OpenAI Foundation Launches with $250 Million for AI Prosperity
The OpenAI Foundation announced an initial $250 million investment to measure economic impact, support transformation, and explore new pathways to shared prosperity in the age of artificial intelligence.
Sam Altman announced the formation of the OpenAI Foundation, committing an initial $250 million to measurement, transition support, and new approaches to broadly shared prosperity. The foundation, structured as a philanthropic initiative, aims to ensure that artificial intelligence dramatically increases quality of life and individual freedoms around the world. The funding will support three pillars: rigorous measurement of economic impact as AI reshapes labor markets, direct resources for workforce transition programs, and policy-oriented research exploring how societies can distribute the gains of AI broadly rather than concentrating them among a narrow set of beneficiaries. The foundation's first projects include partnerships with academic institutions to study wage and employment shifts, pilot retraining programs in manufacturing and services, and the development of open economic models that policymakers can use to evaluate different regulatory approaches. The initiative marks one of the largest philanthropic commitments specifically tied to AI's socioeconomic consequences, signaling growing recognition among industry leaders that the technology's benefits must be deliberately steered toward inclusive outcomes rather than left to market forces alone.
Gemini Embedding 2: A Native Multimodal Embedding Model
Google DeepMind published the whitepaper for Gemini Embedding 2, a native multimodal embedding model that processes text, images, and audio in a unified representation space. Unlike previous embedding approaches that treat each modality separately and fuse results downstream, Gemini Embedding 2 natively encodes multimodal content in a shared latent space, enabling richer retrieval and cross-modal understanding without post-hoc alignment. The model can operate on text, images, and audio simultaneously, opening the door to search and recommendation systems that understand documents, images, and spoken content through a single representation.
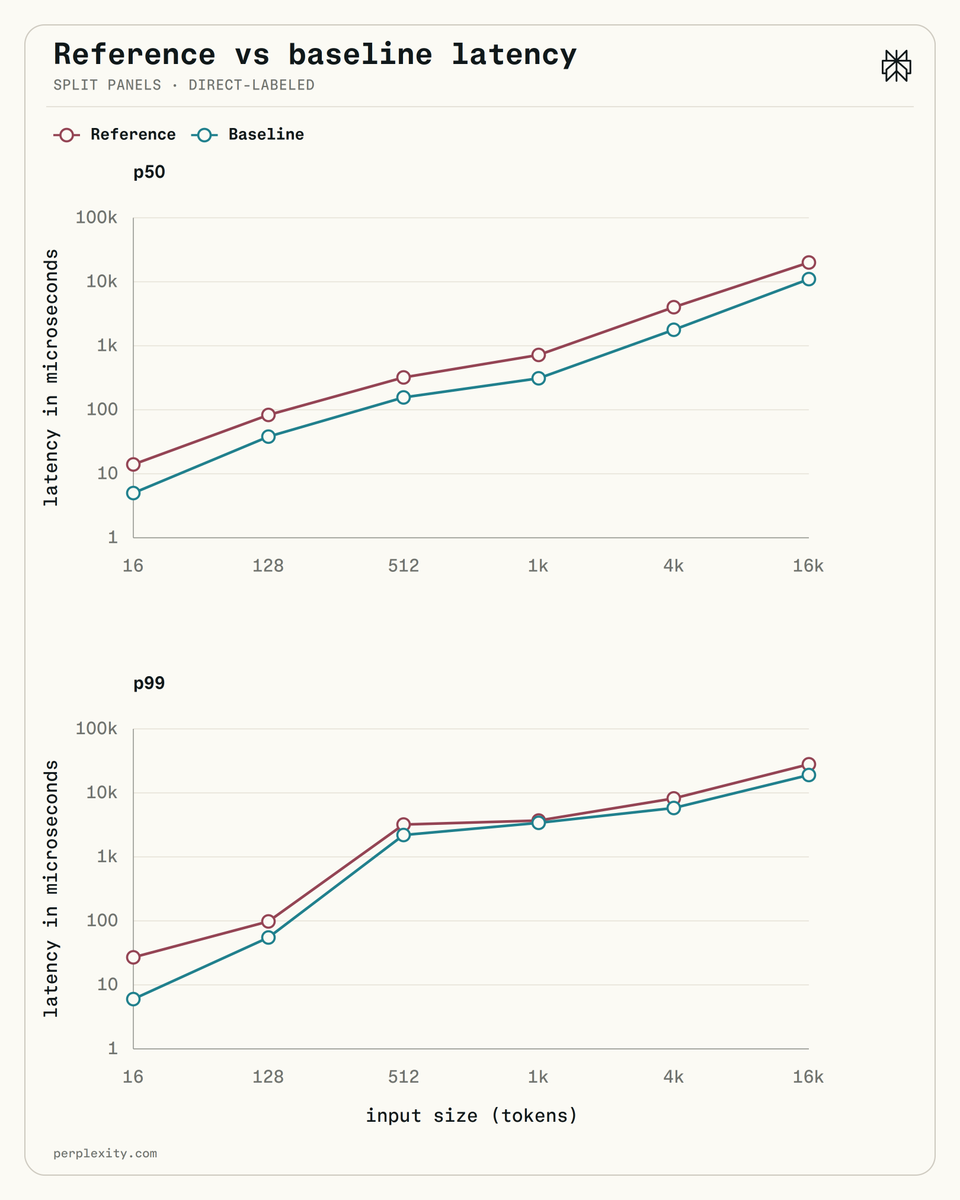
Perplexity Open-Sources Inference Toolkit with 5–6× Lower CPU Usage
