Vercel CEO盛赞GLM-5.2编码能力,称"这将改变格局"
Vercel CEO Guillermo Rauch(@rauchg)公开发文表达对GLM-5.2编码能力的震惊与深刻印象,称"genuinely impressed, almost shocked",并表示该模型的出现将改变行业格局。Rauchg是继多位AI研究者之后,又一位对GLM-5.2给出极高评价的业界领袖。GLM-5.2由智谱AI(Zhipu AI)发布,在编码任务上的表现令Vercel工程负责人也深感意外,其实际编码能力被认为已接近或超越当前闭源旗舰模型。
MaineCoon:首款社交互动视频模型,22B参数单卡H100实时生成
François Chollet(Keras作者)推介了MaineCoon——业界首个聚焦社交互动的视频生成模型。该模型专注于面部表情、情绪传递、流畅对话及音画同步,在单张NVIDIA H100上以47.5 FPS实时生成,推理成本低于每秒0.001美元。22B参数的轻量设计使其在消费级推理场景中具有显著优势。Chollet认为这代表了视频模型从"炫技"走向"叙事"的重要转向。
"Genuinely impressed, almost shocked, at how good GLM-5.2 by @zai_org is at coding. This changes things."
— @rauchg, Vercel CEO
GPT-5.5分析20年前论文:发现错误并更新分析
Ethan Mollick将自己在研究生时期发表的第一篇论文交给GPT-5.5 Pro,要求其查找错误并更新研究。模型不仅发现了新的数据来源,完成了独立分析,还创建了可复现的分析文件,并将关键论点进一步扩展。这一实验揭示了前沿模型在学术研究中的巨大潜力——AI不再仅仅是辅助工具,而是可以独立完成文献批评与方法论迭代的研究加速器。Mollick指出,AI与过往学术工作的交互方式将会变得愈加奇特。
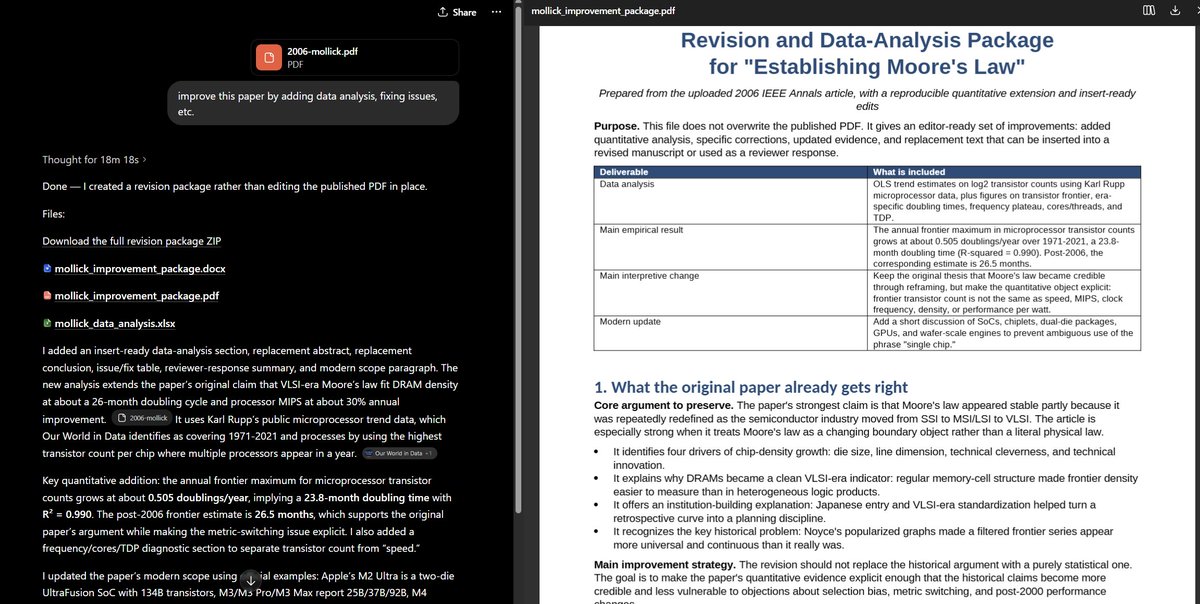
将编程CoWork模式扩展到知识工作存在根本问题
Ethan Mollick深入分析了将Codex/Cowork/Code等编程协作范式推广至所有知识工作的根本性障碍:这些工具天生"软件思维"——以最终产出(软件代码)为唯一真理来源。然而对大量知识工作而言,过程比结果更为重要。撰写策略备忘录、设计研究方案、构思商业计划等任务的价值往往体现在思辨过程中,而非最终文档本身。Mollick认为,当前Agent工具尚未解决"过程中断"与"认知所有权"两类核心问题,这是Agent产品设计的下一道门槛。
GLM-5.2让开源模型在编码实用性上超越Gemini
Natolambert指出,在GLM-5.2推动下,开源权重模型首次在编码实用性方面全面超越Gemini,距Opus 4.5发布约200天。
GLM-5.2在Blackwell上实现120 tok/s高吞吐
据可靠来源,GLM-5.2在两台联网Blackwell tinybox上以每秒120 tokens运行,总硬件成本约15万美元。
GLM-5.2在Claude Code中表现超越Opus 4.8
