OpenAI Daybreak 扩展安全功能,发布 GPT-5.5-Cyber 模型
OpenAI 扩大 Daybreak 项目,推出 Codex Security 插件和完整版 GPT-5.5-Cyber 模型,专注于以机器速度自动化修补脆弱软件。
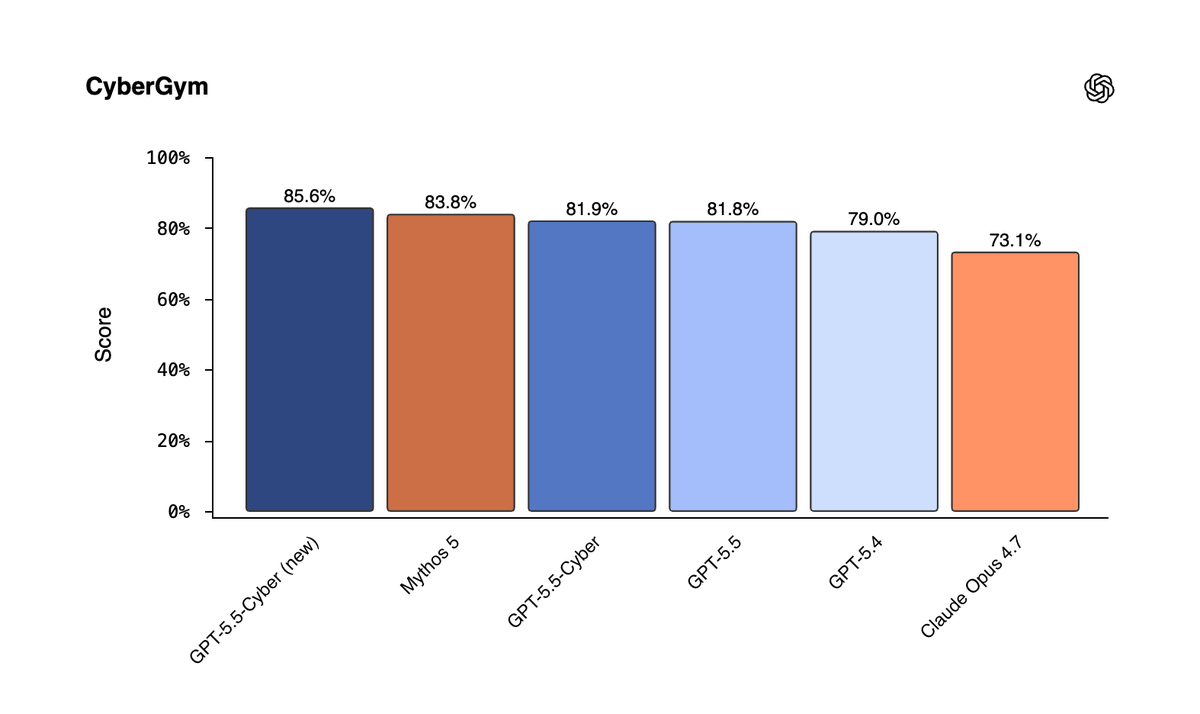
OpenAI 宣布扩展其 Daybreak 安全项目,正式推出 Codex Security 插件和完整版 GPT-5.5-Cyber 模型。此次发布旨在帮助所有公司以机器速度实现漏洞修复自动化。Codex Security 插件可在 Codex 内直接查找、验证并修复安全漏洞;GPT-5.5-Cyber 模型在 CyberGym 基准测试中达到顶尖表现,专为值得信赖的防御体系设计。Sam Altman 同时详细介绍了 Patch The Planet 计划,联合专业安全研究员保护关键开源软件,并推动了 Cyber Partner 计划的协作。
Sam Altman 确认 GPT-5.5-Cyber 发布,Codex 安全插件上线
OpenAI CEO 详解安全计划:完整版 GPT-5.5-Cyber 模型在 CyberGym 上实现顶尖性能,Codex Security 与 Patch The Planet 从发现漏洞转向解决漏洞,联合美国政府及安全生态推进。
Perplexity CEO 盛赞 GLM-5.2:盲测超越前沿模型,复兴开源 AI
Arav Srinivas 称 GLM-5.2 在盲测中超过前沿模型,是子万亿参数模型,服务成本低,重燃对开源 AI 的兴趣。他还预告多个万亿参数级开源模型即将到来,认为这将利好 Token 定价并验证杰文斯悖论。
如果你关心开源,现在是时候告知监管者如何构建一个安全、前沿、开放智能的世界。
— Nat Lambert,研究者
Sakana AI 发布 Fugu:全自主多 Agent 编排系统
Sakana AI 推出 Sakana Fugu,一个通过单一模型 API 实现的完整多 Agent 编排系统。Fugu 本身是一个 LLM,训练用来调用 Agent 池中的其他 LLM 实例,实现多 Agent 协调。Fugu Ultra 版本与 Fable、Mythos 在最严格工程基准测试中表现相当。但 Ethan Mollick 实测称 Fugu Ultra-high 运行极慢,典型编程测试需 30 分钟,实际效果不如 Fable。
Cursor 在 Compile 大会宣布与 SpaceX 合作训练新模型
Cursor AI 在 Compile 主题演讲中公布三项重大公告,其中包括与 SpaceX 合作训练全新模型的计划,此外还有两项产品更新,引发业界广泛关注。
Grok 现已连接盈透证券,实时提供投资组合信息
xAI 推出 Grok 与 Interactive Brokers 集成,用户可获取高质量、最新的投资组合信息。Elon Musk 同时宣布 Grok Build 升级,新增 /goal 命令,支持自主执行多轮子代理长周期任务。
NVIDIA 称 AI 数据中心用水量仅占全美 0.2%
NVIDIA 引用曼哈顿研究所数据称,美国数据中心日用水量仅占全国每日用水的 0.2%,且因新型冷却技术已有大幅下降。Perplexity CEO Arav Srinivas 补充指出,数据中心液冷边际水耗近乎为零,常见误解混淆了发电用水与冷却用水。
Sakana 推出媲美 Claude Fable 5 的 Fugu 模型
日本 AI 实验室 Sakana 发布 Fugu 模型,性能匹配 Claude Fable 5。
Cline 用真实 bug 测试 GLM-5.2 vs Opus 4.8
Cline 团队对基准测试持怀疑态度,用真实 bug 实测两者对比。
GLM 5.2 印象:执行力强但缺乏灵感
被评"是先生"型模型,执行力强但缺乏主动探索的灵感。
GLM-5.2 通过 AWS Marketplace 提供 API 服务
GLM-5.2 通过 AWS 上的 GLM API 提供服务,支持长周期自主任务。
GLM 5.2 在 B300 上跑得比 Gemini-Flash 更快更便宜
