Vidu 发布 S1 模型,号称世界最先进实时 AI 交互模型
Vidu AI 推出 S1 模型,支持语音驱动的实时角色控制,能理解、反应并响应真实交互。
Vidu AI 正式发布 S1 模型,宣称这是世界上最先进的实时交互式视频 AI。S1 引入语音驱动的实时角色控制,超越传统的唇形同步技术,能够实时生成角色行为。角色可以理解语音指令、对场景做出反应,并通过动态视频输出回应用户。这标志着视频生成从单向输出迈向双向实时交互的关键突破。
腾讯阿图因 AI 漏洞挖掘超越 Anthropic Mythos
腾讯玄武实验室的阿图因 AI 在漏洞挖掘上全面超越 Anthropic 的 Mythos,在 curl 项目中发现中危漏洞,CyberGym 得分 84% 略高于 Mythos。

腾讯玄武实验室开发的阿图因 AI 在漏洞挖掘上全面超越 Anthropic 的 Mythos 模型。在 curl 项目中,阿图因发现一个被 Mythos 遗漏的中危漏洞 CVE-2026-9079,已被 curl 官方定级确认。在 CyberGym 漏洞挖掘测试中,阿图因得分 84% 略高于 Mythos。此外,阿图因还在 cryptography、OpenSSL 等多个加密算法库以及 AI 生态软件中发现了严重逻辑漏洞,最高评分达 10 分的满分水平。
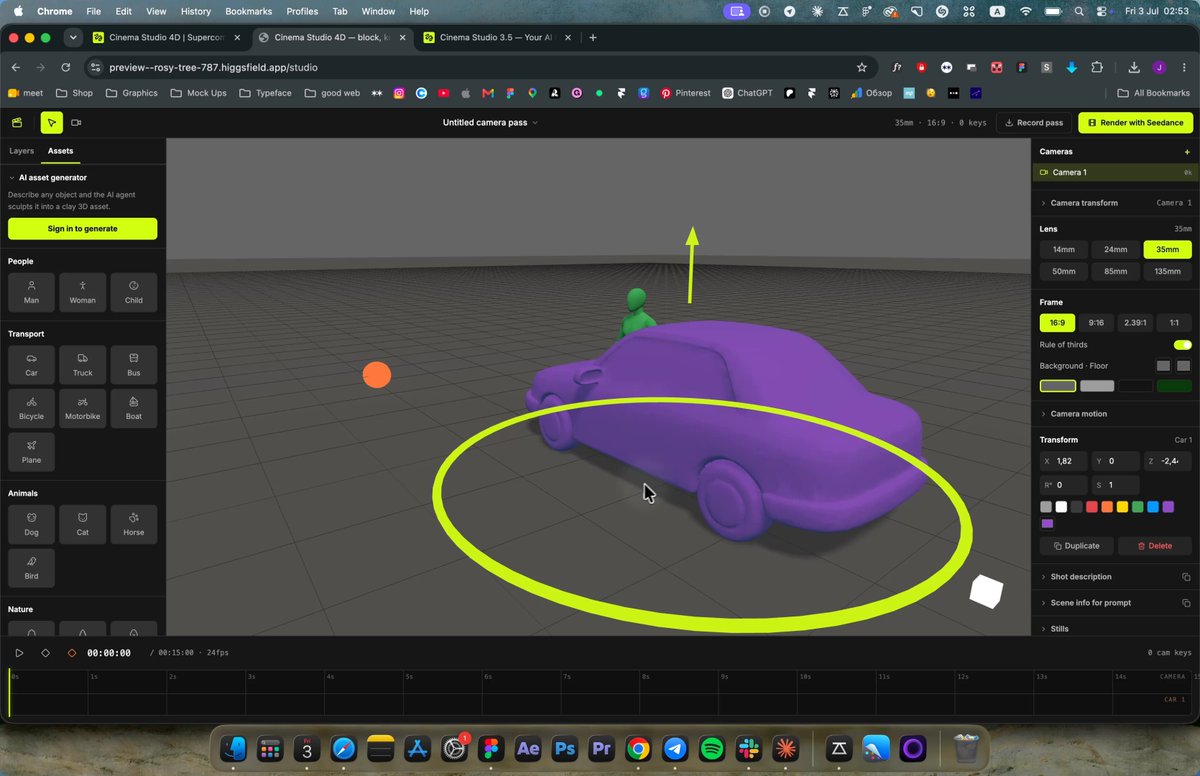
Fable 5 在超级计算机上实现从 3D 场景到视频的惊人效果
Higgsfield 展示用 Fable 5 配合 Seedance 2.0,从 3D 场景记录到电影级视频渲染的完整工作流。创作者构建应用,录制真实摄影机运动轨迹,再通过 Seedance 2.0 渲染为视频。仅需 15 秒即可生成携带精确轨迹、节奏和构图的黏土风格片段,展示了 AI 视频生成从"给一句提示词"到"借 3D 场景精确控制"的范式升级。
Vercel 推出 Eve Agent 框架,支持自我改进
Vercel 的 Eve agent 框架内置可观察性,允许代理分析历史运行并生成新指令和技能,实现自我改进。
Vercel 发布开源 agent 框架 Eve,采用文件系统组织方式:instructions.md 定义角色与行为,skills、tools、channels 等模块按需添加。Eve 支持持久化执行、沙箱隔离、多通道交付、人工审核、子代理和评估。核心亮点是代理自我改进——通过内置可观察性,代理可以内省过往运行,发现低效、错误和冗余的工具调用,并据此生成新的提示词与技能。Eve 原生集成 Next.js,可自托管部署。
