llama.cpp MTP 让本地模型推理提速78%
多 token 预测技术正式落地,Qwen3.6-27B 在 A10G 上从 25 tok/s 跃升至 45 tok/s,本地 AI 迈入日常可用时代。
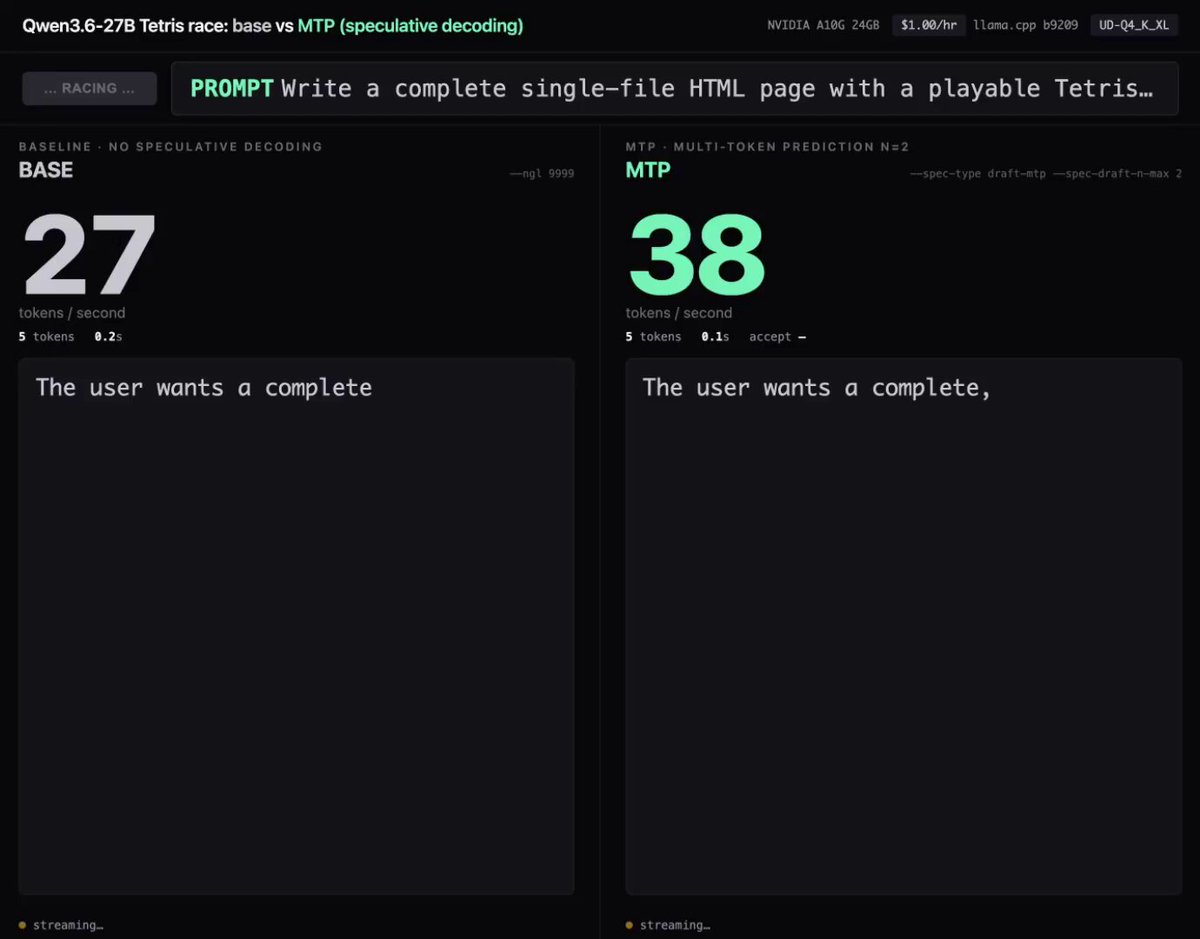
llama.cpp 近日正式集成多 token 预测支持。在单张 NVIDIA A10G GPU 上实测,Qwen3.6-27B 稠密模型的文本生成速度从每秒 25 token 飙升至 45 token,性能增幅高达 78%。Hugging Face 联合创始人兼 CEO Clement Delangue 评价称,这一突破使本地大模型快到足以成为开发者每日依赖的基础工具。对于追求数据隐私和离线推理的用户,MTP 极大降低了在本地运行高性能大模型的门槛,本地 AI 正在从"勉强可用"迈向"流畅日常"。
LongCat 开源 SOTA 说话头像模型
MIT 协议开源,口型同步与表情达业界领先。