Perplexity AI open-sourced pplx-garden, a collection of inference technologies that includes an RDMA transport engine, P2P Mixture-of-Experts distribution and composition kernels, and a rebuilt Unigram tokenizer. The tokenizer reduces CPU utilization by five to six times compared to existing solutions, addressing a bottleneck that has become increasingly visible: when small rerankers and embedders run inference in single-digit milliseconds on GPU, CPU-side tokenization can dominate total latency. The RDMA engine enables high-throughput cross-GPU communication, while the P2P MoE kernels handle expert dispatch and output aggregation efficiently. The entire toolset has been battle-tested in production at Perplexity and is available under a permissive open-source license on GitHub.
Block Training: Deep Networks Without End-to-End Backprop
For over a decade, the AI field has accepted that end-to-end backpropagation is the only viable way to train deep networks. But holding the entire network in memory at once is why training is hitting a resource wall. A team of researchers has demonstrated a new method that decomposes the network into blocks and trains them independently, using localized objectives rather than global gradients to propagate learning signals. The approach eliminates the need to maintain the full computation graph in memory, which is the dominant cost for large-scale training. Each block learns to solve its own sub-problem while a lightweight coordination mechanism ensures the blocks remain compatible. Early experiments show the method can train networks that would otherwise exceed available GPU memory by a factor of three or more.

Runway Launches MCP Access: Generate Images and Video Directly in Claude, ChatGPT, and Cursor
Runway MCP allows users to call state-of-the-art generative models like Gen-4.5, Seedance 2.0, GPT Images 2.0, and Kling from within their existing development tools, eliminating context-switching between creative and coding workflows.
Runway has introduced Runway MCP, a new integration that connects its generative AI models directly into popular development environments through the Model Context Protocol. Users can now generate polished images and videos using state-of-the-art models from within Claude, ChatGPT, Cursor, Replit, and other MCP-compatible tools, without ever leaving their editor or chat interface. The integration supports Runway's full model lineup including Gen-4.5 for photorealistic generation, Seedance 2.0 for video, GPT Images 2.0 for text-to-image, and Kling for advanced visual synthesis. For developers building creative applications, this eliminates the traditional round-trip of generating assets in one tool and importing them into another, tightening the loop between ideation and execution. Early adopters report significant reductions in iteration time for design prototyping, marketing asset creation, and rapid visual experimentation. The MCP server communicates through outbound-only HTTPS, meaning Runway's models are called from within the developer's tool rather than requiring inbound connections to a Runway-hosted service.

