Meta Unveils Brain2Qwerty v2: Non-Invasive BCI Decodes Sentences in Real Time
Meta published the Brain2Qwerty v1 paper in Nature Neuroscience and released v2 on the same day. V2 directly decodes sentences from raw EEG signals with 61% average word accuracy.
Building on Brain2Qwerty v1 published today in Nature Neuroscience, Meta's AI research team has simultaneously released Brain2Qwerty v2, which represents a significant leap in non-invasive brain-computer interface technology. The v2 system is the highest-performing end-to-end pipeline capable of real-time sentence decoding from raw brain activity, achieving an average word accuracy of 61% across diverse test subjects. Unlike prior approaches that required invasive implants or relied on preprocessed neural features, v2 operates directly on raw EEG signals. This breakthrough brings practical non-invasive BCI substantially closer to real-world accessibility, with potential applications in assistive communication, neurorehabilitation, and human-computer interaction.
The dual release strategy — publishing the foundational v1 in a top-tier journal while simultaneously shipping the more advanced v2 — reflects a broader trend among AI labs of compressing research-to-deployment timelines. The open publication in Nature Neuroscience lends academic credibility while v2's immediate availability signals production-readiness. Researchers outside Meta can now benchmark against the v1 architecture while developers and early adopters can begin experimenting with the higher-performance v2 pipeline.

Claude Models Land on Microsoft Foundry: Opus 4.8 and Haiku 4.5 Now on Azure
Claude Opus 4.8 and Claude Haiku 4.5 are now available via the Messages API on Microsoft Foundry, hosted on Azure. The integration supports prompt caching, extended thinking, and the full Claude capabilities suite, giving enterprise customers a streamlined path to deploy Anthropic's frontier models within their existing Microsoft cloud infrastructure.
The partnership marks a significant expansion of Claude's enterprise footprint, as Microsoft Foundry provides governance, compliance, and security tooling familiar to large organizations. For Anthropic, this represents distribution leverage comparable to OpenAI's deep Azure integration.
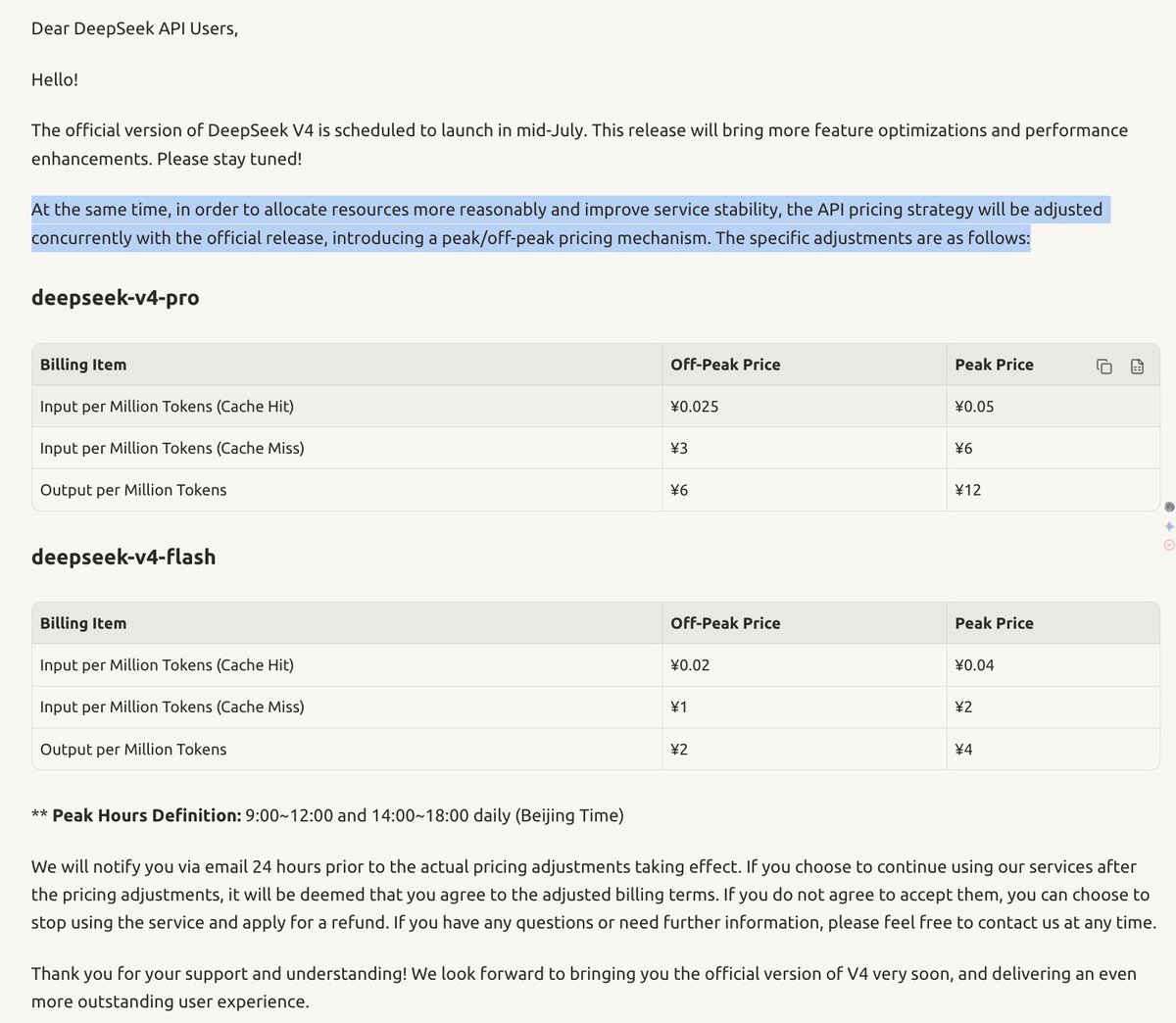
DeepSeek V4 Official Release in Mid-July with Peak-Hour Pricing
