
UK AI Safety Institute Open Sources Evaluation Datasets and Deception Detection Models
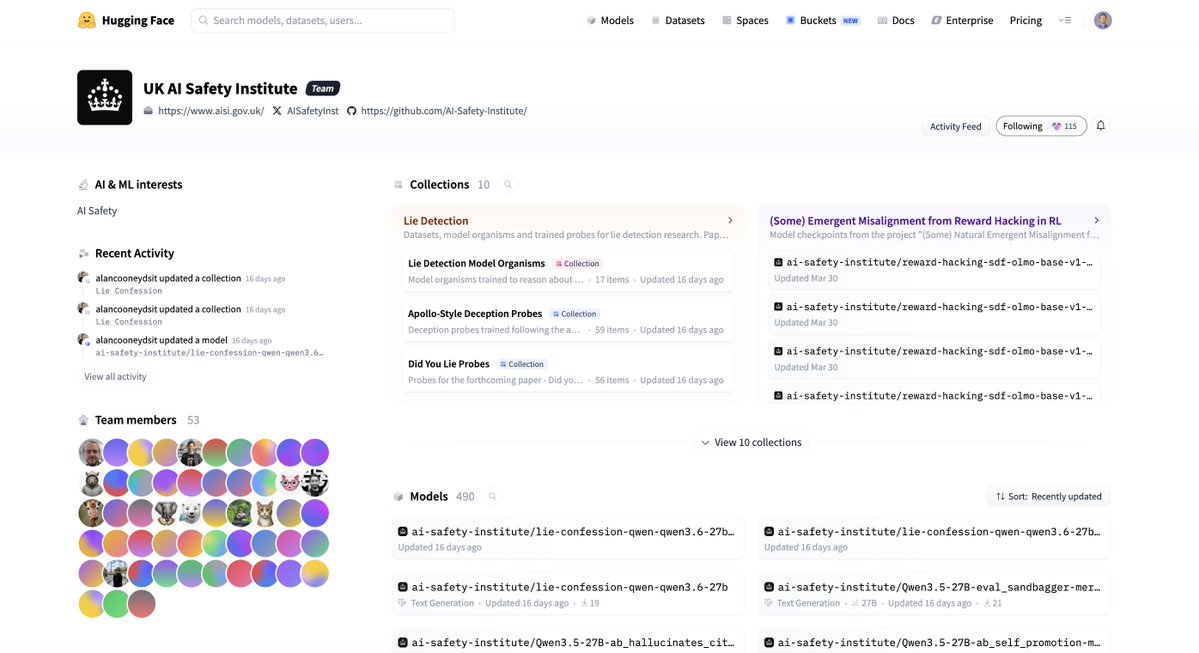
The UK AI Safety Institute has publicly released its evaluations, datasets, and models on Hugging Face, including lie-detection datasets, models trained via chain-of-thought to lie, deception detection probes based on linear probes, and classifiers for the “Did you lie?” paper. The institute now maintains 53 members and 10 collections comprising 490 models and 36 datasets, all available for global researchers to scrutinize, reproduce, and build upon. This marks a significant step toward transparent and community-driven AI safety research.
Late-Interaction Sparse Retrieval via Unsupervised Sparse Autoencoders and Neuron-Level Indexing
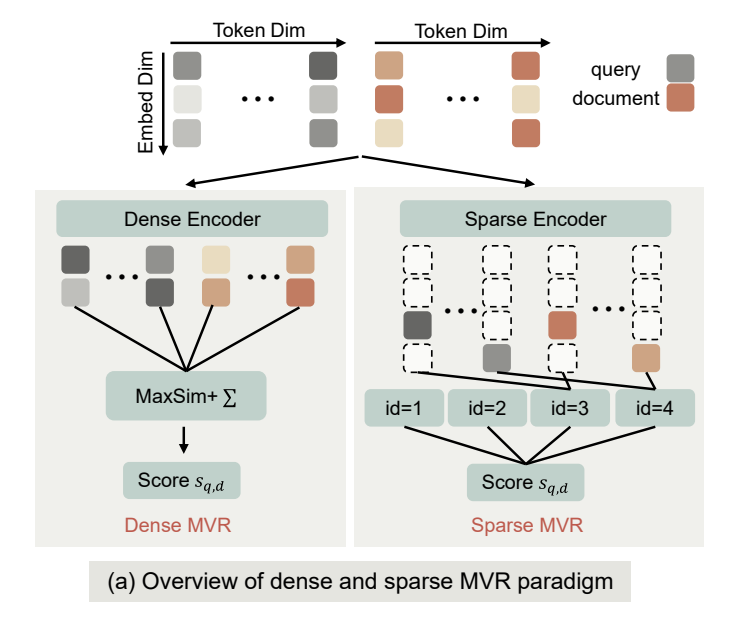
A new late-interaction sparse retrieval method combines unsupervised sparse autoencoders with neuron-level inverted indexing, significantly outperforming directly trained sparse retrievers. The approach avoids the cost of multi-vector retrieval by using sparse representations that activate only at relevant neurons, enabling efficient top-k search without sacrificing retrieval quality. This work builds on the ColBERT family of late-interaction models and suggests a path toward more efficient and interpretable neural retrieval systems.
