DeepSeek V4即将到来:Pro和Flash版本曝光,仍按token计费?
内部消息显示DeepSeek V4的Pro和Flash版本已接近发布,且保持按Token计费模式,但仍需验证。
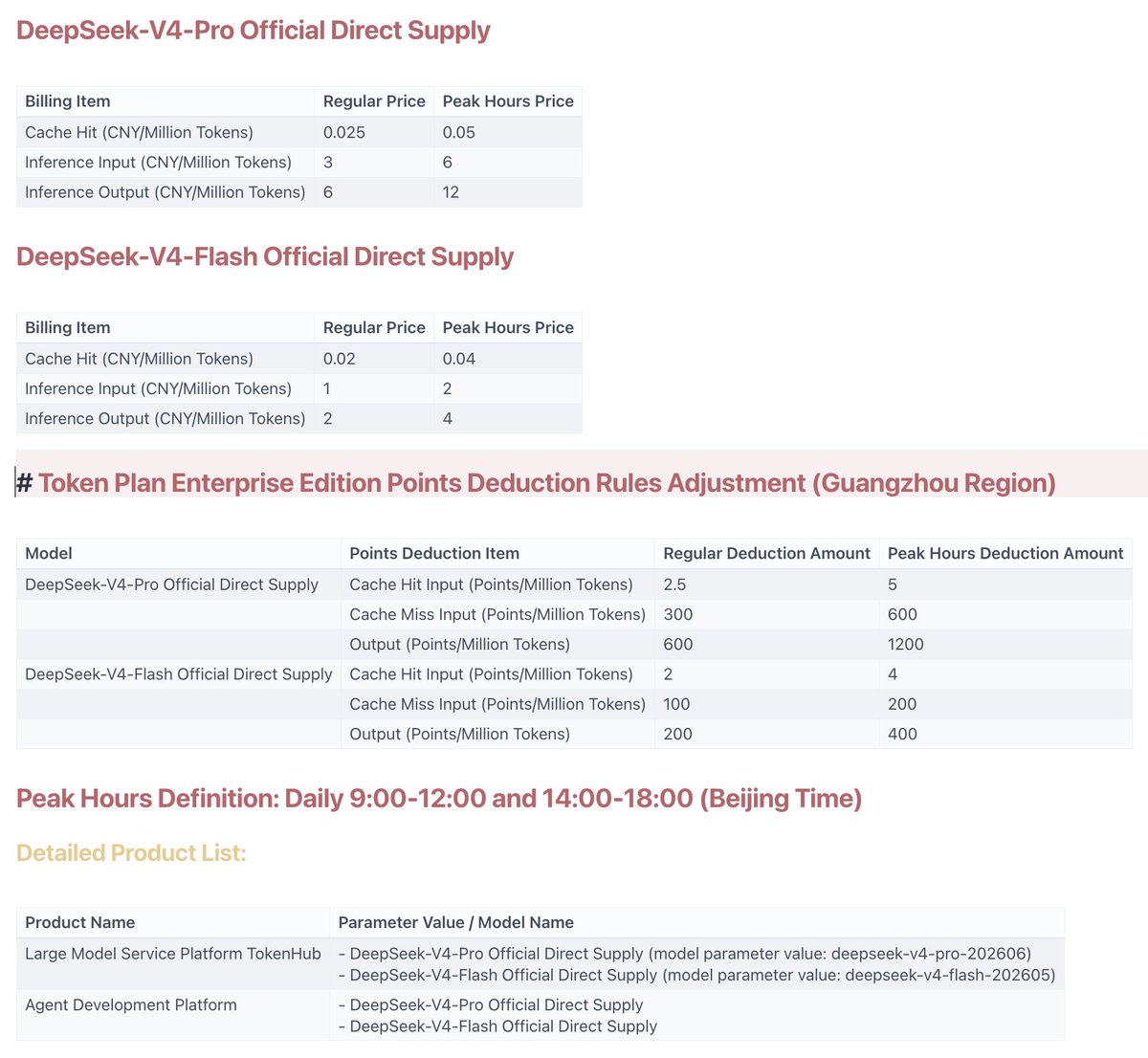
来自社区的爆料显示,DeepSeek的下一代模型V4已在路上。曝光的两个版本分别为deepseek-v4-pro-202606和deepseek-v4-flash-202605,这意味着Pro和Flash双版本策略将在V4代继续沿用。更引人关注的是,消息称V4仍将采用按token计费的模式,而非业界此前猜测的订阅制或混合定价方案。如果属实,这将是DeepSeek继续通过高性价比策略蚕食市场份额的重要信号。与OpenAI的Opus系列和Anthropic的Fable系列相比,DeepSeek的低价路线已在V3代积累了庞大的开发者基础,V4若能延续这一优势,将进一步重塑大模型API市场的竞争格局。
Sakana AI在ICML2026发表球形黑盒优化器研究
Sakana AI最新研究"Bridging Spherical Black-Box Optimizers"被ICML2026接收。该研究旨在连接不同的球形黑盒优化算法,为高维空间的参数优化提供新思路。黑盒优化是大模型训练和超参数调优中的关键技术之一,这项工作的突破可能影响未来的训练效率。论文将在7月6日至11日于首尔举行的ICML会议上进行展示。
AI助力癌症免疫治疗:从一万肿瘤样本中学习
Yann LeCun转发了Eric Topol团队的研究成果。该研究使用AI从10,000个肿瘤样本的转录组数据中学习,覆盖33种癌症类型,旨在改善免疫治疗的效果预测。这项工作展示了AI在精准医疗领域的巨大潜力——通过从海量基因表达数据中提取模式,AI可以帮助医生更好地判断哪些患者将受益于免疫疗法。此前类似的研究通常局限于单一癌种,此次跨癌种的系统性分析标志着该领域的重要进步。
原始的缩放定律论文由于一个bug导致结论出错,可能使业界在过度训练不足的模型上浪费了巨大算力——而且那时候还没开始考虑推理成本。
