吴恩达:美国政府和Anthropic展现了控制模型访问的巨大权力
Andrew Ng指出,过去两周美国政府与Anthropic的行动表明,他们有能力限制用户对前沿模型的使用,这一局面将产生深远影响。

过去两周内,美国政府与Anthropic公司采取了一系列具有标志性意义的行动,集中展现了他们对前沿AI模型访问权限的控制能力。吴恩达在社交平台上明确指出,这是一个"一旦看到就无法忽视的时刻"。
具体而言,美国政府对AI技术的出口管制与使用限制正持续收紧,而作为一家领先的闭源模型公司,Anthropic也在通过技术壁垒与商业策略影响模型的可及性。两者共同构成了对AI民主化趋势的一种反向推力。吴恩达警告,这种集中化控制可能深刻改变AI生态的权力结构,尤其是对非西方国家的研究者和开发者而言。
多位AI领域意见领袖对此事的转发引发连锁讨论。一位评论者指出,开源模型社区需要将这些事件视为预警信号。如果不能保持开放的模型生态,AI发展路径将从由社区共同决定,转向由少数机构单方面主导。
宾大实验:管理者用Claude Code编程成功率最高
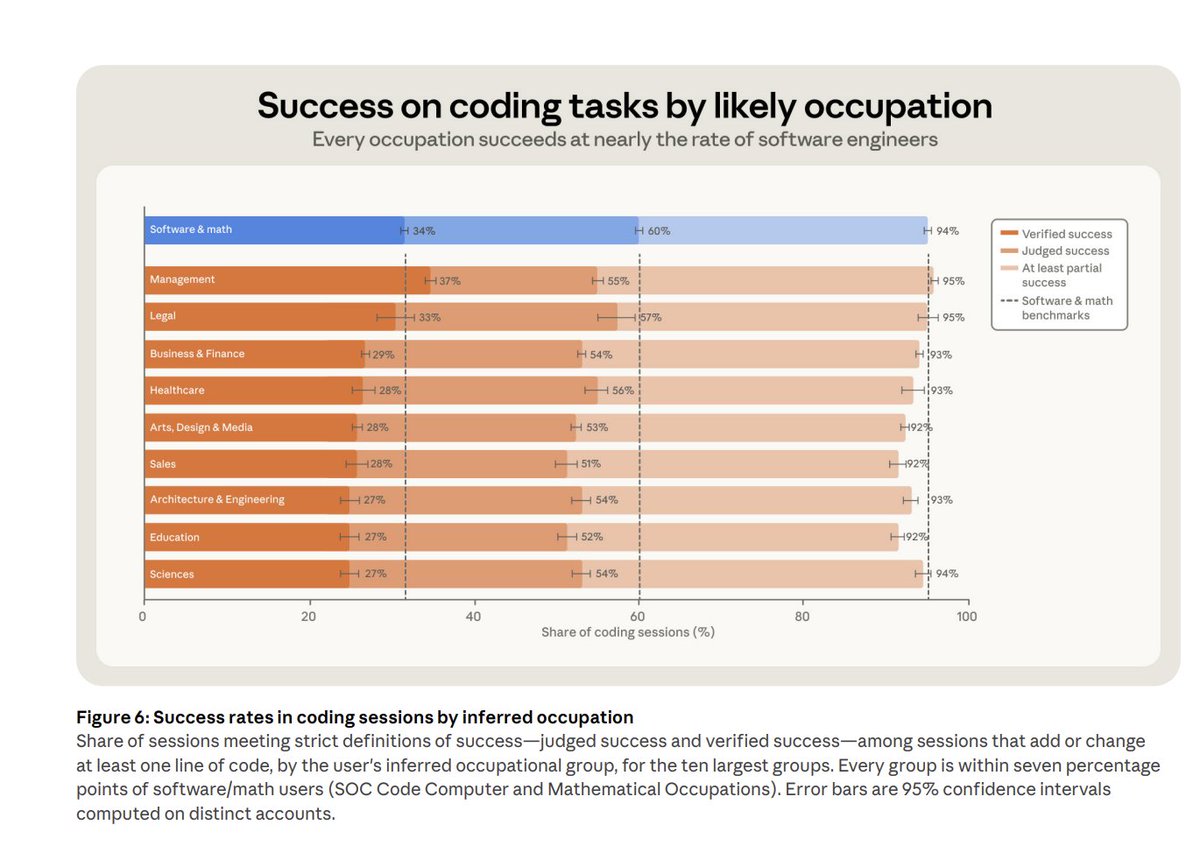
宾大沃顿商学院教授Ethan Mollick在一项EMBA实验中得出惊人发现:管理者在使用Claude Code编程时成功率最高。这一结论打破了"技术人员写代码效率最高"的固有认知。
关键在于清晰的需求描述。管理者习惯于明确定义目标、评估标准和交付物——这些恰好是高效使用AI Agents的核心能力。参与实验的学生在4天内从零创建出完整的初创公司,成果远超传统一学期课程项目。
Mollick据此提出"委托决策模型"框架:企业应根据人类完成时间、AI成功概率和处理时间三个维度判断何时将任务交给AI。OpenAI的研究也佐证了这一思路——GPT-5.2在72%的任务中表现优于或持平人类专家,而通过更精准的指令可进一步提高成功率。
1991年:Transformer、预训练、蒸馏与世界模型就已奠基
Sakana AI的hardmaru回顾了一段令人震撼的AI技术史:1991年,在大多数人尚未听说"神经网络"的年代,慕尼黑工业大学Schmidhuber团队在短短数月内发表了多项足以定义现代AI的技术成果。
3月:提出第一种Transformer变体(线性Transformer);4月:提出深度神经网络预训练和蒸馏方法;6月:提出残差学习(后成为LSTM和ResNet的核心机制);8月:发表生成对抗网络与神经网络世界模型。这些论文构成了当前ChatGPT等大语言模型的技术底座。
