xAI 集成 Grok 与 Hermes Agent
支持 X Premium 订阅与平台搜索能力,Hermes Agent 成为首个获官方接入 Grok 的开源自改善代理
xAI 已将 Grok 与 Nous Research 的开源自改善 Hermes Agent 集成。用户现可在 Hermes Agent 中使用 X Premium 订阅,该代理也获得了搜索 X 平台帖子的能力。这标志着开源 Agent 框架首次获得顶级闭源模型的官方 API 接入,为开发者提供了更灵活的工具链组合。
vLLM v0.21.0 发布

vLLM v0.21.0 带来 KV Offload、HMA、推测解码思考预算、TOKENSPEED_MLA 等新特性,并支持 DeepSeek V4 流水线并行。Mooncake 分布式 KV 与 C++20 迁移成为工程亮点,覆盖从 Blackwell GPU 到推理模型的完整管线优化。

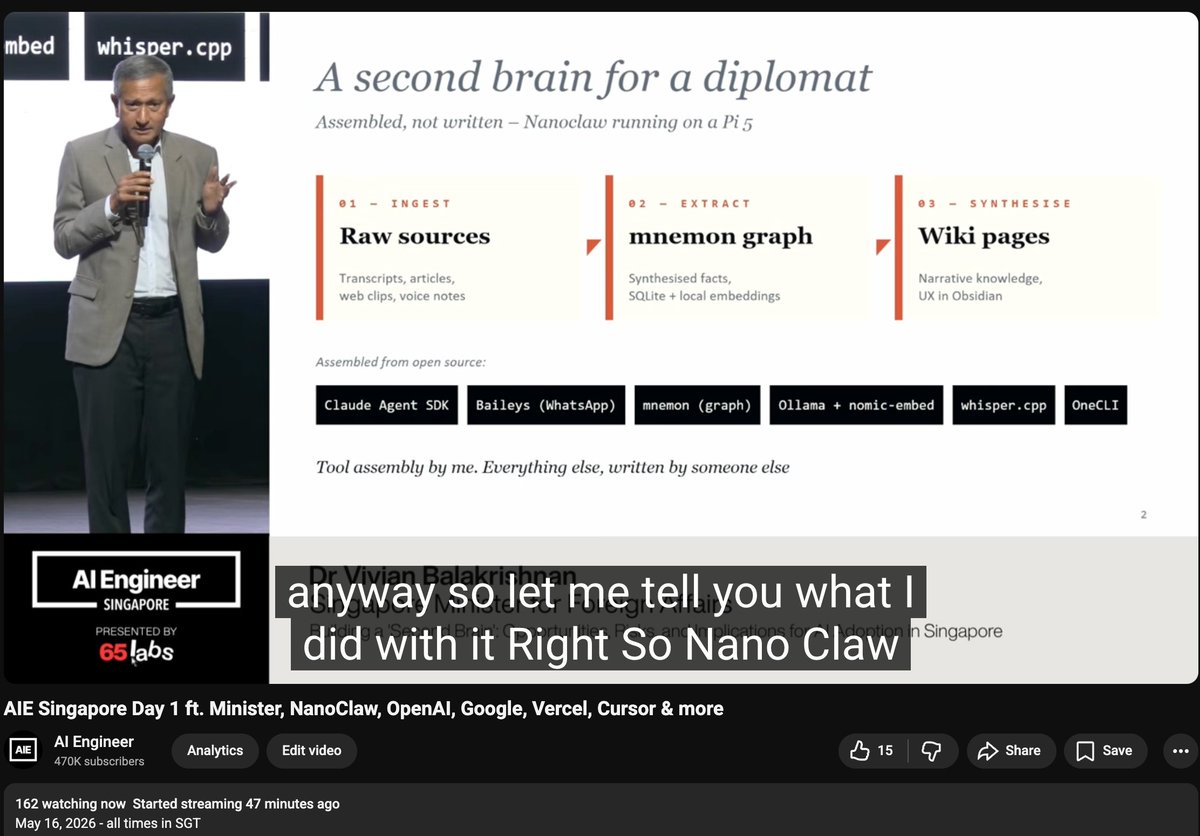
视觉解读 LLM 长上下文架构新演进
Sebastian Raschka 发布博客,以 Gemma 4、DeepSeek V4 为例,详解跨层 KV 共享、逐层注意力预算等长上下文效率优化方法
该博客概述了近期开源 LLM 在长上下文效率方面的架构改进,重点分析了四种关键技巧:Gemma 4 的跨层 KV 共享(后层复用前层的键值投影)与逐层嵌入;Laguna XS.2 的逐层注意力预算分配;ZAYA1-8B 的压缩卷积注意力;以及 DeepSeek V4 的多头压缩(mHC)与压缩注意力。这些设计均以降低 KV 缓存大小、内存带宽和注意力计算成本为目标,从而在有限硬件上支持更长的推理上下文。
30B-A3B 推理模型:物理数学奥赛达金牌水平
30B 总参数仅激活 3B 的推理模型,在物理与数学奥林匹克评估中双双斩获金牌级成绩
共一作者发布的 30B-A3B 推理模型采用了稀疏激活架构,以仅 3B 的活跃参数量在物理和数学奥林匹克基准测试中同时达到金牌级别表现,展现了稀疏推理模型在高难度学科推理上的突破潜力。
DCI 检索方法登顶 HF 每日论文榜首
无需嵌入模型或向量索引,以 grep、bash 等通用工具直接搜索原始文本,大幅超越传统基线
DCI(直接语料交互)方法让智能体使用 grep、bash 等通用工具直接搜索原始文本,无需嵌入模型、向量索引或离线索引。在 BRIGHT、BEIR 等多个检索基准和端到端智能体搜索任务中,DCI 显著优于传统稀疏、稠密及重排序基线,平均提升 11% 至 30.7%。研究表明,检索质量不仅依赖推理能力,更取决于模型与语料交互接口的分辨率。