让模型自行判断何时使用低功耗模型,可以大幅节省 Token。
—— Simon Willison 分享 Claude Fable 最佳实践
Vercel Sandbox 支持 Docker 和 FUSE,助力 Agent 运行
Vercel Sandbox 现可无限制运行 Docker 和 FUSE,基于微虚拟机实现即时启动。配合 S3 支持的文件系统,仅需 10 行代码即可为 agent 提供完整运行时环境。这是 Vercel Fluid compute 基础设施的重要里程碑,为 agent 执行提供真正无约束的运算空间。
Le Chaton 发布 Leanstral 1.5,代数基准达 SOTA
Le Chaton(Leanstral 1.5)模型正式发布,在研究生级代数基准测试上达到 SOTA 性能。Arthur Mensch 领导的相关团队发布了这款专注数学推理的模型,在代数证明和推理领域展现了强大的专业能力,为学科专用模型的路线提供了有力验证。


阿里万相视频新增「音乐跳舞」功能,可生成节奏同步舞蹈
阿里万相视频推出 Music to Dance 功能,上传角色和音乐即可生成与节奏同步的舞蹈视频,支持街舞、踢踏、拉丁、K-Pop、中国古典舞等多种风格。
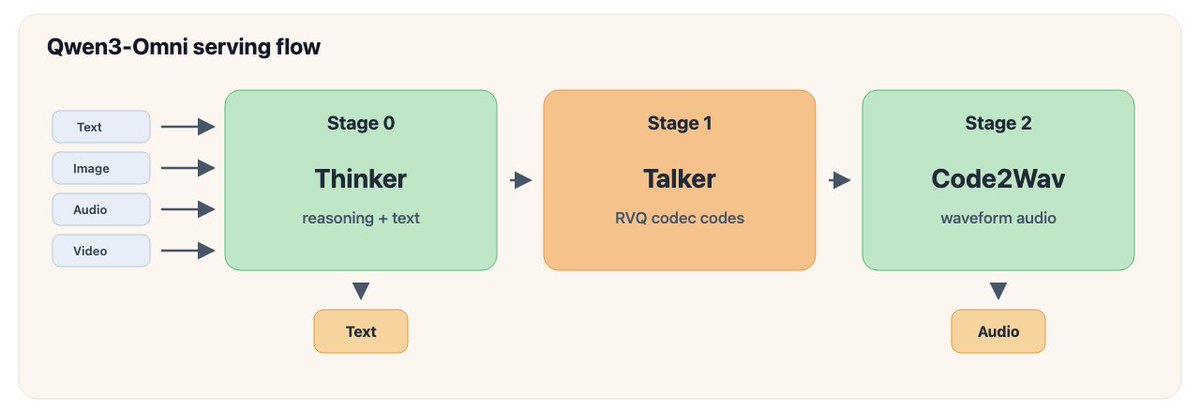
vLLM 详解 Qwen3-Omni 实时推理管道优化
vLLM 团队分享为阿里通义千问 Qwen3-Omni 多模态模型提供实时推理服务的管道优化经验。Qwen3-Omni 分为 Thinker、Talker、Code2Wav 三阶段,每阶段瓶颈不同,团队通过逐层优化实现高效实时交付。

Higgsfield 展示 Fable 5 与 Sonnet 5 在 Agent 提示上的对比
Higgsfield AI 对 Fable 5 和 Sonnet 5 在 agentic prompting 上进行对比,两者均使用 Seedance 2.0 生成视频,展示了不同模型在代理任务中的表现差异。
Gemini Omni Flash 登顶 Video Arena 排行榜
Google DeepMind 的 Gemini Omni Flash 模型在 Video Arena 榜单以 Elo 1404 排名第一,树立了视频理解能力的新标杆。Demis Hassabis 转发此消息予以关注。