蒸馏Claude Fable 5推理轨迹至Qwen3-4B,实现100%自洽性
研究团队从Claude Fable 5中蒸馏了230万条推理轨迹到Qwen3-4B模型,在512个样本下达到100%自洽性,输出0.00比特错误。这一成果表明,通过知识蒸馏,较小模型也可以继承前沿大模型的推理能力,大幅降低部署成本。
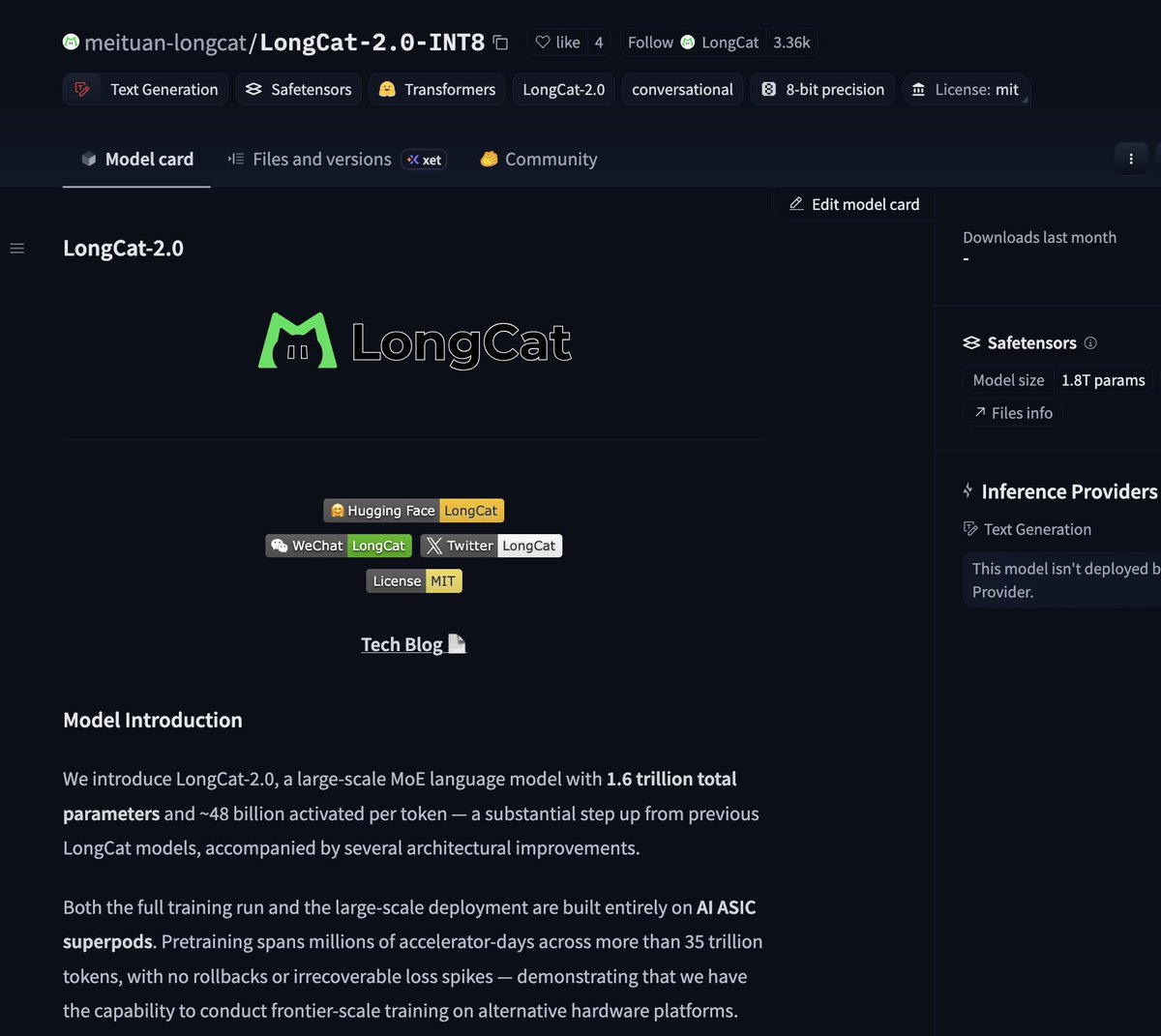
LongCat权重发布:最大规模非西方芯片预训练模型
LongCat模型权重已在Hugging Face上发布,这是已知的最大规模在非西方芯片上完成预训练的模型。该发布有助于评估华为芯片栈在大规模训练中的实际表现,也为非英伟达算力生态提供了重要参照。在出口管制日趋收紧的背景下,LongCat的出现是算力多元化的一个标志性进展。

Tau Law V2:华为LogicFolding技术提升高端AI计算能效
分析指出,华为的LogicFolding技术可以在同性能水平下提升高端AI芯片的能效上限,同时开辟新的低温高效运行层级。当前910C架构产品面临全面淘汰的风险,新技术将显著改写国产芯片的竞争力版图。

Seedance 2.0开源模型发布:4K视频生成能力全面开放
Higgsfield AI展示了Seedance 2.0生成的4K视频,并开放了完整开源项目和提示词。该模型在视频生成质量和分辨率上较前代有显著提升,且开源策略使得开发者和创作者可以自由部署和定制。这标志着视频生成领域的开源生态正加速追赶闭源商业模型。
如果模型本身就是路由器:智能委托给更便宜的模型
Ethan Mollick提出了一种未来AI架构的设想:由前沿大模型充当智能路由器,自行判断任务复杂度并将简单任务委托给更便宜的小模型处理。这种模式可以实现高效分工——让最聪明的AI做规划,让专用小模型做执行,大幅降低推理成本。他同时指出,人们低估了当前前沿模型自主委托任务的能力,这种能力正在快速提升。这一思路与业界正在探索的MoE路由和模型级联策略不谋而合。
Llama Index推出新一代检索工具,专为Agent设计
