

Ideogram 4.0 Ships: 9.3B Diffusion Transformer Runs on Consumer GPUs
Ideogram has released Ideogram 4.0, a 9.3-billion-parameter Diffusion Transformer trained entirely from scratch. The model pairs its generative core with a frozen 8B vision-language model as the text encoder, enabling precise alignment between prompts and visual output. An nf4-quantized checkpoint allows the full 9.3B model to run on a single 24GB consumer GPU, dramatically lowering the barrier for local deployment. The release targets creative professionals and researchers who need open, capable text-to-image generation without cloud dependencies. A technical blog post accompanies the launch with architecture details and the training recipe.
Claude 4.7 Matches and Surpasses Dedicated NMR Analysis Software
Anthropic’s latest research demonstrates that Claude Opus 4.7 can interpret nuclear magnetic resonance spectroscopy data at a level competitive with dedicated chemistry software — and on certain tasks, it pulls ahead. NMR is the primary tool chemists use to determine molecular structure, a foundational step before any chemical manipulation. In experiments documented on the Anthropic Science Blog, Claude 4.7 correctly parsed complex spectra, identified structural features, and reasoned about molecular configurations with accuracy that surprised domain experts. The work signals a broader arc: general-purpose language models crossing into specialized scientific instrumentation, not by replacing the instruments, but by understanding their raw outputs.
Sakana AI Opens RSI Lab in Tokyo to Build Self-Improving AI Systems
Sakana AI has formally launched its Recursive Self-Improvement Lab in Tokyo, dedicated to building AI systems that iteratively optimize themselves. The lab’s philosophy draws from the Japanese manufacturing tradition of continuous incremental improvement, applied to AI training loops. Prior work from the team includes ShinkaEvolve, which solves complex problems from only 150 training samples, and ALE-Agent, which outperformed 804 human experts. Rather than chasing raw compute scale, the RSI Lab targets sample efficiency under realistic compute constraints — a design posture shaped by Japan’s sovereign AI strategy. The lab’s founding marks a distinct fork from the scale-maximalist approach dominant elsewhere.
Perplexity Adds NVIDIA Nemotron 3 Ultra for Long-Horizon Agent Workloads
Perplexity has made NVIDIA’s Nemotron 3 Ultra available to all Pro and Max subscribers. The open model is purpose-built for long-running agent tasks — the kind that span multiple tool calls, extended reasoning chains, and persistent context. The deployment brings a frontier-grade alternative to Perplexity’s model lineup, with the model also receiving quantized checkpoints from Red Hat (FP8 and W4A16) and first-class vLLM serving support.
“Token costs are why there will be no SaaS apocalypse. Good dev tools are cached intelligence for agents.”
The HF CEO argues that the popular theory — agents will rewrite every tool from scratch, hitting raw APIs and erasing the software layer — ignores the economic reality of token pricing. Each rebuild burns inference budget. Well-built tools, in his view, function as compressed, reusable intelligence that agents should call rather than re-derive.
Google Gemma 4 QAT Lands Everywhere: HF, Ollama, LM Studio, vLLM
Google released Quantization-Aware Training checkpoints for all Gemma 4 model sizes, and the ecosystem mobilized overnight. Hugging Face hosts the collection. Ollama added one-command launch support. LM Studio published them with memory-optimized presets. vLLM was named Google’s recommended inference engine. The QAT variants preserve model quality while cutting VRAM requirements, bringing Gemma 4 — Google’s most capable open model series, based on Gemini 3 research with vision input support — within reach of local deployment across the full size range from E2B to 26B parameters.

Vercel Partners with Shopify: Prompt a Next.js Store in Seconds
Vercel and Shopify are integrating, starting with v0. Users can now prompt a full Next.js-powered Shopify storefront into existence, collapsing the old tradeoff between the ease of an all-in-one platform and the flexibility of a headless build. The partnership eliminates months of scaffolding: a single natural-language prompt generates a production-ready store with no ceiling on scale or customization. Rauchg framed it as removing the false choice between “easy monolith” and “costly headless.”