Google DeepMind 推出 COrigami 协同设计管道
Google DeepMind Discovery 团队发布了 COrigami,一个用于协同设计蛋白质和 RNA 的端到端管道,由 Tzahavy 主导研发。
Sakana AI 论文《基于 Sheaf-ADMM 的多智能体协调》被 ICML 2026 接收
Sakana AI 的论文 Learning Multi-Agent Coordination via Sheaf-ADMM 将于 ICML 2026 展示,由 hardmaru 转发。该工作探索基于代数拓扑的 Sheaf-ADMM 方法实现多智能体协调。
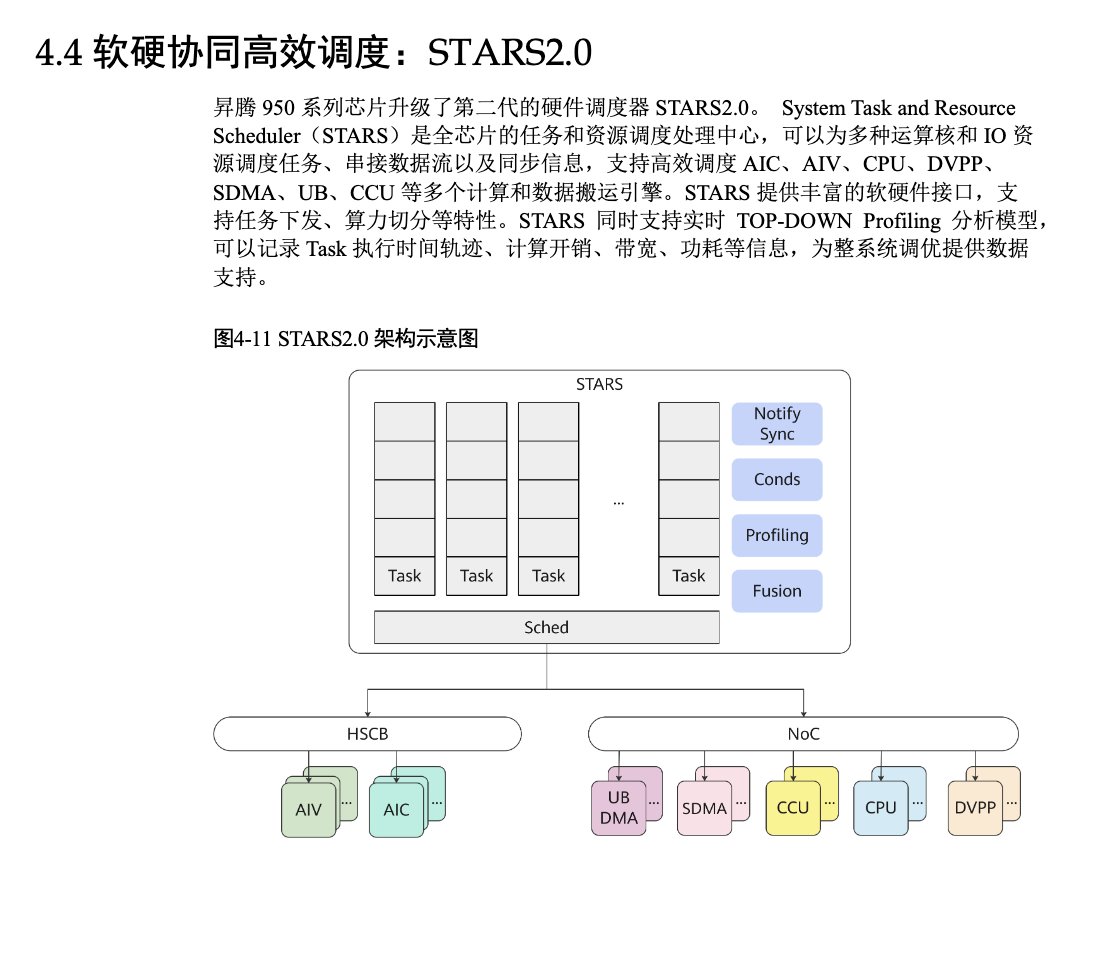
华为 Ascend 950 白皮书展现独特技术路线
分析认为华为 Ascend 950 的白皮书揭示了与西方不同的技术树,展现出独特的架构设计思路。评论指出这与中国走苏联式技术路线的阶段相似,预期到 970 代将在大幅修订 FP4 后出现更明显分化。

华为 910C 性能达 800 系列 90%,美团 35T 参数集群估算
分析估算华为 910C 单卡性能约为 Nvidia P800 的 90%。以此推算,DeepSeek 训练 V3 时的集群若换用 910C(规模约 10 倍放大),美团 35T 参数的预训练可望在 5 到 6 周内完成。虽然存在 FP8/FP16 混合精度和 CANN 框架的折算因素,但整体效率可观。

CUDA 护城河因中国芯片发展而变得脆弱
技术分析认为,CUDA 的护城河建立在 Nvidia 硬件在中国市场的广泛可用性之上。但随着华为 Ascend 等国产方案迭代加速,人才不再全部留在 CUDA 生态中,"每个人都待在 Jensen 的棚子里"的条件已不复存在。这是一道依赖张拉结构的护城河,一旦拉索断裂就会崩塌。
PerceptionRubrics 多模态评估基准发布,校准至人类感知
PerceptionRubrics 是一个基于评分标准的多模态评估基准,包含 1038 张信息密集图像和超过 10000 条实例级评分标准。它采用循环同行评审生成黄金标题,并引入门控 Must-Right / Easy-Wrong 评分机制,旨在将模型评估校准至人类感知水平。
GLM-5.2 现可通过 Hugging Face 在 Claude Code 中使用
GLM-5.2 开放模型现已可通过 Hugging Face Inference Providers 在 Claude Code 中选择,标志着开放模型在主流工具链中的集成度持续提升。