模型层与硬件层分离,B300 上达到更高性价比。
Fugu Ultra 实测:极慢,效果不如 Fable
Ethan Mollick 测试常规编程需 30 分钟,效果一般。
AI2 发布 TMax 27B 终端 Agent
在 Hugging Face 上发布,Terminal Bench 2.0 达 42.7%,与更大模型竞争。同时发布 Qwen 3.5 9B 终端 Agent,基于 DPPO 算法训练。
TMax:面向终端 Agent 的开放 RL 方案发布
Nat 分享了终端 Agent 强化学习新论文,强调 2026 年的 RL 研究已大不相同。
博客综述 10+ Agentic RL 框架关键要点
博文总结模块化接口、多轮自主交互及 Qwen3 通过 XML 分隔符实现工具调用的最佳实践。
MIT 许可 GLM-5.2 在 Agentic 任务上击败 GPT-5.5
以 MIT 许可发布,在真实世界 Agent 任务表现优于 GPT-5.5(xhigh),可于 Hugging Face 免费使用。
Gray Swan 播客:后 Mythos 时代的红队测试与 AI 安全危机
联合创始人讨论 AI 安全挑战,认为 AI 安全不是传统网络安全加 AI,需要全新方法。
Google 投资 7500 万美元与 A24 开展 AI 研究合作
Google DeepMind 与电影公司 A24 达成研究合作,探索 AI 工具在创意领域的应用。
Hugging Face 即将突破 300 万模型与 100 万数据集
Clement Delangue 宣布平台即将达到里程碑,开源 AI 发展迅猛。
Neuralink 已有第 26 位植入者
一名因 ALS 瘫痪的警察成为最新受体,展示脑机接口最新进展。
Vercel 推出 Vercel Flags,部署与发布解耦
平台原生功能开关工具,代码合并与功能发布分离,对页面性能零影响。同时宣布支持 WebSocket 和 socket.io,AI Gateway 集成 Mythos 级智能。
编程不仅仅是写代码,更是通过抽象层次管理复杂性的艺术与科学,AI 只是工具之一。
— François Chollet,Keras 创始人
Sakana 创始人:最强 AI 系统应成为集体智能
David Ha 认为人类智能本质是集体智能,最强 AI 系统也应成为集体智能。
Fable 在贪吃蛇游戏中展现创造性与判断力
Ethan Mollick 测试 Fable 制作自我意识贪吃蛇游戏,仅要求"让它更好",AI 展现出色的问题解决能力。
Fable 事件十天后依然扑朔迷离
相关报道和文章相互矛盾,情况仍不明朗。但分析称 Fable 有效参数极少却性能卓越。
Midjourney 草稿模式单次生成 24 张角色变体
新 Draft Mode 极大提升创作效率,一次运行生成 24 张低分辨率角色变体。
蒸馏前沿模型成本:400 万美元可获 1T 数据
蒸馏 Opus 4.8 用 400 万美元即可获取约 1T token,成本相对低廉。
传闻 Anthropic 已完成更强 Mythos 模型训练
未确认消息称 Anthropic 已完成更强大的 Mythos 模型训练。
Google DeepMind 的算力优势正在缩小
领先优势已从 100 倍降至 10 倍,DeepMind 可能真的会输。
推理成本每 Token 变便宜,总支出在增加
Sarah Hooker 转推指出:AI 推理每 Token 成本下降但总支出增长,因为能力越强使用越频繁。
Claude 对用户健康过度关心
用户反映 Claude 得知其肠胃不适后,在无关对话中仍不断出现关心提醒且无法制止。
AI 可能摧毁电影行业昂贵视觉效果的垄断
技术革命摧毁行业存在的理由——摄影摧毁了绘画对现实主义的垄断,AI 可能对昂贵 VFX 做同样的事。
Cohere CEO 强调主权 AI 方案的重要性
Aidan Gomez 在 FII 会议上表示,没有主权 AI 方案,关键基础设施随时可能被关停。
GLM 5.2 缩小私测差距,整体差距约 7 个月
在困难私测上大幅缩小与前沿模型差距,整体差距约 7 个月即可追赶。