LongCat 发布了当前最先进的开源说话头像模型,采用 MIT 许可证,已在 Hugging Face 平台正式上线。该模型在口型同步精度和面部表情自然度方面处于领先水平,是文本转语音头像领域的重要开源贡献,为开发者构建虚拟数字人和交互式 AI 形象提供了高质量的基础组件。
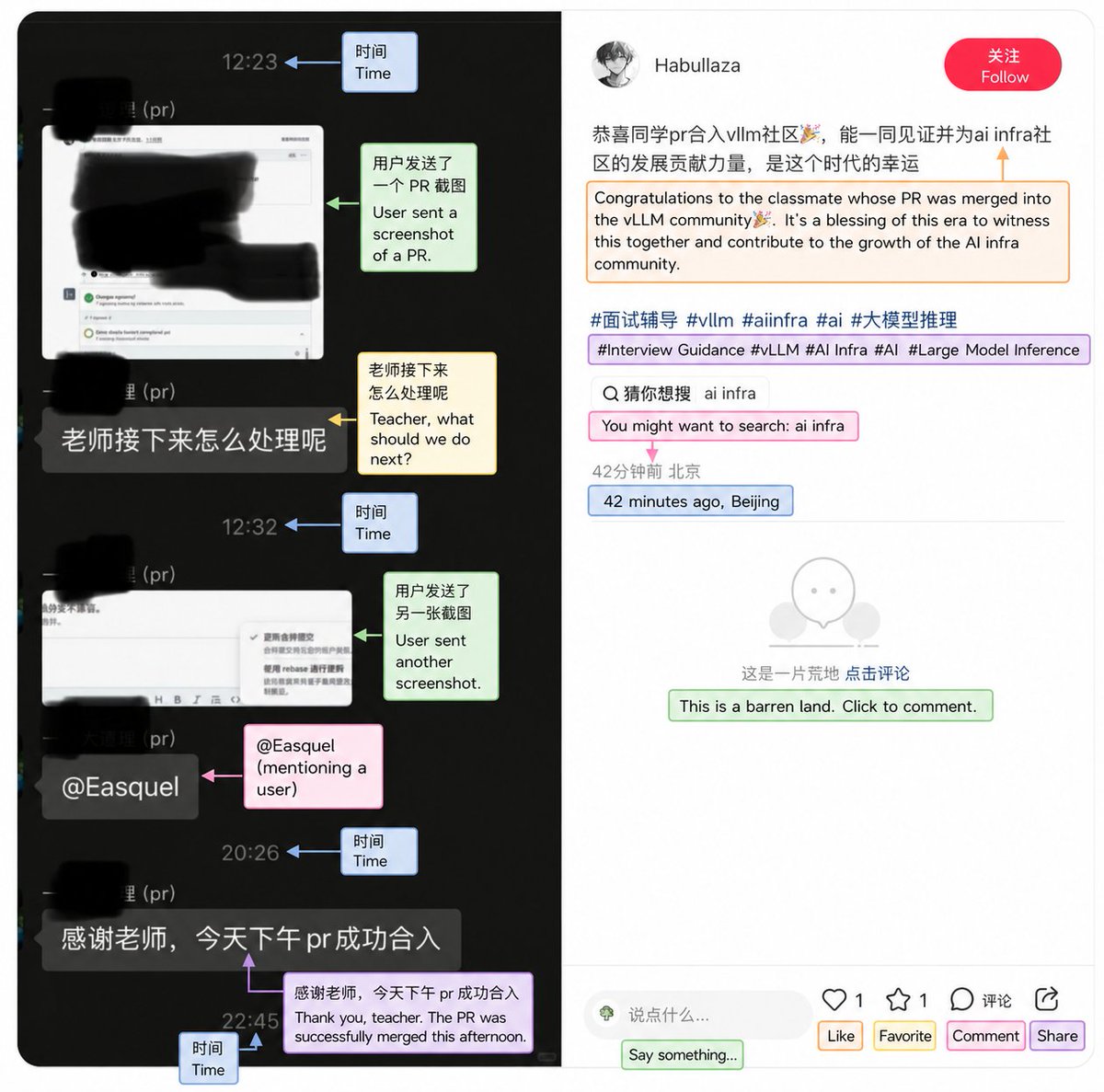
vLLM 遭虚假 PR 渗透,社区果断封禁
vLLM 项目团队发现一个来自所谓"PR 训练"工作流的恶意提交,该 PR 试图修复一个根本不存在的问题,目的仅为填充个人简历。社区随即封禁该贡献者并回滚所有变更。同一合并周期中,修复 NVIDIA Eagle3 检查点加载问题的有效 PR 也顺利合入。

Luma Agents 规模生成真实感 UGC 广告
Luma 发布 Luma Agents,一种创意代理工具,可根据用户定义的文案和风格,大规模生成具有真实感的 UGC 风格广告。该工具覆盖从规划、生成到迭代完善的全流程,旨在成为创意团队的效率倍增器,让真实感广告创作从矛盾走向可能。
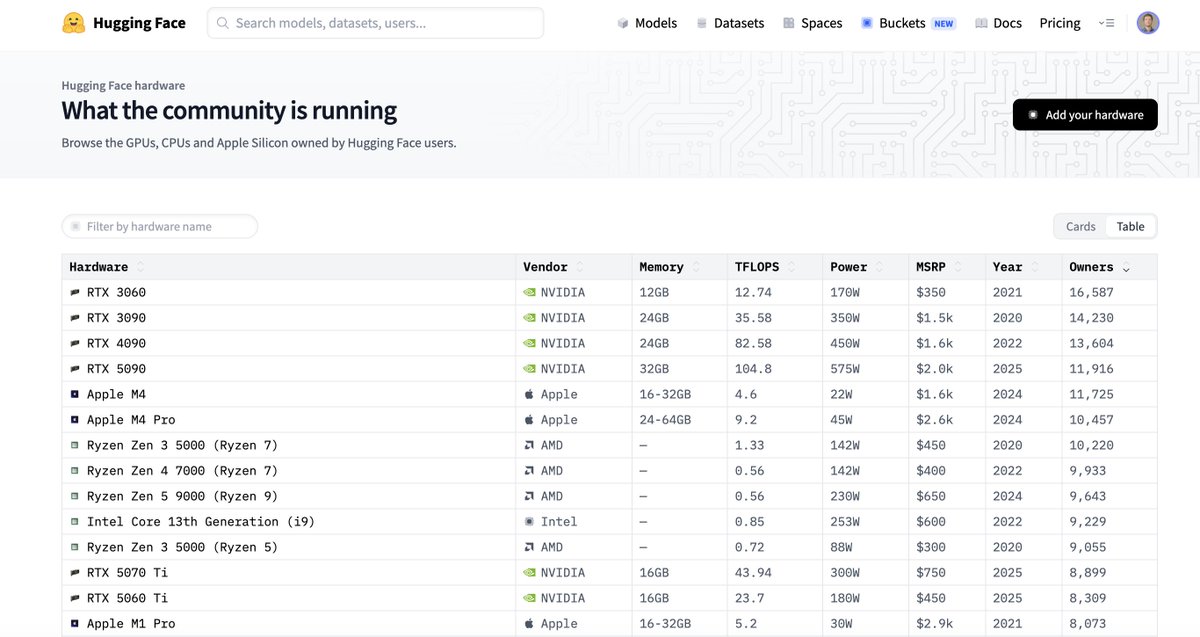
30 万 AI 开发者硬件画像