According to prominent AI commentator teortaxesTex, the official version of DeepSeek V4 will be released in mid-July — importantly distinct from the "preview of V4" that has been available for over two months. The full release introduces a novel peak-hour pricing mechanism that doubles the base rate during high-demand periods, while baseline pricing remains unchanged.
This pricing innovation addresses the capacity-planning challenge facing all frontier model providers: demand spikes during business hours can degrade latency for everyone. By incentivizing off-peak usage through transparent tiered pricing, DeepSeek could establish a model for economically sustainable API access at scale.

Cursor Launches iOS App with Cloud Agents and Remote Desktop Control
Cursor for iOS enables developers to launch always-on cloud agents or remotely control agents running on their desktop, effectively extending the AI-powered coding environment to mobile devices. Composer 2.5 is offered at a 75% discount through July 5, timed with the launch to drive adoption.
The move positions Cursor as an ambient coding platform rather than a desktop-bound IDE — a strategic bet that AI-assisted development will increasingly happen across form factors. Remote desktop control also addresses the gap between cloud agent convenience and the need for local development environments.

NVIDIA and Palantir Partner: Nemotron Models Enter Air-Gapped Environments
NVIDIA has partnered with Palantir Technologies to bring Nemotron open models into secure, air-gapped environments for U.S. government agencies and critical infrastructure operators. The joint solution enables teams to train on their own data and run models on their own infrastructure while retaining full data sovereignty.
This deployment model addresses the fundamental tension between frontier AI capability and the security requirements of defense and intelligence communities — where cloud-based inference is often prohibited. The open-weight nature of Nemotron allows full inspection and customization without external API dependencies.

Meituan Unveils V4-Class Owl Alpha Model Trained on Over 50,000 AI ASICs
Meituan, primarily known as a Chinese food delivery and services platform, has quietly entered the frontier model race with Owl Alpha — a V4-scale model pre-trained on more than 50,000 custom AI ASIC supercomputing nodes. The model features updated DSA architecture and N-gram embeddings. Analysts note the hardware is notably not Huawei Ascend-based, raising questions about what custom silicon Meituan has developed or procured.