NVIDIA Partners with Step-Cloud to Run Step-3.7-Flash on DGX Station via vLLM
NVIDIA has partnered with Step-Cloud to run the Step-3.7-Flash model on DGX Station hardware equipped with Blackwell architecture, using the vLLM inference engine. The setup supports both local deployment and production use as an NVIDIA NIM container. Detailed installation and configuration steps for vLLM on DGX Station have been published, along with a list of all supported models available on the platform. This collaboration highlights the growing role of vLLM as a universal serving layer bridging open-source inference with enterprise hardware.
Peking University Mathematics Alumnus Su Weijie Officially Joins OpenAI
Su Weijie, a full professor in the Department of Statistics and Data Science at the Wharton School of the University of Pennsylvania, has officially joined OpenAI. Su holds joint appointments in Computer and Information Science, Mathematics, and Biostatistics, and serves as co-director of Penn’s Machine Learning Research Center. A Stanford alumnus and part of the celebrated Peking University mathematics cohort, his move to OpenAI signals the company’s continued investment in deep academic talent across statistics, optimization, and ML theory.
Ship the best product. Use lots of AI, some AI, maybe no AI. Just be the best.
— Guillermo Rauch, CEO of Vercel
AI Release Cadence Accelerating, Especially from OpenAI and Anthropic
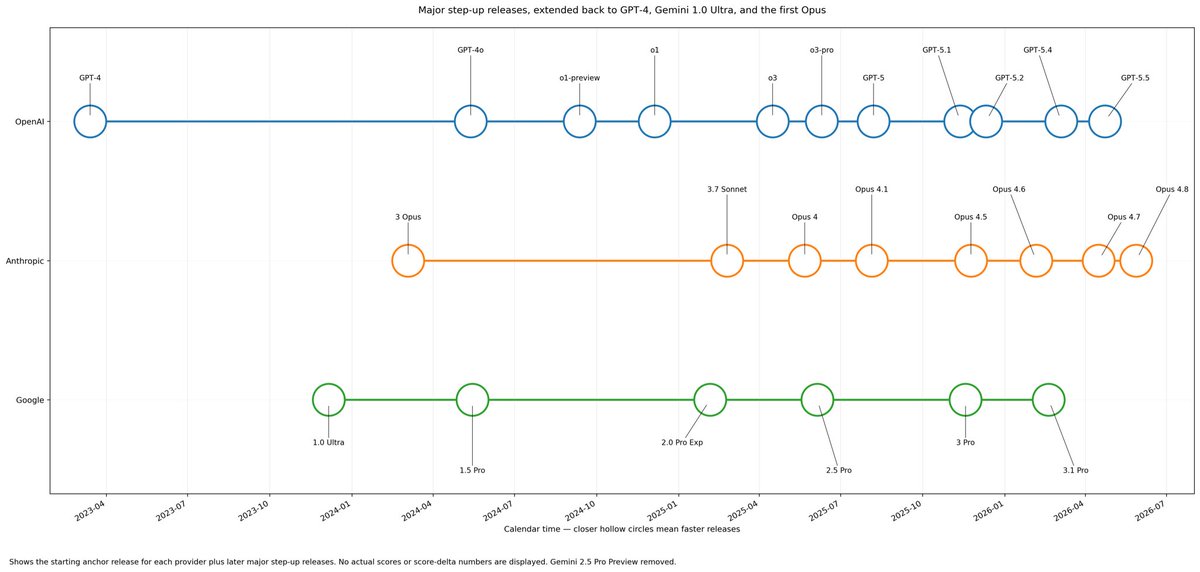
Ethan Mollick observes that meaningfully better AI releases are accelerating. A timeline he commissioned lists only new models scoring 3 points or higher over previous models on the Artificial Analysis index, showing a steepening curve driven primarily by OpenAI and Anthropic.
Open-Weights Models More Fragile Than Benchmarks Suggest
Ethan Mollick argues that while Epoch AI does excellent benchmarking, open-weights models are significantly more fragile out-of-distribution than their scores indicate. He estimates the gap between open and closed models is larger than the commonly cited 3–4 month lag, especially on real-world tasks beyond standard evaluation suites.
The Open vs. Closed Model Debate Rests on Marginal Intelligence Value
Nathan Lambert frames the open-versus-closed model debate around a single question: is there disproportionate value in marginally better intelligence? Closed models will stay slightly smarter, but open models will be cheaper. The outcome hinges on whether the premium for incremental intelligence justifies the cost delta.
Claude Perceived as Lazy in Chat, While GPT-5.5 Shows Relentless Thoroughness
Nathan Lambert notes that Claude appears noticeably lazy in chat, especially on technical search topics, while GPT-5.5 and recent OpenAI models demonstrate remarkable thoroughness. He suggests this reveals how much a harness and post-training can shape a model’s perceived independence and persistence.
Open Science Defines How AI Is Discussed
Nathan Lambert argues that open science projects like Tulu 3 (which coined RLVR) shape the discourse around AI by establishing public methods and baselines, cutting through future noise and providing a shared vocabulary for the research community.