Cursor Launches Design Mode: Click, Draw, or Talk to Update UI
Cursor shipped Design Mode, a new interaction paradigm that lets developers modify their application interface by pointing at elements, sketching desired changes, or speaking commands. Instead of manually editing layout code, users interact directly with the rendered UI to drive updates. The feature represents a step toward closing the loop between visual intent and code, making UI iteration feel more like a conversation with the surface than an edit-compile-refresh cycle.

NitroGen Earns CVPR Honorable Mention, Advances Generalist Embodied Agents
NitroGen, from Jim Fan’s team, also received a Best Paper Honorable Mention at CVPR 2026. The work pushes toward general-purpose embodied agents that master not only real-world physics but also the distribution of possible physics across a multiverse of simulations. Built on four years of work since the MineDojo project, NitroGen trains agents that transfer between simulated and real environments with increasing fidelity. The paper joins SAM 3D in this year’s crop of CVPR honorees advancing perception and action in the physical world.

Recraft V4.1 Delivers Sharper Brand Aesthetics and Poster-Grade Typography
Recraft released V4.1 with two headline capabilities. First, it produces bolder product-campaign visuals with stronger brand consistency and more realistic detail straight out of the box, displacing the multi-step refinement workflows previous versions required. Second, it introduces poster-style generation: bold typography, glossy 3D characters, sticker graphics, and clean contemporary layouts that feel designed rather than generated. Both improvements target the gap between AI image output and production-grade commercial creative work.
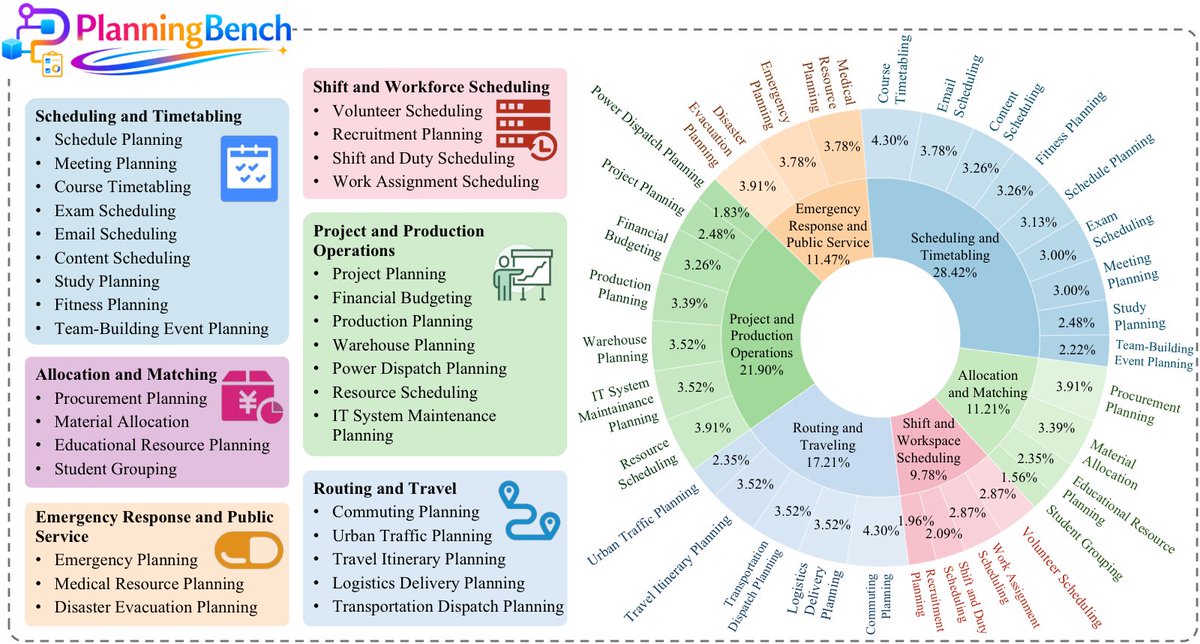
Tencent and Renmin University Open-Source PlanningBench for LLM Evaluation
Planning is where language models cross from saying to doing. Tencent Hunyuan and the Gaoling School of AI at Renmin University open-sourced PlanningBench, a scalable, verifiable framework for evaluating and training LLM planning capabilities. Rather than relying on static multiple-choice tests, the benchmark generates structured planning problems with automatically verifiable solutions, enabling both evaluation and training at scale. The release addresses a persistent challenge: measuring whether a model can actually plan, not just describe a plan.