Llama Index的Jerry Liu发布了一款全面检索工具Retrieval Harness,旨在为2026年的现代Agent检索提供持久化数据支持。该工具提供了一种标准化的数据计算和评估框架,解决了Agent在复杂任务中面临的检索质量不可控问题。随着Agent应用从原型走向生产,检索的稳定性和可复现性正成为关键工程挑战。
AI公司获取算力比开发前沿模型更容易
teortaxesTex总结了过去两年的观察:从一家无算力的AI公司成长为拥有大量全球算力的公司,比从拥有算力但无前沿模型跨到两者兼备要容易得多。这反映出当前AI行业的深层矛盾——算力可以通过资本和基础设施建设获取,但真正的前沿模型能力仍然是极度稀缺的。市场上算力供需关系和模型能力的分布正在经历结构性重塑。
Diffusers发布新版本,新增Ideogram4等图像视频管线
新版本包含Ideogram4、MotifVideo等多个新图像和视频pipeline,图像生成与视频生成工具链进一步统一。
GLM-5.2现可在Claude Code中通过Hugging Face推理提供者使用
ZAI官方宣布GLM-5.2已集成至Claude Code,开源模型在开发者工具链中的接入方式持续改善。
Sakana AI将在ICML2026展示11篇论文,涵盖多智能体协调
Sakana AI团队携11篇论文赴首尔ICML2026,主题包括多智能体协调,展示了日本AI实验室在基础研究方面的持续产出。
GLM 5.2成本远低于Opus和Fable,性价比突出
Thoughtful Lab比较称,GLM 5.2比Opus 4.8便宜5倍,比Fable 5便宜11倍,但在PostTrainBench上排名第一。
vLLM语义路由:开源路由系统提升模型调度效率
Clement Delangue推广vLLM项目的语义路由系统,推动开源路由与模型调度的进步。
Replit上Spellbook应用3年逼近1亿美元ARR
Spellbook应用利用Replit内置认证,在3年内有望突破1亿美元年化收入,展示了AI开发平台孵化商业应用的能力。
Dreamina Seedance 2.5即将登陆剪映,支持50种多模态参考