hardmaru写道,这段历史深刻塑造了他从Google Brain到Sakana AI递归自我改进(RSI)研究的思维方式。David Ha在博客中详细梳理了1991年这段时期的完整脉络。
任务成本差800倍:Claude Fable 5最贵,开源模型性价比最优
不同AI模型执行同类型任务的平均成本差异高达800倍——Claude Fable 5每任务超过31美元,而GLM-5.2和DeepSeek V4 Flash仅约0.04美元。
一份最新的行业基准测试揭示了当前AI模型定价的巨大鸿沟。Claude Fable 5在性能榜单上领先所有参测模型,但其单任务平均成本超过31美元;对比之下,DeepSeek V4 Flash(max)只需约0.04美元即可完成同等任务。在性价比排名中,GLM-5.2(max)与DeepSeek系列等开源权重模型成为最优选择。
这份数据在业界引发了关于"模型成本与可及性"的广泛讨论。随着AI应用从实验室走向生产环境,单次推理的成本已不再是可以忽略的次要指标,而是决定部署规模的核心变量。一位评论者指出,闭源模型的高昂价格可能只适合资本雄厚的科技巨头,而开源生态正在为更广泛的开发者群体打开大门。
Demis Hassabis回顾AlphaFold改变世界的九年合作
DeepMind创始人Demis Hassabis在社交平台向John Jumper致敬,回顾二人长达九年的杰出合作。他写道:"AlphaFold改变了世界,展示了AI在科学与医学领域中无限的可能性。"该推文在24小时内获得逾4400个赞与近40万次浏览。
AlphaFold自诞生以来,已预测超过2亿个蛋白质结构,成为结构生物学最常引用的AI工具之一。Hassabis的致谢不仅是对个人的礼赞,也被业界解读为对"AI for Science"路线的信心重申。
SGLang推理引擎在xAI十万GPU集群为Grok提供推理服务
由Ying Sheng参与编写的SGLang推理引擎,目前以数十万GPU规模的集群在xAI为Grok模型提供推理服务,展现了极强的工程落地能力。SGLang此前还孵化过FlexGen等重磅项目。
这一消息进一步巩固了开源推理框架在超大规模AI基础设施中的地位,也说明社区驱动的工程方案完全有能力支撑世界级部署。xAI选择SGLang作为Grok的推理底座的决策本身即是对开源框架的强烈信任票。
AI Agent正在促进开放API、文档、测试、CLI等健康的软件习惯,让万维网的原始愿景在我们眼前逐渐变为现实。
— Guillermo Rauch, Vercel CEO
Teortaxes:GLM 5.2接近Opus水平,中国团队如何做到?