Compositional Muon Optimizer Controls Operator-Norm Perturbations in Transformers
Tilde Research proposed Compositional Muon, an extension of the Muon optimizer that lifts optimization to the compositional level. In neural network operations like the attention QK product, controlling the operator norm of each matrix independently does not bound the overall functional change. CM introduces dynamic partner-whitening update rules that adapt step sizes based on the spectral geometry of paired matrices, improving stability during compositional updates. The work targets a subtle but consequential source of training instability in deep transformers.
AutoScientist Accelerates ML Research from Months to Days Across Ten Domains
Sarah Hooker announced that AutoScientist will support builders releasing frontier models across ten domains this summer, spanning medicine to underserved languages. The platform compresses the research-and-development cycle from months to days. All resulting models will be open-sourced to Hugging Face and Kaggle. The initiative targets a structural bottleneck in ML research: the time and expertise required to go from an idea to a trained, evaluated, and documented model. AutoScientist automates the pipeline end to end, aiming to make frontier model development accessible to domain experts without large-scale engineering teams.

NVIDIA Backs Sarvam AI for Full-Stack 'Made in India' Sovereign AI Platform
Sarvam AI is building a full-stack AI platform on NVIDIA infrastructure, training 100B+ parameter mixture-of-experts models across more than 4,096 H100 GPUs. The platform delivers millisecond-level multilingual voice capabilities and is positioned as a sovereign-AI answer to the concentration of frontier models in Western labs. NVIDIA framed the project as proof that population-scale sovereign AI is no longer theoretical; it is shipping.
PixVerse Originals Funds AI Short Films from Creators Across Ten Countries
PixVerse launched PixVerse Originals, backing ten filmmakers from Indonesia, Canada, the United States, China, and Ukraine with credits, funding, and global distribution. Each creator built a self-contained world using AI production tools, and the resulting shorts span genres from neon-salvage sci-fi to intimate narrative. The initiative marks an escalation in AI-native film production: moving from isolated experiments to a structured slate of commissioned work.
Amp Ships GPT-5.5 Deep and Rush Modes, Cutting Task Time by 40%
Amp’s new deep and rush modes, powered by GPT-5.5, deliver up to 40% faster task completion. The speedup required a full rebuild of Amp last month.
MiniMax M3 Arrives on DGrid with 1M-Token Context
MiniMax’s frontier coding model M3 — with native multimodal support and 1M-token context window — is now accessible through the DGrid platform, expanding availability beyond MiniMax’s own API.
Vercel Skills API: An npm Registry for Agent Capabilities
Vercel released an open Skills API that acts as a registry for agent capabilities and extensibility — free, open, and designed to make all agent platforms smarter through shared, composable skill modules.
Vercel Ships Decoupled Virtual Storage for Agent Filesystems
Agent filesystem state can now be read, written, and mounted independently of sandbox lifecycle. The virtual storage infrastructure decouples persistence from compute, attachable across Builds, Functions, and Sandboxes.
Large-Codebase Vibe Coding Depends Heavily on Documentation
Developers report that as Claude Code’s Plan mode was deprecated, documentation complexity surged — the document system is effectively the harness for large-scale AI-assisted coding projects.