Hugging Face 公布 30 万开发者硬件统计:NVIDIA 主导,RTX 3060 12GB 最流行(1.7 万用户)。RTX 30xx 与 40xx 各占 27%,Apple Silicon 占比显著。
Replit 结合 AI 编程工具迅速构建 MVP
开发者使用 Cursor 和 Replit 的 Dial 功能,一个周末构建出 MVP,并一次性通过苹果应用审核——这在之前从未发生过。
DeepSeek-V4-Flash 自研视觉功能
DeepSeek-V4-Flash 在未获官方支持的情况下自主实现了视觉能力,并在此过程中意外修复了一个常见错误,展现出模型的自适应潜力。
AI 工具通过杰文斯悖论使优秀工程师效率提升 10 倍,让我们能解决更困难的问题。我们正在扩招软件工程师。
Sakana AI 研究员 hardmaru
6 人团队打造比 GPT 快 4-8 倍的专用 AI 模型
一家仅 6 人的公司正在构建特定任务 AI 模型,速度比 OpenAI 或 Anthropic 的通用模型快 4-8 倍,已获 50 万次下载。
Anthropic Workshop 展示运行数小时的 Agent
Anthropic 发布 workshop,展示如何构建能运行数小时而非数秒的长生命周期 AI 代理,提供 75 分钟完整课程。
AGIBOT 发布第二代行为基础模型 BFM-2
AGIBOT 发布 BFM-2,被称为"机器人肌肉记忆",旨在提升机器人的行为基础建模与动作泛化能力。
SEGA:扩散模型的频谱能量引导注意力
新论文 SEGA 提出频谱能量引导注意力机制,用于扩散 Transformer 的分辨率外推,可提升图像生成质量。
PapersWithCode 平台新增多项功能
上线一周的 PapersWithCode 已增加对视频、PDF、Hugging Face 模型等的支持,迅速迭代。
AI 进化受多重因素影响,不仅靠算力
研究指出,社会动态、政策、开放科学等对 AI 进化也有重要影响,仅聚焦大公司算力是片面的。
研究者与工程师的区别:问题可解性
一种观点认为,研究者研究可能不可解的问题,而工程师解决被认为是可解的问题。
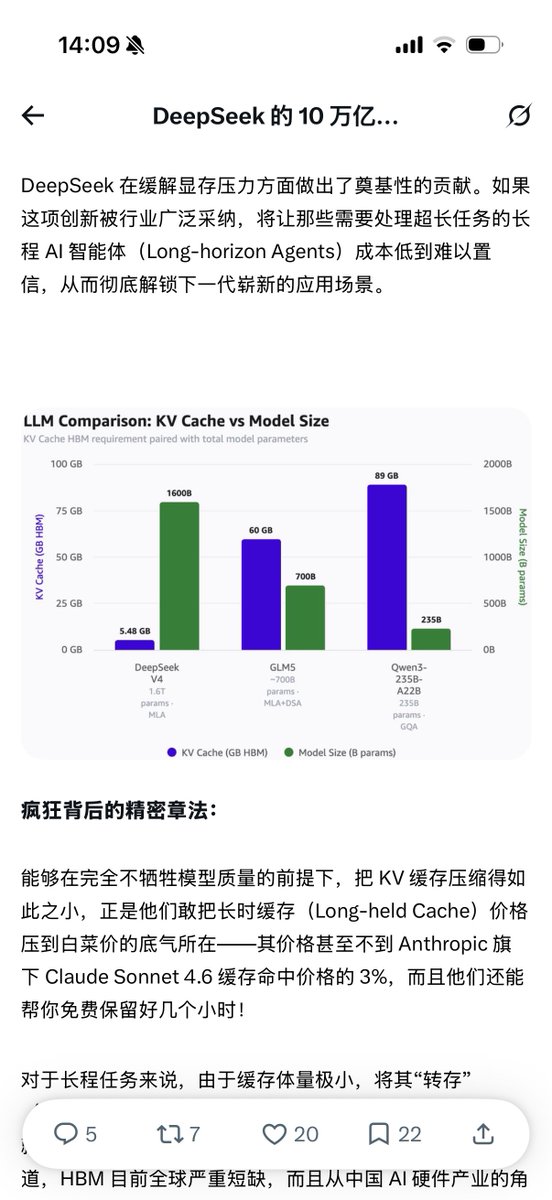