Luma Unveils Creative Agents for End-to-End Creative Workflows
Luma released Creative Agents, a new suite of intelligent agents designed to act as force multipliers for creative teams. The agents can plan, generate, iterate, and optimize across every stage of a creative project, from initial concept through to final output. Users describe project goals in natural language, and the agents orchestrate the full workflow: generating rough drafts, iterating based on feedback, refining details, and producing final assets. The system adapts to a wide range of creative domains, from film pre-visualization and marketing campaigns to product design and illustration. Luma positions the agents not as replacements for human creators but as accelerators that handle the mechanical parts of production work, freeing creative professionals to focus on direction and taste.
OpenAI Launches Secure MCP Tunnel for Private MCP Servers
Teams can now keep MCP servers inside their network while ChatGPT, Codex, and the Responses API connect through outbound-only HTTPS, eliminating the need to expose internal services to the public internet.
OpenAI introduced a secure MCP tunnel that allows organizations to deploy private or local MCP servers on their internal networks and connect them to OpenAI's products through outbound-only HTTPS connections. The architecture eliminates the need for complex VPN configurations or exposing internal services to inbound connections from the public internet. In practice, a company's MCP server running behind a corporate firewall initiates a single outbound connection to OpenAI's infrastructure, which then tunnels requests from ChatGPT, Codex, and the Responses API back through that established channel. The tunnel is authenticated and encrypted end-to-end, and the MCP server remains invisible to external scanners. This design addresses a persistent security concern for enterprises that want to use custom tool integrations with AI products but cannot expose internal APIs or databases to direct internet access.
For over a decade, we have accepted that end-to-end backprop is the only way to train deep networks. But holding the entire network in memory all at once is why AI training is hitting a resource wall. We found a new way to break the network into blocks and train them independently.
Hardmaru on breaking the backprop bottleneck

MiniMax M2 Technical Report: Full Attention Defies the Sliding-Window Trend
Sebastian Raschka summarized key findings from the long-awaited MiniMax M2 technical report, highlighting several design choices that run counter to prevailing trends in open-weight language models.
The MiniMax M2 series, one of the most widely used open-weight LLM families earlier this year, has finally received a detailed technical report. Sebastian Raschka highlighted several notable findings. First, the models use full attention rather than the now-ubiquitous hybrid sliding-window attention mechanisms that many recent releases have adopted. This was an intentional anti-trend decision by the MiniMax team, who found that full attention provided better long-range understanding for the tasks their users prioritize. Second, the architecture employs a Mixture-of-Experts design, with routing strategies and load-balancing techniques refined through extensive ablation studies. The report also documents several training techniques that contributed to the series' strong real-world adoption, including data curation strategies, a specialized pre-training curriculum, and a multi-phase fine-tuning regime that balances general capability with task-specific performance.
Qwen3.7-Max Ranks 4th on Code Arena, Tied with Claude Opus 4.6
Qwen3.7-Max reached fourth place on the Code Arena leaderboard, the highest-ranked Chinese lab, with performance comparable to Claude Opus 4.6.
Qwen3.5 Hits Record 580 tps on TokenSpeed Engine for Agent Workloads
Qwen3.5 achieved a record-breaking 580 tokens per second for agentic workloads on the TokenSpeed inference engine, enabled by partnerships with Lightseek, NVIDIA, and the Mooncake team.
OpenAI to Retire GPT-5.2 and GPT-5.3-Codex on June 2
To simplify Codex compute fleet management, GPT-5.2 and GPT-5.3-Codex models will be sunset on June 2.
Claude Code Gets Significant Reliability and Speed Improvements
The Claude Code team detailed engineering efforts to make the agent more responsive and reliable, with improvements spanning the full stack.
xAI Integrates Grok into Open-Source Coding Platform Kilo Code
SuperGrok and X Premium+ subscribers can now use Grok in Kilo Code, featuring the grok-build-0.1 model with high-speed agentic coding intelligence.
