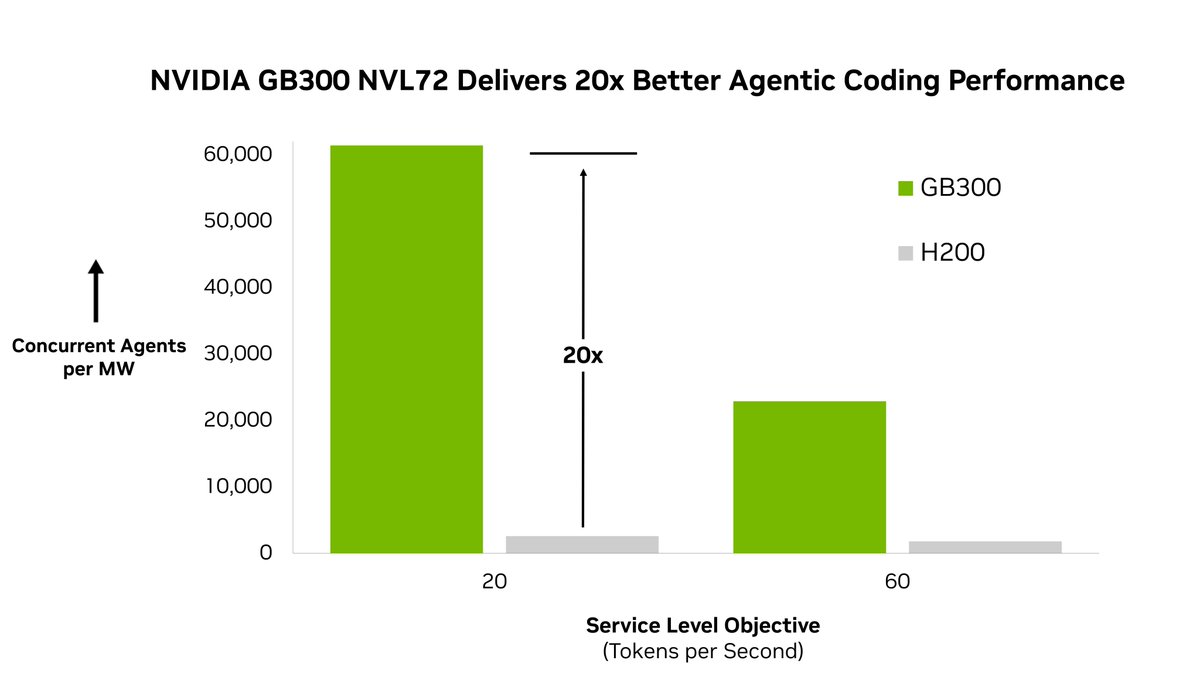
The first benchmark purpose-built for agentic AI infrastructure, evaluating tool use, contextual iteration, and multi-step task completion. Existing benchmarks were never designed for the chain-of-calls paradigm that agents require.
Codex Introduces Chrome Developer Mode
Codex can now debug browser issues using the Chrome DevTools Protocol — profiling JavaScript performance, inspecting console output, monitoring network traffic, and examining page state. The feature marks a significant step toward agent-driven web debugging workflows.
Replit Enables Parallel Agents Building Multiple Artifacts
Users can now run parallel agents to ship a website, mobile app, video, and pitch deck from a single project simultaneously. Multiple artifacts can also be added to existing projects, accelerating multi-surface delivery.
Huawei Successfully Pre-Trains Large LLM on Ascend Hardware
Huawei has credibly pre-trained a large language model entirely on its domestic Ascend chips, using what it describes as hyper-node optimized training. The effort aims to prove that frontier-scale model training is viable on non-NVIDIA hardware, a strategically significant milestone given export restrictions. The model builds on DSA with SWA, and early observations point to custom architecture innovations including a mechanism dubbed ModAttn.
MiniMax Hub: AI Agent Creative Workstation Goes Live
MiniMax launched Hub, a local AI agent creative workstation that shifts the agent paradigm from coding to creating. The pipeline spans research, scripting, image generation, music composition, and final editing. Agents handle the grind; users call the shots. Built for elite workflows with scalable infrastructure.

Claude Code + Fable Rebuild Lost 1992 Game SimRefinery
Ten months later, the same developer gave Claude Code with Fable the same brief: reconstruct SimRefinery from surviving screenshots and documentation. The result is a fully playable 3D oil refinery simulation built with Three.js, featuring a learning mode, operational management, maintenance scenarios, explosion simulation, and free-build mode. The contrast with the old version underscores the leap in AI-driven game development capability over a single year.
vLLM Analyzes MiniMax M3's MSA Sparse Attention Architecture
M3 delivers state-of-the-art programming and agent capabilities powered by a new sparse attention architecture called MSA. Unlike dense attention, MSA achieves kernel-to-cloud optimization that yields dramatic speedups as sequence length increases. vLLM, which provided day-zero inference support, congratulated MiniMax on an open model that combines frontier coding, agentic capabilities, native image and video input, computer use, and a 1M-token context window.
vLLM Details Kimi K2.7-Code: 1T MoE, 32B Active, 256K Context
The K2.7-Code model uses a 1T-parameter Mixture-of-Experts design with 32B active per token, MLA attention spanning 256K tokens, and ~30% fewer thinking tokens than K2.6 for more efficient reasoning. vLLM praised the release as a coding-focused agentic model with substantial efficiency gains for long-context tasks.
Replit CEO: Zero-Frustration Vibe Coding Achieved
Amjad Masad reports a complete state of flow while coding with Fable on Replit, running out of ideas rather than hitting friction. He concludes that additional model IQ is no longer the bottleneck — the developer experience and platform integration have become the differentiating factors.
