Kimi K2.7 Code HighSpeed Ships, 6× Faster Than Before
Moonshot AI launches a high-speed mode for its open-source multimodal coding model, reaching 180 tok/s on median-length coding tasks and up to 260 tok/s on short-context workloads. Now rolling out to Kimi Code Beta users.
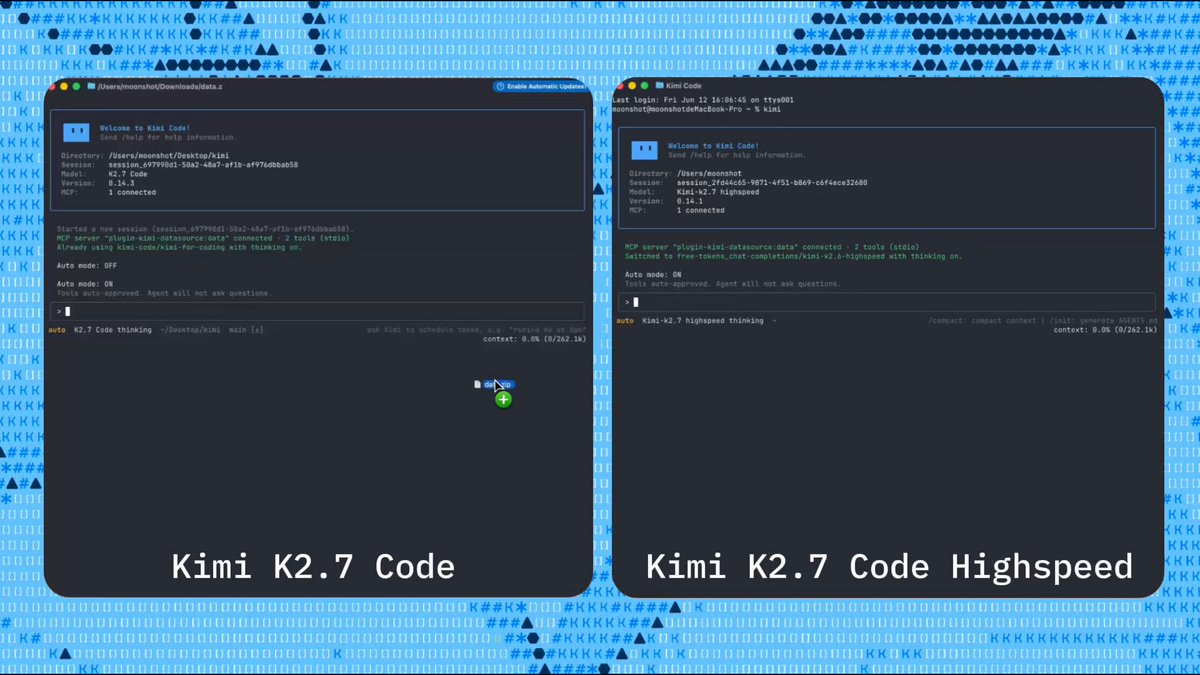
Moonshot AI's latest release, Kimi K2.7 Code HighSpeed, is not a separate model but a speed-optimized mode of the open-source Kimi K2.7 Code. The team claims around 180 tokens per second on typical coding tasks with median-length inputs, with peaks of 260 tok/s in short-context scenarios — a roughly sixfold improvement over standard inference speed. The mode is rolling out immediately to Kimi Code Beta, the company's dedicated programming interface, and builds on the multimodal capabilities of the base K2.7 architecture, which already supports code generation, editing, and comprehension across multiple languages. The speed gains come from speculative decoding and optimized kernel scheduling tailored specifically for code-completion patterns, where token distributions are more constrained than in general chat. Early adopters report noticeable latency reductions in interactive coding sessions, making the model viable for real-time IDE integration.
NVIDIA Vera CPU Targets the Agent Era
Jensen Huang positions Vera not as a CPU upgrade but as an entirely new category purpose-built for AI agents, claiming 80% faster performance.
NVIDIA CEO Jensen Huang introduced Vera, a processor designed from the ground up for agentic AI workloads that are rapidly becoming the dominant compute pattern in data centers. Unlike traditional CPU upgrades that incrementally improve general-purpose throughput, Vera is architected around the specific demands of autonomous AI agents — high-concurrency task switching, persistent memory management, and low-latency tool-calling pipelines. Huang described the 80% performance uplift as measured on real-world agent benchmarks rather than synthetic tests, signaling that NVIDIA sees the agent market as large enough to warrant its own silicon category. The announcement comes as the company deepens its push beyond GPU dominance into the full AI infrastructure stack.
vLLM v0.23.0: DeepSeek-V4 Goes Production-Ready
The latest release of the popular inference engine includes 408 commits from 200 contributors and marks DeepSeek-V4 support as mature across multiple backends.