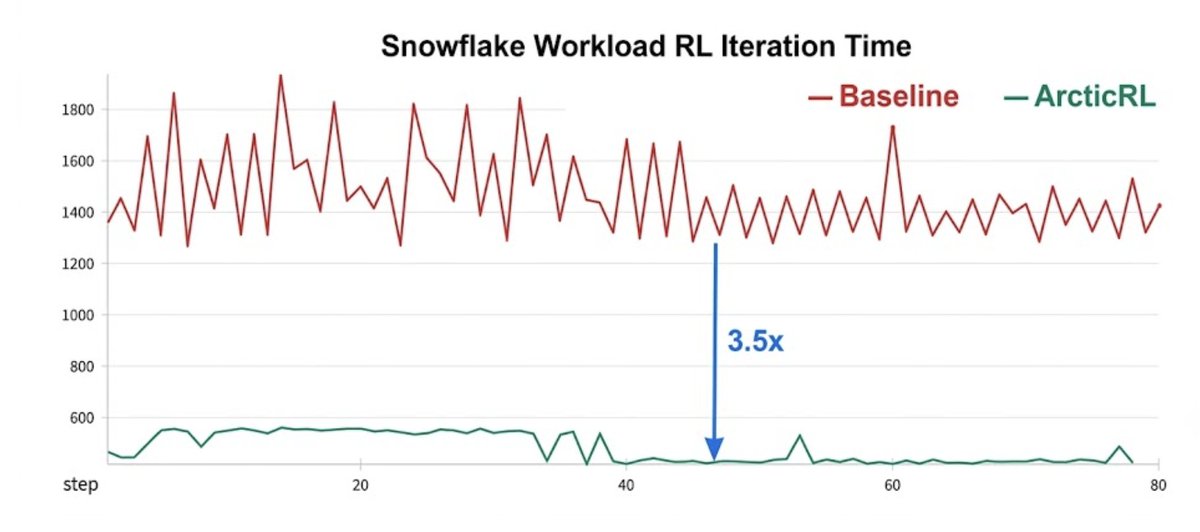
Snowflake Releases Arctic RL: Unified Reinforcement Learning Backend Boosts GPU Performance
Snowflake AI Research has open-sourced Arctic RL, a unified reinforcement learning backend designed for enterprise post-training optimization. The framework integrates with VeRL and SkyRL out of the box, and supports the ZoRRo feature via a single configuration flag — no code changes required. The project targets significant GPU performance improvements for large-scale RL workloads, making enterprise-grade RL accessible to teams beyond the hyperscalers.

Runway Launches Seed Audio 1.0: Text-to-Speech, Sound Effects, and Music in One Model
Runway has released Seed Audio 1.0, available to all paid plan subscribers. The model generates up to 120 seconds of dynamic speech, sound design, and music from simple text prompts — unifying three traditionally separate audio generation tasks into a single interface. This positions Runway as an increasingly multimodal creative platform, expanding beyond its video-generation roots into professional-grade audio production.
I love optimizing machines. It's like a beautiful puzzle that also achieves true usefulness.
Elon Musk

LlamaIndex Releases Retrieval Harness: Semantic Search Meets Server-Side Grep
LlamaIndex launched the Retrieval Harness in LlamaParse Index, combining semantic search, server-side grep, and file-level navigation into a single agent reasoning loop. The insight is that neither semantic search nor brute-force grep alone is sufficient for agentic retrieval tasks — agents need both modalities and the ability to navigate between them.