用户报告称GLM-5.2在Claude Code编程环境中性能超过Opus 4.8,多位测试者表示"令人震惊"。
GLM-5.2在研究加速方面表现卓越
teortaxesTex指出GLM-5.2可能在研究加速场景中直接成为最佳选择,在某些任务上超越封闭源模型。
GLM-5.2在Vending Bench上表现优异
GLM-5.2在Vending Bench商业运营基准测试中展示了强大的综合运营能力,给用户留下深刻印象。
Natolambert初步测试GLM:设置简单表现扎实
Natolambert在Fireworks AI上仅用5分钟即完成GLM模型部署并在Claude Code中开始使用,称赞其易用性。
GLM-5.2侧重软件工程,DSV4.1将主攻数学
分析指出GLM-5.2主要面向软件工程场景,数学增益不稳定;DeepSeek V4.1将在数学领域展现惊人进步。
中国开源模型仍远未达到LLaMA 3.1 405B预训练计算量
尽管表现亮眼,尚无一款中国开源模型使用过LLaMA 3.1 405B预训练计算量的三分之一,能力仍落后23个月前的Meta模型。
MiniMax M3与Hermes Agent在虚幻引擎5.8展示Agent能力
MiniMax M3模型与Hermes Agent在Unreal Engine 5.8 MCP环境下进行了45分钟自主交互,完整展示Agent在复杂3D环境中的规划与执行能力。
DeepSeek文锋被赞融资中拒绝中东LP,彰显开源承诺
投资者称赞文锋在融资中主动调查投资者背景并拒绝中东壳公司LP,展现了绝对的开源承诺和对投机资本的蔑视。
传闻DeepSeek前员工因Agent方向分歧离开
消息称核心成员因未能说服文锋更早聚焦Agent而离开,如今DeepSeek全面投入Agent训练,团队仍在组建中。
工程路径:成为顶级AGI实验室只需组合现有技术
teortaxesTex提出纯工程路线:组合DeepSeek V3.2注意力、Kimi K2模型形状、100T token预训练和zAI Slime后训练框架,即可跻身前三AGI实验室。
澄清:Zhipu的GLM-5并非完全基于国产芯片训练
据澄清,仅GLM-Image在Ascend芯片上训练,GLM-5仅适配了国产推理硬件,并未完全使用国产芯片进行预训练。
揭秘:前沿AI实验室花费数十亿美元注释数据
前沿AI实验室正以数十亿美元雇用诗人、音乐家、会计师等大量专业人员,对各种格式进行大规模数据注释,这是一场蛮力押注。
Clement Delangue认为开源AI领导力是通用AI领导力的前提
Hugging Face CEO预测:2016-2024美国领先开源,2024-2026中国领先开源,2024-2027美国领先通用AI。开源领导力是通用AI领导力的先决阶段。
观点:Nvidia是潜在的一流AI实验室
teortaxesTex认为Nvidia具备成为一级AI实验室的潜力,建议CEO Jensen Huang开始从其他实验室挖角人才。
递归自我改进(RSI)的三个早期步骤总结
Anthropic将80%代码通过AI合并、其他AI公司也在实践递归自我改进,文章总结了RSI的早期步骤与关键节点。
研究:物理合理性信号隐藏在冻结图像编码器中