Codex 键盘快捷键现可自定义
OpenAI 根据用户反馈更新 Codex,用户现可在设置中自定义快捷键以匹配个人工作流。
NVIDIA 发布论文审阅数据集
NVIDIA 在 Hugging Face 上发布包含 APRES、Agents4Science 和 Sakana v2 子集的论文审阅数据集。
INF 开源模型登顶文档理解榜
INF 发布 InfiMM 和 InfiMM-Web 两个开源权重模型,在文档理解排行榜上取得领先成绩。
如果你不为自己正在研究的问题本身着迷,你不太可能成功。内在动机远比外部奖励更强大。
— François Chollet
中国电信推出 Token 话费套餐
1 元兑换 25 万 Token,支持 30+ 主流大模型,话费账单直付。中国电信称 Token 服务将成为经营主线。
深度分析 X 平台推荐算法
Javilopen 花费 500 美元调 Claude 逐行分析 xAI 开源的 X 推荐算法,发现每个账号均附有描述性嵌入。
预测基准:可扩展、难作弊
TeortaxesTex 认为预测类基准天然可扩展、不可作弊且难以饱和,应获更多重视。
Slides Arena: Anthropic 与 ZAI 领先
在幻灯片生成竞技中,Anthropic 和 ZAI 的模型在软验证测试中表现最佳。
Replit AI Agent 助力持续交付
一名设计师利用 Replit 的 AI Agent 在 18 个月内几乎每日发布产品,展示低代码 AI 工具的实际效能。
ChatGPT Plus 马耳他全面开放
OpenAI CEO 宣布马耳他全国均可使用 ChatGPT Plus 订阅服务。
TOKENSPEED_MLA 集成至 Blackwell
Lightseek 宣布 TOKENSPEED_MLA 已整合进 vLLM,优化 DeepSeek-R1 和 Kimi-K2.5 在 Blackwell GPU 上的推理性能。
开放模型汇总:Gemma 4、DeepSeek V4
Interconnects.ai 发布第 21 期开放模型快讯,涵盖 Gemma 4、DeepSeek V4、Kimi K2.6、MiMo 2.5 等新模型。
CAISI 与 Epoch AI 对开放模型评估分歧
美国 CAISI 与 Epoch AI 在开放与封闭模型性能差距的评估结论上出现不一致。
Grok CLI + Vercel 插件实现云部署
Vercel 创始人展示 Grok CLI 安装 Vercel 插件后,可一键将创意编程网站生成并部署至云端。
Vercel 以 SSO 保护 Agent 部署
Vercel 通过 Okta SSO 保护 Agent 生成的部署,包括生产环境,构建 Agent 应用的"安全内网"。
Zero:面向 Agent 的编程语言
CtaTeDev 推出 Zero 语言,定位为更快、更小、更易被 AI Agent 生成的系统级语言。
KempeLab 负责人将离开 Meta FAIR
专注于 LLM 推理研究的 KempeLab 负责人宣布即将离开 Meta FAIR,任职约两年。
Neuralink 帮助瘫痪患者重获绘画
一名因车祸瘫痪的患者术后通过脑机接口重新绘画,Neuralink 分享了这一案例。
新研究测试模型推理错误轨迹
SouradipChakr18 提出推理密集型回归任务:判定长推理轨迹首次出错的位置。
On-policy RL 依赖有监督终局信息
研究发现 on-policy 强化学习和蒸馏算法通常依赖标签化最终答案和过程奖励等特权信息。
ChatGPT 移动端 Codex 持续改进
OpenAI 团队正在预览期快速迭代 Codex 移动端,依据用户反馈提升体验。
Token 正成为解决问题的通用输入
GDB 认为 Token 正迅速成为各领域解决问题的通用输入接口。
通过 ChatGPT 使用 Codex 的解放体验
gdb 称从 ChatGPT 应用使用 Codex 的体验令人解放,意识到人们通常与电脑绑定得太紧。
Codex 自成类别
"Mac 上的 Agentic Excel" 是对 Codex 的有趣描述。
Codex 改善计算复杂度
gdb 分享使用 Codex 优化计算复杂度的实践。
用 GPT 做防御安全
gdb 提出 GPT 在防御性安全领域的新应用方向。
Chronicle 让你意识到遗忘之快
活动追踪工具 Chronicle 让人意识到一天的工作记忆消逝得多快。