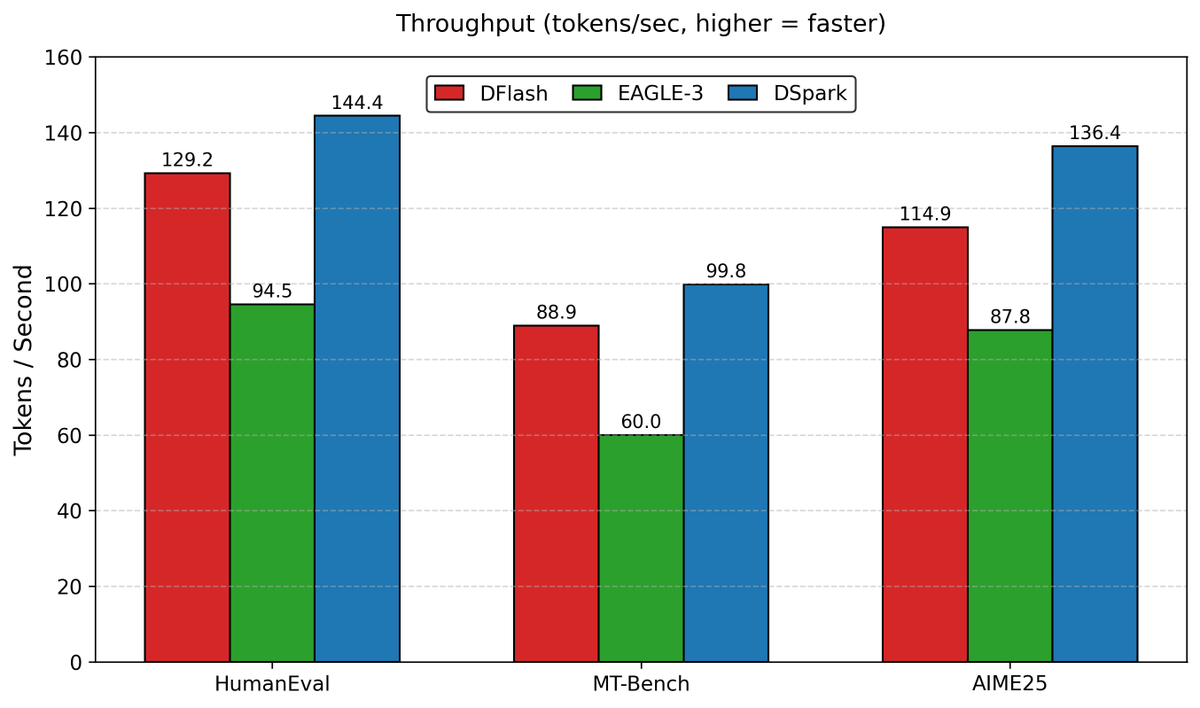
DeepSeek DSpark Speculative Decoding: 20% Higher Acceptance, 127 tok/s on Single GPU
Analysis by teortaxesTex shows DeepSeek's DSpark speculative decoding achieves a 20% higher acceptance length and 14% throughput improvement over DFlash, averaging 127 tok/s versus 111 tok/s for DFlash and 81 tok/s for EAGLE-3. The lightweight architecture with early stopping proves clearly superior for single-GPU inference scenarios.

Vercel AI Gateway Adds Voice Agents: Real-Time Speech, Recognition and Transcription
Vercel AI Gateway has introduced voice agent capabilities, supporting real-time speech via useRealtime, speech synthesis via generateSpeech, and transcription via transcribe — all integrated into AI SDK 7. The unified gateway approach simplifies voice agent deployment across multiple model providers.

OpenAI Codex Shortcut Upgrade Coming July 15
OpenAI announced an upcoming upgrade to Codex shortcuts, set for July 15. While details remain scarce, the teaser suggests improvements to the developer productivity tooling within the Codex ecosystem.

Spotify VP of Engineering: 73% of PRs AI-Assisted, 4,500 Deployments Daily
Spotify VP of Engineering Niklas Gustavsson revealed that 73% of the company's pull requests are now AI-assisted, while the engineering organization ships 4,500 production deployments per day. In conversation with Anthropic's Boris, Gustavsson described how AI tooling has become embedded across Spotify's development workflow.
SpaceXAI Voice API Now on Vercel AI Gateway
SpaceXAI's advanced voice API has been integrated into the Vercel AI Gateway, providing developers with direct access to state-of-the-art voice models through the unified Vercel platform.

Replit Launches Desktop App for Windows and Mac
Replit Desktop brings the collaborative coding platform to native desktop applications, supporting both Windows and Mac. The app provides a seamless multitasking experience for developers who prefer desktop-native workflows.