知名AI评论者Teortaxes在深入试用GLM 5.2后感叹:"它推翻了我对中国在高质量数据上处于灾难性劣势的论点。GLM与Opus的差距太小了,而且他们没花几十亿美元。我不确定怎么做到的——也许蒸馏就是你所需要的全部。"
他补充道,GLM 5.2的表现让他回想起早期AI助手通过蒸馏快速迭代的历史。这一评论在开源社区引发热议,许多开发者认为中国团队正以更高效的训练方法缩小与西方前沿模型之间的差距。
GLM团队透露OPD训练成本极低,被评"最大亮点"

Teortaxes注意到GLM-5.2技术细节中暗示,整个在线偏好蒸馏(Online Preference Distillation, OPD)训练成本相对于预训练和专家RL几乎可忽略不计。他指出这一信息可能比模型性能本身更重要,因为这意味着训练高效模型的技术门槛正在快速降低。
中国大规模研究:用AI做作业反而降低学业成绩
一项涵盖中国大规模样本的研究显示,使用AI完成作业会削弱学生自主思维努力,导致考试成绩下降。研究主题下的一致结论:AI用于课堂辅导有益,但直接替代学生完成作业有害。数据表明,当作业时间因AI使用而减少时,考试成绩同步下滑。
Claude Code修复使用限制错误并重置受影响用户
约3%的Claude Code Max和Pro用户遭遇使用限制错误显示,部分用户无法发送消息。Anthropic团队迅速修复了该问题,并重置所有受影响用户的5小时和每周限额。该公告在24小时内获得逾9200个赞与100万次浏览。
OpenAI o3模型助力罕见遗传病家庭诊断
OpenAI联合创始人Greg Brockman分享了o3模型被用于帮助罕见遗传病家庭的故事。值得注意的是,o3已发布一年多,但仍展现巨大实际价值。Brockman感慨:"难以想象今天的模型将能实现什么。"
Anthropic内部:几乎100%工程师运行超100个自改进Agent