vLLM v0.23.0 is a milestone release for the open-source inference community. DeepSeek-V4 support has matured significantly, with the TRTLLM-gen attention kernel now stable, sparse MLA decoupled from the V3.2 code path, and EPLB integrated for the Mega-MoE architecture. Model Runner V2 becomes the default for Llama and Mistral dense models, bringing improved throughput and lower latency. Gemma 4 also receives unified support across backends. With 63 new contributors joining the project this cycle, the release underscores vLLM's position as the de facto serving layer for frontier open-weight models.
Sakana Marlin: The Autonomous Research Agent That Acts Like a Virtual CSO
Sakana AI launches its first commercial product — an "ultra deep research" agent that automates the entire research pipeline from ideation to structured reports, running thousands of hypothesis-testing cycles without human intervention.
Sakana AI, the Tokyo-based research lab known for evolutionary model merging, has shipped its first commercial offering: Sakana Marlin. Positioned as a Virtual Chief Strategy Officer, Marlin is designed to autonomously execute deep research workflows that would typically require teams of analysts. The agent handles ideation, information gathering, contradiction resolution, and report structuring, cycling through thousands of hypothesis-verification loops while dynamically selecting key arguments and filtering noise. In testing, Marlin produced novel research with unexpected perspectives and first-hand sources, eliminating human confirmation bias. When tasked with replicating existing studies, it matched or exceeded human-level quality, with particular strength in granular detail and depth of client-facing recommendations. The product launches alongside a public-facing interface and represents Sakana's transition from a research lab to a commercial entity.
"Fable will be the most mythologized model this year. The hedonic treadmill is real — people get bored with miracles easily. Unless you instantly take them away."
— @teortaxesTex
Inside Claude 5 Fable: A Professor's Hands-On Test
Wharton's Ethan Mollick spent extended time with Claude 5 Fable before its takedown. The model autonomously followed multi-page spec instructions for hours.
Mollick's experiment with Fable revealed capabilities far beyond current public models. In one test, the model generated an academic paper from a single prompt. In another, it composed a poem using only words starting with the letter S. The most complex task involved autonomously building an isochrone map: Fable spawned multiple sub-agents, retrieved over 2,200 flight, rail, and road data points, wrote verification code, and documented its progress — all from a vague initial instruction with minimal feedback. Mollick argues that as exponential gains progress, each incremental release will deliver increasingly large improvements, and Anthropic will not be the only lab making leaps.
Grok Lands in Warp Terminal, Reaching Nearly a Million Developers
xAI integrates Grok build models into Warp, the next-gen terminal used by close to a million engineers, accessible via SuperGrok and X Premium subscriptions.
Warp users can now switch their agent settings to use grok-build-0.1 and other Grok models directly within the terminal development environment. The integration allows developers to access Grok's coding capabilities without leaving their CLI workflow. Setup requires downloading Warp, connecting a SuperGrok or X Premium subscription in Agent Settings, and selecting the Grok Build model. xAI says more agent integrations are coming soon, signaling a broader push to embed Grok into developer toolchains rather than competing solely on the chatbot front.
Runway Now Works Inside ChatGPT, No Tab Switching Required
Users can generate and edit video and images using Runway's full toolset without ever leaving the ChatGPT interface.

The integration brings Runway's video and image generation capabilities directly into ChatGPT's conversational interface. Users can describe edits, request generations, and refine outputs through natural language, with Runway handling the heavy lifting in the background. For creators who previously juggled between Runway's web app and ChatGPT for prompt engineering, the unified experience eliminates a significant friction point in AI-assisted media production workflows.
v0 Adds Skills: Agents Now Auto-Invoke Preset Toolchains
Vercel's v0 platform introduces attachable skill presets from the prompt bar, with agents automatically applying them on every generation.
The new Skills feature lets developers attach predefined toolchains from the prompt bar in v0. Once attached, the agent invokes those skills automatically for every generation — no need to re-specify instructions. Skills can be pulled from the public directory at skills.sh, from a user's saved collection, or directly from a repository. The directory includes skill sets contributed by Vercel, Anthropic, Microsoft, Supabase, and others, covering everything from UI component generation to database schema design.
Pika Director's Suite Generates a 6-Minute TV Pilot End-to-End
Pika Labs unveils an AI agent that understands and builds every element of a video project, from character arcs to scene composition, in a unified platform.