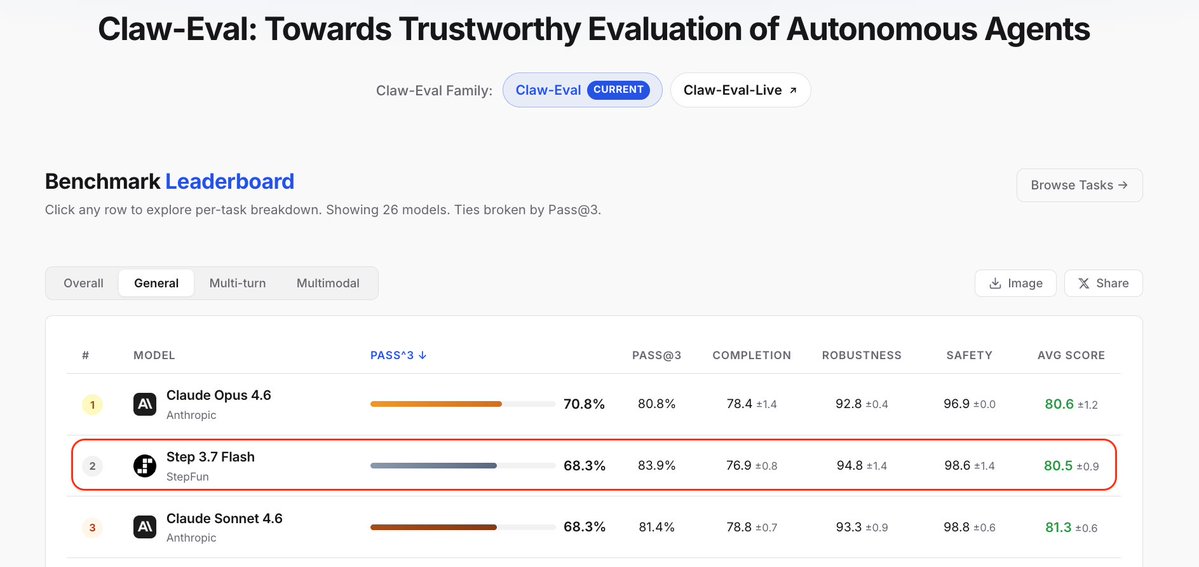
Step 3.7 Flash Ranks Second in Claw-Eval General Agent Benchmark
StepFun's Step 3.7 Flash ranked second on the Claw-Eval autonomous agent benchmark, behind Claude Opus 4.6, demonstrating strong multi-step execution and robustness in long-horizon tasks.
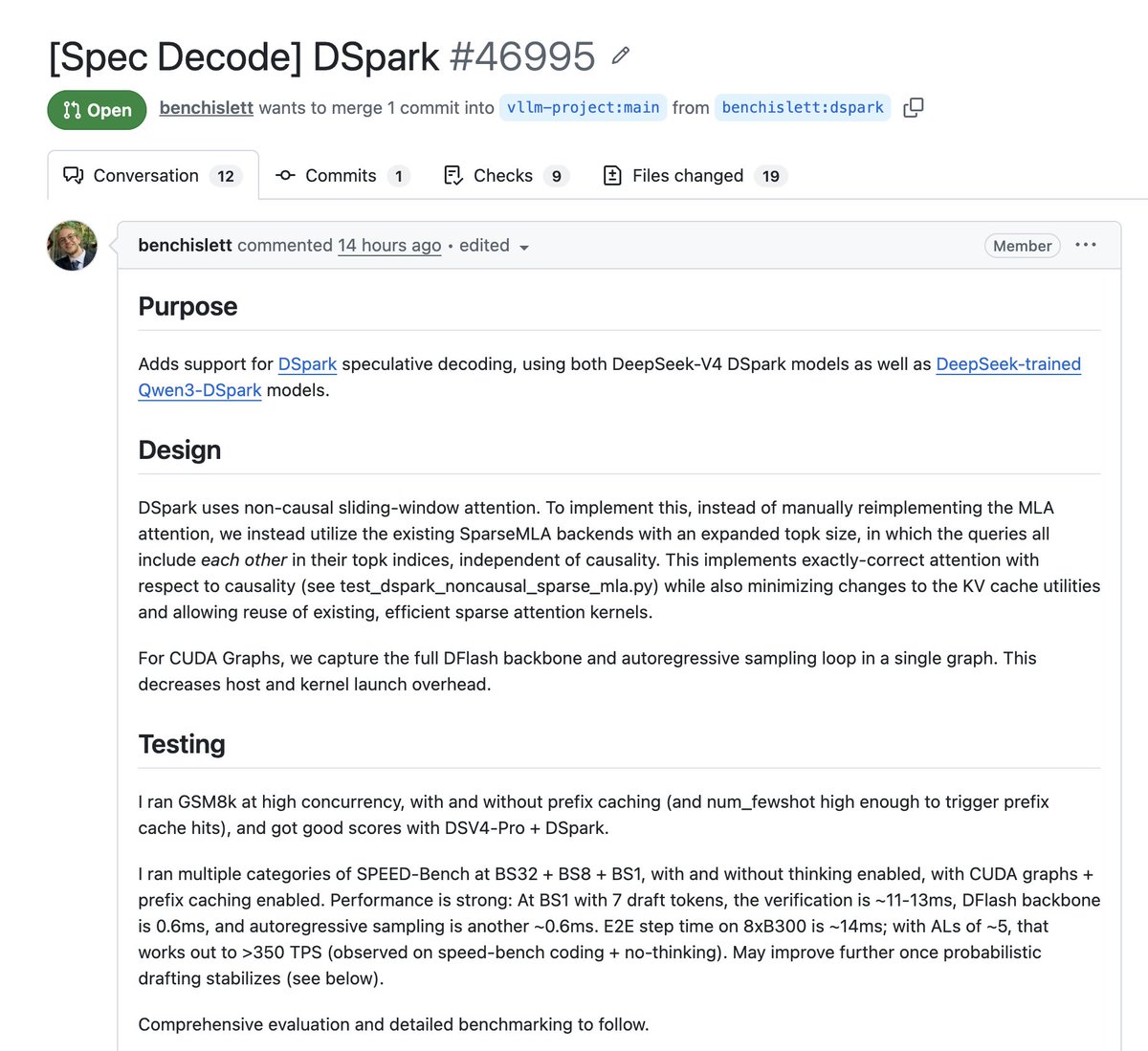
vLLM Integrates DeepSeek DSpark Speculative Decoding for Faster Inference
The vLLM community is working to integrate DeepSeek's DSpark spec decode algorithm via PR #46995, which supports both DeepSeek-V4 DSpark and Qwen3-DSpark models