Coding Skill Spills Over into General Language Intelligence
Observations note that since the GPT-3 era, improvements in code generation have consistently boosted broader natural-language reasoning, because reasoning about project architecture is a more general capability than it appears.
Activation Oracles Improved for More Reliable Interpretability
Neel Nanda’s scholars improved Activation Oracles, making the interpretability tool more specific and reliable — focused on qualitative improvement, not just benchmark scores.
AI Film 'Nexus' Trailer: Three People, Two Weeks, One Dreamina
A five-minute teaser for the hybrid feature film “Nexus,” built by three people in two weeks using Dreamina AI’s Octo and Seedance 2.0, amassed over 470,000 views, demonstrating AI’s accelerating role in independent filmmaking.
Coding Agents Autonomously Solve Tasks with Just 'Figure It Out'
A demo shows coding agents completing complex multi-step programming tasks after receiving only the instruction “just figure it out.”
Gemini 3.5 Flash Installs and Runs Stable Diffusion 1.5 in 20 Minutes
Using the Antigravity CLI with Gemini 3.5 Flash, an agent independently installed the original CompVis Stable Diffusion 1.5 repository, downloaded weights, debugged issues, and generated output — all in 20 minutes, without human intervention.
Codex Skill Turns Text into Explanatory Illustrations
A Codex skill discovered in the wild can ingest blog posts, articles, or even source code and produce illustrated explainer graphics with a consistent character style.
Red Hat Releases Quantized Nemotron 3 Ultra for vLLM
Red Hat published FP8 Dynamic, FP8 Block, and W4A16 G128 quantized checkpoints of Nemotron 3 Ultra on Hugging Face, pre-configured for vLLM serving.
Huawei Plans 30KW Single-Chip AI Processor for 2030
Huawei expects its Ascend processor with LogicFolding 3D design to reach 30KW per chip by 2030-2031, hinting at Cerebras-style wafer-scale engines with extreme power density.
Ascend SuperCluster: 64K m², 524K NPUs, 75.5 PB HBM
Announced at Huawei Connect 2025, the system’s total bill of materials exceeds five times all CloudMatrix 384 units sold combined.
Huawei 950 SuperCluster Likely Exceeds 500 MW
Compared to Cerebras WSE-3’s projected 47 MW for 2,048 wafer-scale systems, Huawei’s cluster architecture pushes into unprecedented territory.
Huawei Ascend Cannot Use LogicFolding Until Early 2030s
A paper by Huawei’s Tingbo He reveals the company lacks the EDA tools for 3D NPU design, delaying the LogicFolding roadmap significantly.
SMIC Yield Estimate: ~6 Million NPUs per Year
Back-of-the-envelope analysis projects roughly 6 GW of aggregate power draw if all SMIC capacity were allocated to AI chips.
Atlas 950 SuperPOD Rivals Vera Rubin-Class Hardware
One SuperCluster could let DeepSeek compete at the frontier, but current production volume limits China to roughly two such systems.
Three AI Labs Hold a Clear Advantage; Challengers Struggle to Narrow the Gap
Unless rapid improvement stalls, models from Microsoft, Meta, and other labs have yet to match the frontier level of OpenAI, Anthropic, and Google. SpaceX also hasn’t regained its prior position. The gap appears structural rather than temporary.
If Chinese Labs Stop Releasing Open Weights, the Frontier Gap Widens Further
Researchers warn that the ecosystem of local and fine-tuned models depends on continued open-weight releases from Chinese labs. If those stop — plausible as costs rise and open weights prove a poor business model — the frontier pulls further ahead of everyone running on-premise.
OpenAI and Anthropic Poised to Pull Away Dramatically from the Pack
A sharp divergence is expected soon, with the two leaders entering a period of assured dominance — and, the author warns, potentially dangerous complacency, until at least Q1 2027.
CritPt Stratifies AI Labs into Four Tiers
Using the CritPt benchmark, labs fall into clear strata: the absolute frontier, those preparing for the AI-scientist era, the agent-focused crowd, and those who simply cannot keep pace.