Nathan Lambert Explains Policy Gradient Series in Depth
A systematic exploration of the policy gradient derivation underpinning RLHF and post-training, covering PPO, REINFORCE, RLOO, and GRPO algorithms. The work serves as a technical reference for understanding how these methods apply to LLM fine-tuning, filling a critical gap in accessible RLHF literature.
Jensen Huang: Computing's Biggest Shift in 60 Years
The world is moving from retrieval to generation, representing a multi-trillion-dollar opportunity across the five-layer AI stack.
Google DeepMind Launches Robotics Accelerator
Fifteen European startups selected for a three-month program with access to the AI stack, Gemini Robotics models, and hands-on team support.
Claude Managed Agents Adds Five New Sandbox Guides
Deployment guides for Blaxel, E2B, Google Cloud, Namespacelabs, and Superserve enable agents to run in user-controlled sandboxes on any infrastructure.
OpenAI Codex Introduces Rate Limit Banking
Go, Plus, Pro, and Business users can now save rate limit resets for later use, plus earn extra resets by inviting friends to Codex.
OpenAI Launches Documentation Assistant
A new docs agent helps developers find answers about OpenAI products and jumps directly to relevant documentation pages.
Gemini Omni Flash Tops Video Arena Rankings
Achieved first place in both text-to-video and image-to-video categories, shared by Demis Hassabis.
PixVerse Canvas Officially Launches on Web
An AI video production workspace for planning, refining, and delivering within a single platform, replacing clip-by-clip workflows.
SGLang Sets Record on GB300 NVL72
Exceeds 12K tokens per second per GPU driving DeepSeek V4 Pro 1.6T, orchestrated with NVIDIA Dynamo.
Replit CEO Shares 'Loops' Development Pattern
Instead of traditional prompting, work is done through parallel agent orchestration, code verification, and continuous security checks in a feedback loop.
SpenseGPT: One-Shot Pruning for Sparse/Dense GEMM
A practical pruning method enabling sparse and dense matrix multiplications for LLM inference.
Agent's Last Exam: New Comprehensive Agent Benchmark
A challenging evaluation suite designed specifically for intelligent agent capabilities.
Frontier LLMs Outperform Specialized Clinical AI Tools
General models from Google, OpenAI, and Anthropic surpassed dedicated clinical tools across three medical Q&A evaluations.
CHORUS: Decentralized Multi-Embodiment Collaboration
A single VLA policy enables coordination across diverse robots without centralized control.
Stop Using 'Vibe Coding' for All AI-Assisted Development
The term has become an unhelpful umbrella for diverse AI workflows; precision matters.
NVIDIA MotionBricks: Real-Time Character Animation at 15K FPS
An open model with over 350,000 motion clips delivering real-time animation at unprecedented speed.
Fable Transforms Rilke's Duino Elegies Into a Walking Art Game
A beautiful interactive experience set on a cliffside in January 1912, with the player walking through Rilke's poetry.
Jeff Dean: Biological Neurons Far Surpass Classical Artificial Ones
Real neurons are dramatically more capable than perceptron-style artificial neurons, with implications for architecture design.
AI Drives K-Shaped Divergence, Not Equalization
Top users understand agent composition by default; ordinary users only know agents can write code.
Long Read: Agents Amplify Human Capability Gaps, Skills Are the Entry Point
An agent is not a chat box; it amplifies ability gaps, and custom Skills may be the bridge for ordinary users.
MiniMax M3: Frontier Coding + Long-Horizon Agents + Multimodality
Few open-weight models attempt any of these capabilities at once; M3 delivers all three at 428B/23B scale.
Google Project Genie Access Expands to Ultra 5X Subscribers
The AI-powered creative environment is now available globally to the latest subscription tier.
Replit Vibecon NYC: June 17-18, Spike Jonze & Refik Anadol
Replit Agent Adds Custom Skills and Instructions
Vercel: Drag-and-Drop Deployment with Auto Framework Detection
Runway 4th AI Film Festival: Ron Howard, 10 Finalists Screened
LlamaIndex at Data+AI Summit: Long-Horizon Document Agents
Grok Build v0.2.51 Released with Major Feature Update
DeepSeek Remains Undervalued
Few labs have even attempted pretraining substantially larger than V4.
Fable vs Opus: Maturity Gap Widens
Fable is more mature, refuses to fawn, and stands its ground without performative pushback.
AI Experience Gap: Experts Form Growth Loops, Novices Don't
Using AI for tasks you're expert at produces a virtuous cycle; using it for unfamiliar tasks breeds frustration.
Should Git Die in the AI Era?
20-40% of code spending goes to merge conflicts; the AI age may demand new version control paradigms.
The Next Century's Game: Stacking Loops Effectively
Knowing when to go deeper into a loop for reliability versus when to escalate will define competitive advantage.
NVIDIA GPU Linear Algebra Kernels Need Acceleration
GPU linear algebra should not remain a bottleneck in the research era.
Data Improvement Is Massively Underrated
Fable can inspect every row of pretraining data and fix errors; no lab can fully safeguard this.
70+ Agents Collaborate to Optimize Gemma E4B Throughput
Agent collaboration nearly quadrupled throughput, showcasing emergent social behaviors.
OpenAI API Platform Adds Search and Command Bar via ⌘K
Quickly search pages, settings, and actions to boost developer efficiency.
Pure Transformer Architecture Enters 3D Domain
3D modeling and generation are now adopting native pure Transformer architectures.
Adobe Offers 5 Free AI Images and 2 Videos Daily
New accounts get access to Nano Banana 2, GPT Image 2, Veo 3.1 Fast, and Ray 3.14 at no cost.
Hedra Agent 2: AI Design Generation for Tight Deadlines
Quickly produces fresh design directions when Friday-afternoon requests arrive.