MiniMax Ends M2 Series, Next-Generation M3 Model on the Horizon
MiniMax announced the end of its widely-adopted M2 open-weight LLM series and signaled the arrival of the M3 generation.
OpenBMB Releases MiniCPM5-1B Edge LLM Under Apache 2.0
A 1B-parameter edge LLM with hybrid reasoning capabilities and state-of-the-art performance in its class, designed for on-device deployment.
AI Infrastructure Company Modal Raises $355 Million Series C
Modal closed $355 million to expand its AI-native compute platform and sponsor CI GPUs for DeepSpeed and ArcticTraining.
Snowflake AI Releases ZoRRo: Zero-Redundancy Rollout for Faster RL
ZoRRo eliminates bottlenecks in distributed RL execution, achieving significant speedups with no additional overhead.
Codex Builds Self-Improving Tax AI Agents with Thrive Holdings
OpenAI partnered with Thrive Holdings to co-build tax preparation workflows using Codex. When reviewers fix errors during preparation, Codex traces the failure, improves the system logic, and tests the change before it ships.
Qwen3.7 Max Now Accessible in Go with 1-Million-Token Context
The smartest Qwen model to date is now available via Go, offering text-only mode and a one-million-token context window.
RF-DETR Joins Hugging Face Transformers, Outperforming YOLO
Roboflow's state-of-the-art real-time object detection and segmentation model has been integrated into the Hugging Face Transformers library with strong benchmarks.
LlamaIndex Releases LiteParse v2.0: Rust Rewrite, 100× Faster
LiteParse v2.0 is completely rewritten in Rust, delivering up to 100× faster document parsing. It supports Rust, JS/TS, and Python, with a WASM package enabling browser and edge runtime usage.
EAGLE 3.1 Powers Next-Generation AI Inference Infrastructure
The latest EAGLE release brings advancements to the inference infrastructure powering many of the industry's most formative AI companies.
Tencent Hunyuan Translation Model Gains Strong Traction on Hugging Face
Tencent's latest Hunyuan translation model has received significant community engagement and download numbers on Hugging Face.
Prism Releases 1-Bit and Ternary Bonsai Image 4B Generation Models
A new family of image generation models supports high-quality image generation, fine-tuning, and efficient local execution on constrained hardware.
ESMFold2 Advances Protein Structure Prediction for Open Science
EvolutionaryScale announced ESMFold2, which predicts high-accuracy protein structures from single sequences, advancing AI-driven open science in biology.
Cambrian-P Fuses Pose Information for Robust Multimodal Video Models
Saining Xie's team released Cambrian-P, which jointly models video frames with pose data, giving multimodal models globally consistent spatial structure.
Google Launches AI Threat Defense Cybersecurity Solution
A comprehensive AI-driven cybersecurity solution designed to help organizations detect and respond to threats in real time.
NotebookLM Gets Google Drive Auto-Sync Feature
The most-requested feature — automatic Google Drive file synchronization — is rolling out to NotebookLM users.
AI Factories: Converting Energy into Intelligence in Real Time
NVIDIA AI Infrastructure describes AI factories as the infrastructure of the new era, measured in tokens per watt.
Demis Hassabis: AI Will Accelerate the Pace of Scientific Discovery
The DeepMind co-founder shared an essay from the American Academy of Arts and Sciences on how AI can transform scientific research.
Runway CEO: AI Video Has Crossed the Uncanny Valley
Cristóbal Valenzuela stated that AI video generation has crossed the uncanny valley, marking a turning point in perceived realism.
Epicure: Multilingual Ingredient Embedding Models from 4.14M Recipes
Three skip-gram-based models trained on recipes across seven languages, building co-occurrence and flavor-compound graphs for food science.
Yann LeCun Retweets JEPA Identifiable World Model Proof
A theory of identifiable world models proves that JEPA learns an identifiable latent space grounded in Gaussian distributions.
Perplexity CEO: Every Millisecond Matters for Production Tokenizers
Arav Srinivas announced that the company's production tokenizer far outperforms HuggingFace and SentencePiece in efficiency.