DeepSeek V4 Pro 缓存成本极低
分析显示 DeepSeek V4 Pro 虽不是最强模型,但缓存几乎免费,可大幅降低推理成本,类似技术可让 Opus 成本降 10 倍。
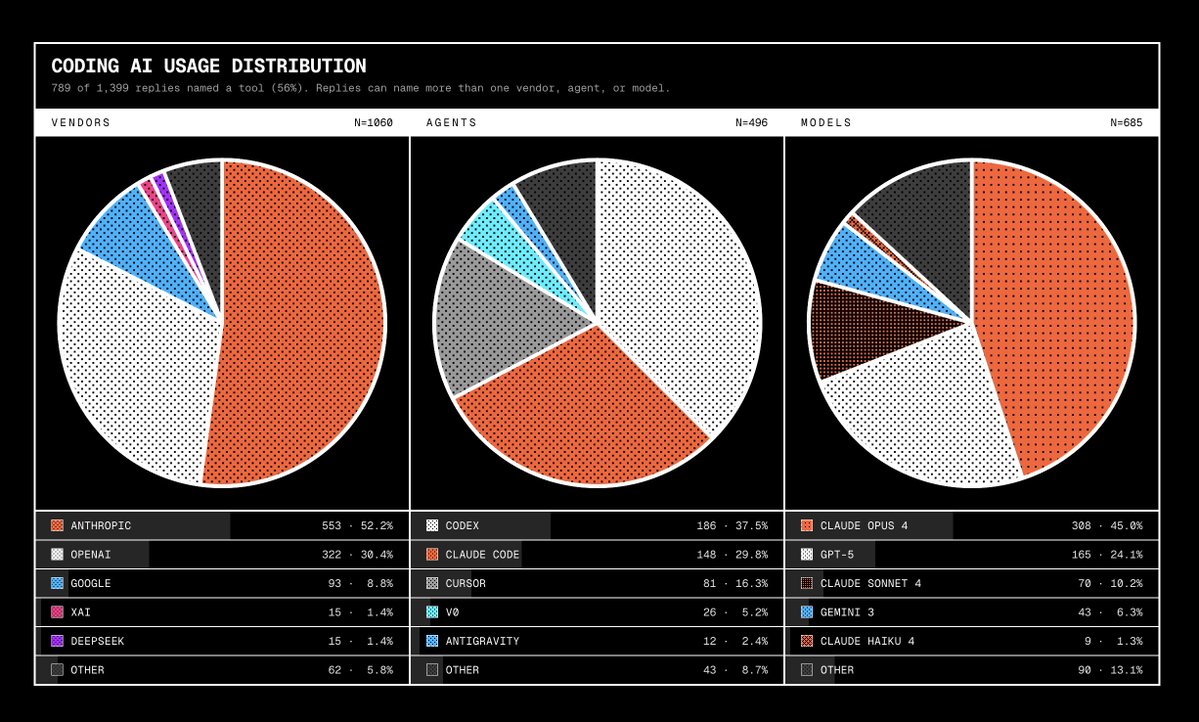
调查显示 OpenAI 正在追赶 Anthropic
对 1400 条回复的分析显示,OpenAI 正在追赶 Anthropic,Codex 的提及次数已超过 Claude Code。
Hugging Face 发布约 2500 美元开源人形机器人
LeRobotHF 项目发布成本约 2500 美元的人形机器人,提供完整的软硬件开源堆栈,大幅降低机器人开发门槛。

MiniMax 语音 2.8 赋能意大利犯罪剧配音
亮相戛纳电影节,AI 语音覆盖地区口音与个性特征。
MiniMax 的 Speech 2.8 语音技术在戛纳电影节亮相,被用于意大利犯罪剧《Il Cinese》的沉浸式配音制作。该技术可精准呈现从细微地区口音差异到个性化声音特质的多层次表现,标志着 AI 语音合成在专业影视制作领域的进一步渗透。