using non-causal sliding window attention to improve inference throughput and memory efficiency.
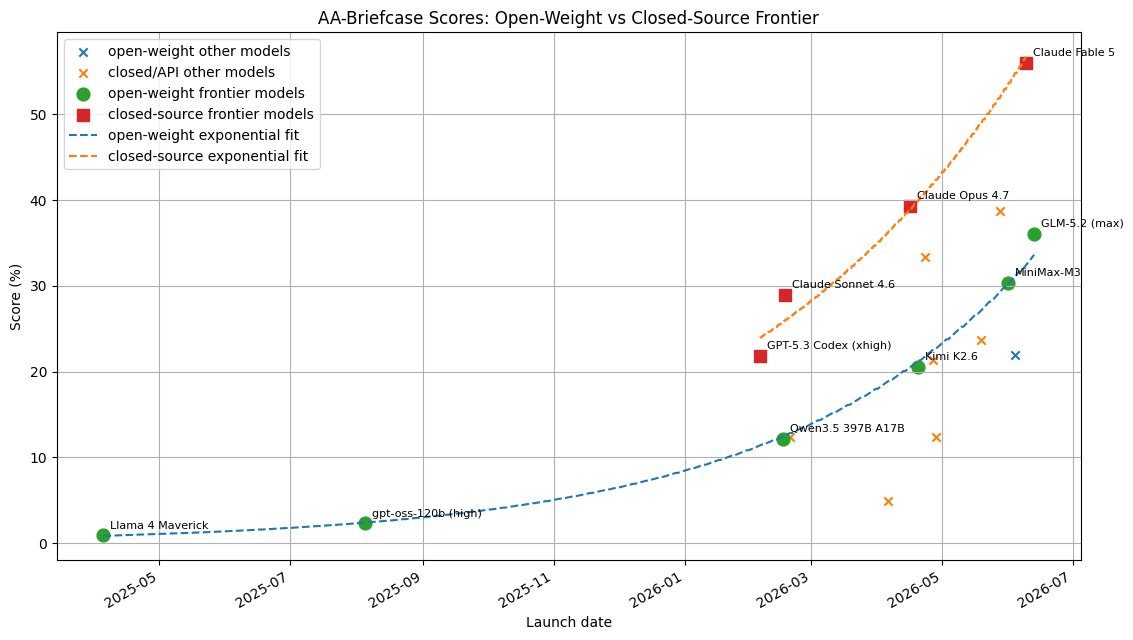
AA-Briefcase Benchmark: Rapid AI Gains on Multi-Week Consulting Tasks, but Open-Source Lags
Artificial Analysis released AA-Briefcase, a private benchmark that simulates complex multi-week consulting engagements — requiring AI models to deliver spreadsheets, presentations, and memos. Recent models show rapid improvement, but the gap between closed-source and open-weight models remains significant on these extended autonomous tasks.