Claude Code创始人透露,在Anthropic内部几乎全部工程师都在运行超过100个Agent,持续进行自改进循环。这一内部实践显示了顶级AI公司已将Agent化工作流作为日常开发范式。
Ethan Mollick:公司低估高级AI模型价值,应建灵活架构
Mollick认为即便弱模型在KPI上已达标,公司也应构建能灵活切换更智能模型的架构,以验证高级模型能否带来更大价值。他警告以"够用"为标准的策略可能在长期丧失竞争力。
Natolambert:SFT方法研究严重不足,但却是后训练基础
AI研究员Nathan Lambert指出,有监督微调(Supervised Fine-Tuning, SFT)作为后训练的关键组成部分,其严肃的实证研究文献却非常稀疏。他呼吁更多研究者投入这一基础但被忽视的领域。
Llama Index发布全球最快PDF转Markdown解析器
Jerry Liu宣布Llama Index团队打造了全球最快且更精确的PDF转Markdown解析器,完全开源且无需调用任何外部模型。该工具解决了AI文档处理中最常见的格式转换痛点,在开源社区引发了广泛关注与转发。
开源9B模型实现近前沿文档结构化提取性能
Vik Paruchuri开源了一个9B参数模型,专门用于从文档中提取结构化数据。该模型在内部基准测试上达到90.2%的准确率,接近前沿水平。这一成果表明中等规模的专用模型在特定任务上可以达到与大模型相当的性能。
Agentic RL常用技术:行动遮蔽与世界模型的结合演进
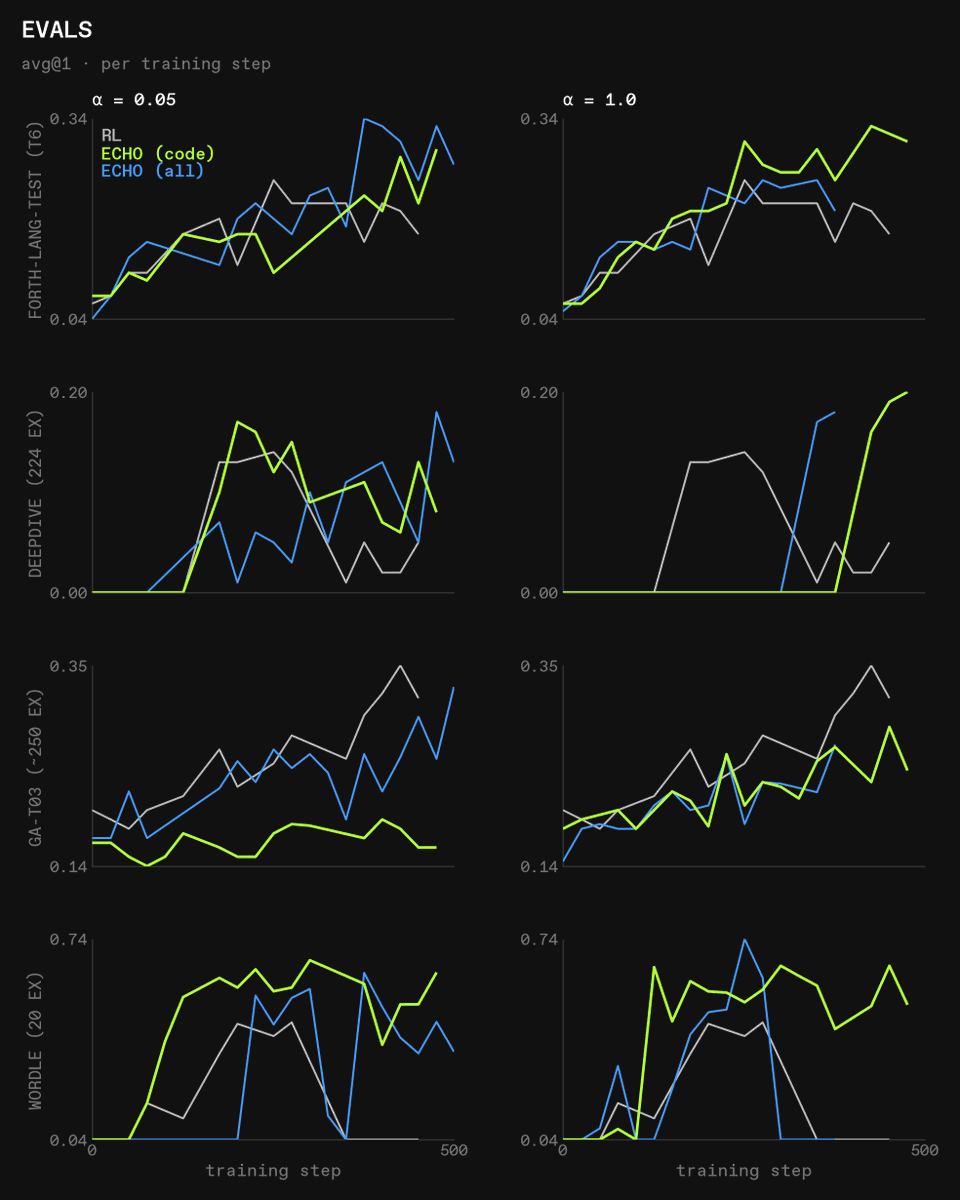
AI研究者C. Wolfe在广泛阅读Agentic RL论文后总结:行动遮蔽(Action Masking)是少数被广泛使用的通用技巧之一,目前正与ECHO和PaW等世界模型方法融合演进。他将这些发现整理为长推文系列,引发了强化学习社区的深入讨论。
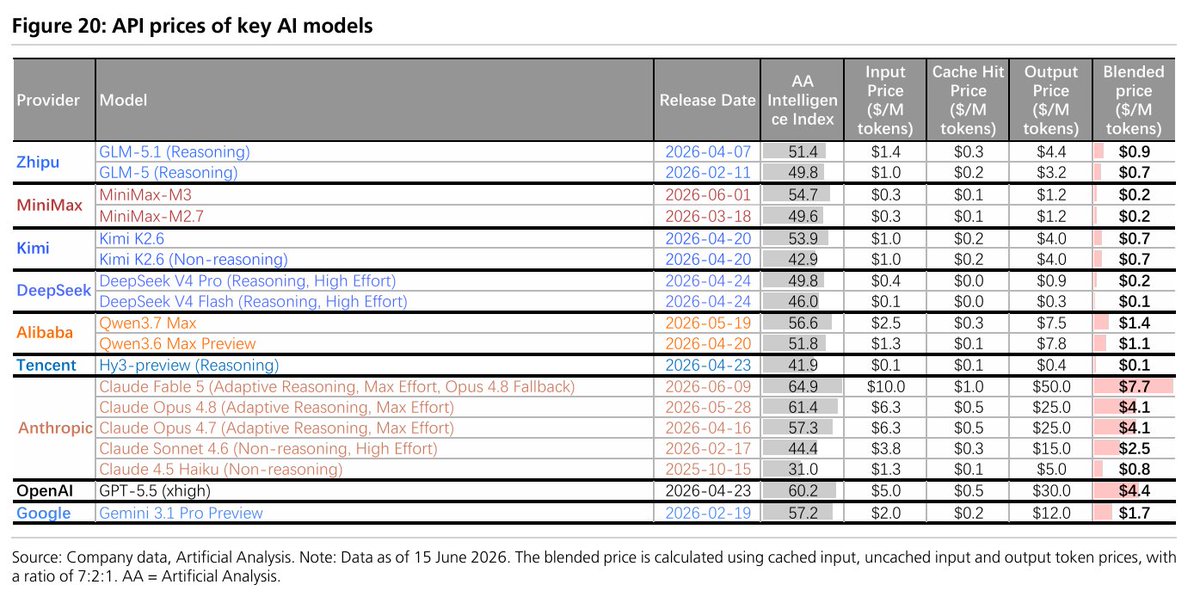
中美关键AI模型API价格对比图引广泛关注