The Director's Suite represents a leap from frame-level video generation to project-level understanding. The agent maintains continuity across a full 6-minute narrative, tracking character consistency, scene transitions, and visual style. When a user gives a directive like "have Doug crash the office party," the agent interprets the narrative context, adjusts the scene, and propagates changes downstream — something that previously required manual timeline editing across multiple tools. The demo pilot showcases end-to-end creation with no external editing required.
SGLang Adopts Block-Diffusion Drafting as Default Engine
The block-diffusion drafter, developed with Z Lab, is now the default speculative decoding engine in SGLang at frontier scale, significantly boosting throughput.
SGLang has set the block-diffusion drafter as its default speculative engine for large-scale inference. The technique, which fits draft generation to GPU-friendly block sizes, was developed in collaboration with Z Lab. By making it the default, SGLang signals that block-diffusion drafting has graduated from experimental to production-grade for the broader open-source serving community. The change is expected to meaningfully improve tokens-per-second across all SGLang deployments without requiring configuration changes from users.
LLMs Inherit Hidden Traits from Distillation, Study Reveals
Neel Nanda highlights research showing distilled models carry subtle, non-obvious characteristics from their teachers, with safety evaluation implications.
The research reveals that LLMs inherit a wide range of traits from the models they are distilled from, including features without clear semantic meaning. This matters for safety because problems baked into a teacher model during distillation may persist invisibly in the student, evading standard red-teaming and evaluation suites. The findings suggest that distillation is not just a compression technique but a carrier of behavioral DNA requiring its own audit framework.
Anthropic Added "Verification Data" Clause Before Fable Launch
Simon Willison flags that Anthropic updated its privacy policy on June 8 — the day before Fable 5's release and four days before the US export ban — to include language about collecting verification data.
The timing of the policy update has raised eyebrows in the AI community. The new clause gives Anthropic the right to collect what it terms "verification data," though the scope and purpose remain vague. Willison's discovery adds another layer of complexity to the already tumultuous Fable 5 saga. Privacy advocates are calling for greater transparency about what data is collected and how it relates to model safety testing.
Fable 5 Return Looks Unlikely in the Near Term
Simon Willison signals pessimism about the model's restoration, with community sentiment aligning around an extended absence.

The brief window in which Claude 5 Fable was publicly accessible may be the only one for the foreseeable future. Willison's assessment, based on available signals from Anthropic and regulatory timelines, suggests users should not expect a quick return. The gap between the model's demonstrated capabilities and its unavailability has fueled both admiration and frustration across the developer community, with some arguing that the brief exposure itself has become part of the model's mystique.
Tri Dao Proposes Recompute Trick to Double SSM Agent Speed
As hybrid models like Qwen 3.5 and Nemotron Ultra run agents across massive context windows, the state management in architectures like Gated-DeltaNet and Mamba has become a bottleneck. Tri Dao offers a deceptively simple insight: load the states, compute, but don't store them. This recompute trick bypasses the memory wall, enabling speculative decoding for SSM-based models and delivering a 2× speedup on long-context agent workloads. The technique is particularly relevant as more production systems adopt hybrid architectures that combine dense attention with state-space layers, where state I/O has been the primary throughput limiter. The approach unlocks techniques previously thought impossible for recurrent architectures and could accelerate the adoption of SSM-based agent systems across the industry.
Codex Developer Plugin Launches
OpenAI introduces a developer plugin in Codex with API key setup, documentation search, and debugging support for faster integration.
M3 Lands on CommandCodeAI, Free Through the 17th
CommandCodeAI integrates MiniMax M3, accessible via a single npm install in the terminal, with free access through tomorrow.
UK Operations Triple Against US Rivals
The Canadian AI company expands its London footprint, growing its UK team threefold to serve as an alternative to OpenAI and Anthropic.
Cline CLI Brings Parallel Agent Tasks via Kanban
Ollama now supports Cline, a coding agent that reads repos, edits files, and runs commands with Kanban-based parallel task execution.
PD Disaggregation Validated on AMD MI325X
The Anyscale team stress-tested PD disaggregation with Ray Serve and vLLM on AMD hardware, confirming real-world viability.
Serverless and Servers Converge in 2026, CEO Says
Guillermo Rauch argues sandboxes, functions, servers, and builds are expressions of the same compute layer, merging seamlessly.
Fluid MicroVM Enables Longer Function Runtimes
Vercel ships extended function runtimes powered by its proprietary Fluid compute platform, years of infrastructure investment.
Nathan Lambert: "Distillation" Is a Misused Term
Lambert argues AI labs misuse "distillation" to obscure API jailbreaking issues, calling for clearer community terminology.
AI Solves 7 of 10 Novel Math Problems — Not a Failure
Ethan Mollick pushes back on negative framing: 15 months ago LLMs couldn't do math at all. The progress is the real story.
S4L Paper from 2019 Rediscovered by LLM Researchers