CapCut官方宣布Dreamina Seedance 2.5将在剪映上线,提供无缝生成和编辑,最多支持50个多模态参考输入。
Luma Labs Ray3.2:用AI直接生成你的创意视觉
Luma Labs转发用户演示,展示Ray3.2如何通过AI将设计创意直接渲染为视觉成果。

Blackwell带宽提升使GLM 5.2达300tps,期望150tps成新常态
Blackwell增加的内存和通信带宽,加上DeepSeek的megamoe算子,使得GLM 5.2实现300 tokens/s不再困难。

Moonshot实验室:专注于突破性架构,系统集成非重点
Moonshot实验室负责人表示重心在突破性架构而非系统工程集成,被认为是充分吸取DeepSeek经验的机构。
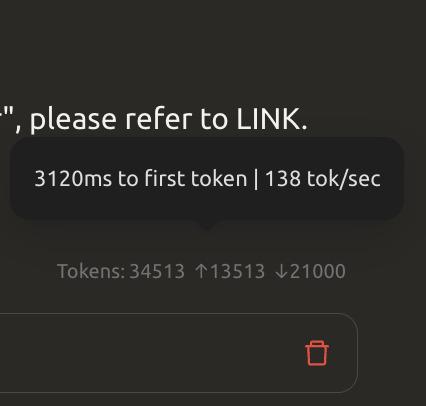
V4翻译中文PDF创纪录:138 tokens/s,推理时间61秒
V4-flash以138 tokens/s完成翻译,推理时间仅61.1秒;V4-pro质量更优,速度84 tokens/s。

中国AI研究从未落后太多:百度发布首个缩放定律论文
teortaxesTex认为人们高估了通过间谍活动获取前沿算法的重要性,百度早已发布首个缩放定律论文。
MiniMax入选开放模型生态,生态系统持续向好
MiniMax官方表示很高兴被纳入开放模型生态系统,该生态正在不断改善。
我们正告别旧代码时代:AI让编程从手工艺变为商品
Ethan Mollick比喻称,AI使编程商品化,不再需要委托代码工匠手工打造程序。
精致的思维工具被简陋CLI碾压,后者提供商品化思考
Swyx感叹十年打造的漂亮思维工具被低对比度的CLI彻底打败,因为后者提供了开箱即用的思考能力。
前沿实验室降本秘诀?Giffmana调侃:降低视觉分辨率永远有效
研究员独立日宅家研读Nemotron和Arcee Trinity技术报告
如果产品没有即时反馈功能,用户会用Claude替代你
研究员robertskmiles表示,如果软件产品不能在几分钟内实现用户的功能请求,他会忍不住用Claude替代整个产品。