一张对比中美主要AI模型API价格的图表在社交平台上被大量转发,直观展示了不同模型间的成本差异。该图进一步助长了关于开源与闭源模型经济性的讨论。
TRL中GRPO的连续批处理实现更快更省显存
Sergio Paniego宣布连续批处理(Continuous Batching)已登陆TRL for GRPO,在64个生成样本时比普通生成更快,而且显存占用更低。这一改进将直接惠及使用GRPO进行强化学习微调的开发者,降低训练门槛。
黄仁勋用"作坊工人"比喻解释AI Agent的架构

NVIDIA CEO黄仁勋以一个简单比喻拆解AI Agent:模型负责"思考",框架赋予其"形态",工具和技能让其"行动",运行时则提供"完成工作的车间"。这段精炼的解释在开发者中广受好评,24小时内获得近6万次浏览。
Replit与LinkedIn合作展示用户AI构建项目
Replit成为LinkedIn连接应用的功能合作伙伴,用户可将Replit上构建的项目直接展示在LinkedIn资料中。
Recraft API降价12.5%并提速50%
Recraft AI API更新:v4.1及Utility系列降价12.5%至16%,标准模型速度从12秒缩短至6秒,Pro模型同样大幅提升。
Artificial Analysis发布AA-Briefcase智能体知识工作基准
Artificial Analysis推出AA-Briefcase,专门针对下一代智能体知识工作能力进行评估。
Greg Brockman评价Codex应用"非常好"
OpenAI联合创始人Greg Brockman在社交平台上简洁评价Codex应用为"非常优秀",获得约840个赞同与9.5万次浏览。
单台DGX Spark实现16路并行Gemma-4模型推理
通过DGX Spark(128GB统一内存)成功同时运行16个Gemma-4-26B模型,聚合吞吐量达300 token/s,展示边缘推理的强大潜力。