PixVerse Seedance 2.0 Delivers Native 4K AI Video for Cinematic Motion
PixVerse demonstrated Seedance 2.0 running natively in 4K resolution, optimized for cinematic character motion and urban action scenes generated from text prompts.
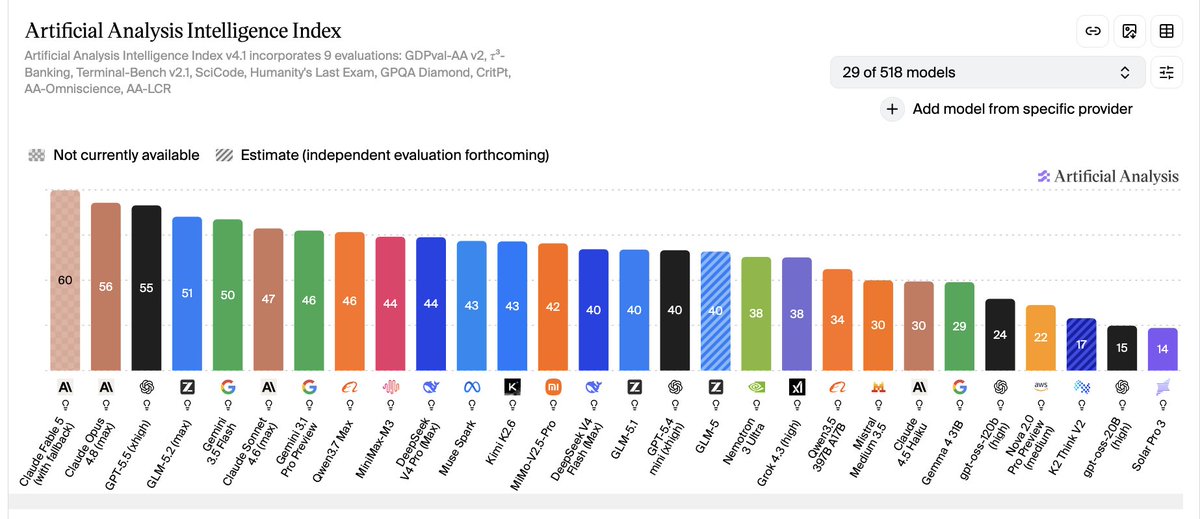
GLM 5.2 Improves by 11 Points, Open-Source Closing in on Frontier
Analysis by teortaxesTex shows GLM 5.2 improved 11 points over GLM 5.1. At this trajectory, a comparable magnitude jump would place V4 on par with Opus 4.8 or GPT-5.5-xhigh — suggesting the open-source frontier may soon converge with closed models.
Fusion Harness: Main + Sidekick Model Architecture Cuts LLM Costs
Graham Neubig introduced Fusion Harness, a hybrid architecture where an inexpensive sidekick model handles simple tasks while a more capable main model tackles complex reasoning. By implementing context control and routing inexpensive tokens to the sidekick, the approach significantly reduces overall LLM spend. A 200-line example implementation is available for the OpenHands SDK.
Next.js TurboPack: Filesystem Caching Pays Off for Agent-Driven Builds
Guillermo Rauch highlighted major performance and memory improvements in Next.js TurboPack, crediting the filesystem cache strategy that proves especially effective in an era of AI agents repeatedly triggering builds.