Cohere 强调模型直接部署至客户以求数据安全
Cohere 表示将模型部署到客户环境中而非让客户发送数据,虽然增加了复杂度但确保了企业数据安全。
LlamaIndex 发布与 Eve Agent 框架集成模板
LlamaIndex 为 Vercel 新发布的 Eve agent 框架构建了集成模板,提供只读文件系统工具以增强代理能力。
Replit 上线视频生成功能
Replit CEO Amjad Masad 提醒用户可尝试在 Replit 平台上进行视频生成。
Runway 团队分享七年 AI 工程基础设施经验
Runway 平台团队分享其七年来构建的稳健研究基础设施和工具,这是他们能训练和部署模型的关键。
SGLang 将工程经验编码为可执行 Agent 技能
SGLang 团队将数月积累的工程经验(基准测试、CUDA 内核调优等)编码为可执行 Agent 技能,让开发者专注更复杂决策。
Sam Altman 在 CNBC 上提出向美国赠送 OpenAI 5% 股份
Yann LeCun 转引分析:Sam Altman 在 CNBC 上提出将 OpenAI 5% 股份赠予美国的叙事策略。
用户让 Claude Fable 反复升级游戏至 AAA 品质,结果惊人
一位用户让 Claude Fable 不断将游戏升级至 AAA 品质,Fable 自动添加图形、Boss 战、自定义音效和配乐,直到触及 WebGL 极限。
将数据混合视为语言模型训练的因果推断
新论文 CausalMix 提出将数据混合视为语言模型训练的因果推断问题,探索数据配比的新方法论。
Program-as-Weights 论文提出模糊函数编程范式
新论文提出"程序即权重"编程范式,用于模糊函数,探索神经网络权重编码与程序语义的统一表达。
研究:训练早期 tokenizer 设计影响模型后训练语言适应性
研究表明,训练早期的 tokenizer 设计等低成本干预可以提升模型后训练时适应新语言的"语言可塑性"。
SPEAR 物理 AI 模拟器被 ECCV 2026 接收
Manycore Tech 的 SPEAR 下一代物理 AI 模拟器论文被 ECCV 2026 接收,代码已开源。
单次视觉语言动作适应环境变化
首尔大学研究显示,权重空间适应可帮助视觉-语言-动作模型应对环境变化。
新论文被 ECCV 2026 接收,代码已开源
一篇论文被 ECCV 2026 接收,作者已发布代码。