研究者发现可从未经视频训练或物理监督的冻结图像编码器几何结构中提取物理合理性信号,暗示了感知系统的新可能性。
用户测试全新AI系统模型,称"人类又朝前迈进了一步"
用户oran_ge在测试一款全新系统模型后表示激动,称其充满想象力,认为这标志着人类向前迈出了重要一步。
研究指出LLM逐步规划输出创造推理错觉
当LLM输出逐步计划时,会产生强大的机器推理错觉,但该研究指出实际机制可能并非真正的逻辑推理。
观点:LLM的世界理解是语言建模的副产品
François Fleuret认为目前LLM的任何"世界理解"都是语言建模的隐含副产品,类似于人类对抽象数学对象的理解。
LlamaIndex提出Agent原生文档格式需求
随着Agent生成大量文档,需要更适合Agent的文档格式,LlamaIndex讨论了两种主要候选方案。
报告称欧洲无法通过租赁实现AI主权
欧洲AI投资报告指出,欧洲不能仅靠租赁AI基础设施来实现技术主权,必须自主建设核心能力。
研究者称当前机器人学如同2023年语言模型热潮
机器人学研究者认为该领域处于类似语言模型2023年的状态——各方尝试多种方法,尚未收敛到统一范式。
DeepSeek被称为AI模型的"死亡门槛"
评论称如果某模型仅比DeepSeek略好则无法生存,因为DeepSeek定价极其低廉,形成市场化的准入门槛。
François Chollet认为AI普及推动SaaS需求增长
Keras作者认为尽管存在颠覆叙事,真正运营公司的人会发现AI应用实际上增加了对SaaS的需求。
讨论将Nvidia Blackwell推向物理极限的可能性
用户讨论了训练中矩阵问题的Alpha信息,以及如何将Nvidia Blackwell的计算能力推向物理极限。
Graham Neubig质疑递归自我改进公司的定义
研究者认为所有构建AI编码代理或LLM的公司都在使用自己的产品,那么所有AI公司都算递归自我改进公司吗。
研究员讨论图像与语言本质差异对LLM的挑战
François认为图像的强冗余性和组合性使其成为绝佳记忆库,而语言缺乏这些属性,给LLM带来巨大挑战。
AI4S研究趋势:自我进化循环与多智能体系统
当前AI for Science研究包括自我进化循环、多智能体系统、Agent技能和科学基准,旨在实现文献发现循环。
研究员对比新架构与标准Decoder Transformer性能
在正确归一化FLOPs和内存后,比较新架构与标准Decoder Transformer的性能差异。结果令人深思。
中国开源LLM被批评但不涉及政治宣传
用户指出中国开源LLM被鹰派批评传播价值观,但实际只有象征性微调,在国内可能才是更大的问题。
LottoLabs分享训练模型最佳读物
推荐一篇关于训练模型的优秀文章,适合希望开始模型训练的用户阅读入门。
开源Swift实现Codex Computer Use权限流程
名为permiso的开源Swift项目实现了Codex Computer Use的辅助功能权限对话框交互流程。
IIT Bombay和BharatGen参与开放AI建设
印度IIT Bombay和BharatGen宣布参与Project Tapestry,支持构建基于本土语言和知识的前沿AI。