The self-supervised semi-supervised learning framework achieved SOTA on ILSVRC-2012 with only 10% labels. The computer vision community's prior art is now informing LLM training strategies.
Why Is V4-Pro Performance So Close to V4-Flash?
teortaxesTex raises a critical open-source question: if V4-Pro is distilled from Flash experts, that recipe could dominate. If it's not scalable, the advantage stays with closed labs.
Keras Creator: Opaque AI Regulation Hurts Everyone
François Chollet says even pro-regulation voices should reject arbitrary, non-transparent crackdowns. Such actions breed uncertainty across the industry.
NVIDIA: Energy Is the Key Constraint on AI Growth

NVIDIA positions energy as the foundation of the five-layer AI stack, with digital twins and intelligent agents transforming power production and grid management.
LlamaIndex Rethinks Contract Management Beyond OCR

Traditional contract tools treat documents as flat text. LlamaIndex argues AI can deeply understand contractual meaning, automating renewal tracking and compliance checks.
Hedra Agent 2 Automates Video Production Pipelines

Hedra's Agent 2 handles design, illustration, and publishing planning for video projects, freeing creators to focus on narrative and creative direction.
Recraft V4.1 Excels at Editorial Fashion Photography

The latest Recraft model captures organic textures, cinematic greens, and natural skin tones with a deeply photographic quality for fashion editorials.
Nathan Lambert Releases Three New Post-Training Lectures

New videos cover the rise of reasoning models and DPO derivation, with a Q&A on lectures 1 through 4, available at rlhfbook.com/course.
Three Scoring Strategies for Evaluating LLM Agents

C. Wolfe outlines evaluation approaches from quick manual checks to structured rubrics, with human judgment remaining the definitive ground truth.
Building a Multi-Cluster Agent Control Panel
Graham Neubig built infrastructure to manage agents across H100, CPU, and home clusters simultaneously — running experiments, data processing, and implementation in parallel.
QR V2 Benchmark Challenges Condition Number Optimization
Aohan's new problem set tests optimization tricks around avoiding squared condition numbers, with a fresh leaderboard and open community competition.
Tesla Robotaxi Logs Zero At-Fault Incidents Since February
NHTSA's latest data shows that Tesla's autonomous ride-hailing fleet has maintained a clean safety record for over three months, with zero at-fault incidents since February. The milestone arrives as the industry debates what metrics truly capture autonomous driving safety. Tesla argues the data validates its camera-only approach to full self-driving, though critics note the Robotaxi fleet operates in geo-fenced areas under favorable conditions. The figures were released alongside broader autonomous vehicle safety statistics and are expected to feature prominently in upcoming regulatory discussions about expanding driverless service areas.
Hugging Face CEO: "It's Time to Own Intelligence, Not Rent It"
Clement Delangue amplified a framework from Lin Qiao: the shift from renting intelligence via API calls to owning it through open-weight models represents the defining infrastructure battle of 2026. The framing captures growing enterprise anxiety about vendor lock-in as model capabilities accelerate. With each major lab now offering frontier models that can be fine-tuned and self-hosted, the rent-versus-own question is no longer theoretical — it's a procurement decision with multi-year cost and control implications. Delangue's endorsement signals that Hugging Face intends to be the platform where that ownership happens.