EdgeBench 基准测试:研究 Agent 长期环境学习
EdgeBench 基准测试旨在研究代理如何在至少 12 到 72 小时运行中从环境中学习,探索长期自主智能体行为。
CMU 高级 NLP 全部课程已免费公开
CMU 高级自然语言处理课程的全部 23 讲已在 YouTube 上公开,并提供幻灯片和代码示例。
Coding Agents 已成 Hugging Face Hub 主要流量来源
数据显示,Claude Code 等编码代理已占 Hugging Face Hub 代理流量的约 24%,成为平台真实用户。
开源语音转语音进展惊人,建议更新认知
Hugging Face 转发 Thom Wolf 观点:开源语音转语音技术已取得令人惊讶的进步,建议行业更新对它的认知。
观点:小型推理模型才是真正的英雄
有评论指出,虽然大家都关注 Fable、GPT5.6 等大模型,但真正重要的是小型推理模型的发展。
Hugging Face 博客:不训练模型,进化框架
一篇博客提出,使用冻结的开放模型并改进其外部框架可能比训练模型更有效。
用 Claude Fable 将文字小说改编成电影片段
用户让 Claude Fable 利用 ElevenLabs 和 Hugging Face 的 API,将公版书籍《Last and First Men》制作成 10 到 15 分钟电影片段。
为何单文件 HTML 演示不能揭示前沿与开源的差距
技术评论认为,单纯依靠单文件 HTML 演示无法准确评估前沿模型与开源模型之间的实际差距。
Fable 的思维链可能已用于多智能体训练
有观点认为 Fable 的思考过程可能已经在其多智能体训练中使用,未来唯一面向用户的模型可能是 CoT 摘要器。
为何使用 Kimi Linear megakernel 而非 Qwen 3.6
技术分析解释为何选择 Kimi Linear megakernel 而非参数更多的 Qwen 3.6 的原因。
PixVerse 使 AI 视频模板细节可控
PixVerse 推出新功能,允许用户在已有 AI 视频模板基础上控制细节,实现个性化调整。
PixVerse 推出营销中心,助力电商本地化广告
Marketing Hub 帮助电商团队快速创建本地化广告变体,无需拍摄和剪辑。
阿里万相推出 Wan Skills 功能,可将照片转为数字日记
Wan Skills 功能可轻松将标准照片转变为个性化数字日记,包含手写风格等特色。
用户通过几次点击即可解锁手写风格相册和个性化数字日记等功能。