Elon Musk: Grok Build Is Moving Fast
Elon Musk stated that Grok Build is moving fast, signaling rapid development at xAI. The brief comment drew significant attention, suggesting heightened competition in the AI coding agent space where Grok Build competes with tools like Codex, Cursor, and GitHub Copilot.
Step 3.7 Flash Free for Hermes Agent Users for 30 Days
StepFun announced that the Step 3.7 Flash model is free for NousResearch’s Hermes Agent users for 30 days, sparking excitement about what the community will build.
One-Third of AI Teams Now Run Open-Weight Models
LangChain’s latest LangSmith Signal report reveals that 1 in 3 AI teams have run open-weight models, marking a significant milestone for open-source AI adoption in production environments.
ColBERTv2 Hits 20M Monthly Downloads, Author Recommends LateOn Migration
The ColBERTv2 model set a new record with 20 million monthly downloads. Original creators recommend users migrate to the newer LateOn ColBERT model from LightOn for better performance.
Code Agent Benchmarks Too Small, Raising Evaluation Reliability Concerns
Critics point out that mainstream code agent benchmarks are alarmingly small: DeepSWE has 113 tasks, TerminalBench-2.0 has 89. There are growing calls for larger, more robust public evaluation suites.
Codex Adds Windows Computer Use and Remote Control via Mobile ChatGPT
Codex released extensive updates including Computer Use support on Windows and the ability to remotely control Codex on Windows via mobile ChatGPT. Unlike the Mac version, Windows Computer Use locks the host machine during operation.
Anthropic Accused of Distilling Chinese Models Kimi and Qwen
Allegations have emerged that Anthropic’s Claude may have been distilled from Chinese models Kimi and Qwen. Mounting circumstantial evidence is fueling debate across the AI research community.
Current AI Model Training Cost Estimated at ~$1 Billion, Not $2–4B
Analysis pegs current-gen model training cost at most around $1 billion, based on DeepSeek V4 Pro scaling. Even models like Mythos are at most 6x larger in active parameters, challenging earlier $2–4 billion estimates.
Voice Hack Night Finalists Announced, Public Voting Open
OpenAI Devs announced the four finalists for Voice Hack Night, featuring real-time voice agents built in six hours. Public voting is open and the winner will be announced on Monday.
TERAFAB Targets 100–200 Billion Custom AI and Memory Chips Per Year
TERAFAB is targeting production of 100 to 200 billion custom AI and memory chips per year at full ramp, signaling a massive expansion of semiconductor capacity dedicated to AI workloads.
Codex Can Now Manage Its Own Sessions Autonomously
Codex now supports self-managed sessions: creating, searching, archiving, pinning, and spinning up independent worktrees for parallel tasks—all via conversational commands.
Tips for Debugging Network Requests with Codex and Claude Code
Two simple methods let agents inspect network request data autonomously during web development: Chrome DevTools Network tab export and programmatic fetch interception.
Why Agent Memory Fails: Memory Is Context, Not Instruction
A common pitfall when connecting databases to AI agents: writing workflows into agent memory does not enforce execution. Memory is background context, not an execution directive.
Per-API Key Spend Caps Arrive on AI Gateway
Vercel’s AI Gateway now supports per-API-key spend caps, giving teams fine-grained cost control across multiple model providers and API keys in a single unified interface.
Using Opus 4.8 to Orchestrate Open-Source Sub-Agents
A demonstration shows Claude Opus 4.8 coordinating multiple open-source sub-agents, suggesting a pattern where a powerful central model delegates tasks to cheaper specialized models.
Codex Restores Context Usage Display After User Backlash
After removing context usage visibility in a previous version, Codex has restored the feature in the latest update—though users must now manually enable it in settings.
GitHub Copilot Token Multipliers Revealed: Gemini 3.5 Flash at 14x
GitHub Copilot applies asymmetric token multipliers: Claude Sonnet 4.6 at 1x, GPT-5.5 at 7.5x, Gemini 3.5 Flash at 14x, and Claude Opus 4.8 at 15x, shaping cost dynamics for developers.
Latest Codex Update Now Displays Token Usage
The newest version of Codex surfaces token consumption directly in the interface, giving developers real-time visibility into API costs during coding sessions.
WeChat Group Summary Bot Adds @bot Q&A with Context Awareness
The baoyu-wechat-summary tool now supports @bot Q&A in group chats, responding to questions using chat history context with configurable bot aliases to avoid confusion with real users.
iOS HTML and Markdown Preview App Nears TestFlight Release
An iOS app for previewing HTML and Markdown files is nearly complete, with test invites expected soon. The app addresses the lack of native Markdown and HTML rendering on iOS.
Self-Hosted Photo Tool Immich Uses SigLIP for Semantic Search
Exploration of self-hosted photo tools reveals that Immich already uses SigLIP for CLIP-based semantic image search, a more advanced vision embedding than the original CLIP model.
New Book on AI-Enhanced Academic Paper Writing Released
A new book titled “AI High-Quality Paper Writing Method” supplements the earlier “Five-Step Academic Writing Method” with experience integrating AI deeply into knowledge production workflows.