Astra Solves Ten Major Open Problems in Math for Under $2,000
OpenAI's next major model family cracks breakthroughs in mathematics, quantum computation, and theoretical computer science at a fraction of frontier inference cost.

Ten significant advances in mathematics and theoretical computer science have been solved using an internal version of Astra, OpenAI's next major model family, for a total cost of about $2,000 at Sol API prices. The results, shared by OpenAI researcher Greg Brockman on the evening of August 1, signal a new era where frontier reasoning becomes accessible at consumer-grade budgets. Among the breakthroughs is the proof that nonsofic groups exist — a statement confirmed by Microsoft's Sebastien Bubeck as one of many new beautiful results proved by Astra. The milestone underscores how rapidly the cost curve for cutting-edge mathematical reasoning is collapsing.
OpenAI CEO Sam Altman retweeted the announcement with a succinct “team humanity,” while the community debated the implications. Within hours, the announcement had drawn over 620,000 views and thousands of retweets, reflecting the appetite for concrete, verifiable AI progress over hype. The ability to solve open problems in pure mathematics at this price point raises profound questions about the future of research: when a model can prove theorems that have stumped humans for decades, what does it mean to be a mathematician?
DeepSeek-V4-Flash Lands on Ollama Cloud With Agent-First Capabilities
A substantial update enhances agentic tool use, Claude Code integration, and benchmark performance — now over 2x faster day two.
DeepSeek-V4-Flash-0731 is now available on Ollama's cloud with a substantial boost to its agentic capabilities. The release brings native Claude Code integration via ollama launch claude --model deepseek-v4-flash:0731-cloud, positioning the model as a drop-in engine for autonomous coding workflows. Within 24 hours of release, Ollama reported a 2x speed improvement, and the launch post garnered over 1,700 likes and 110 retweets. The update gives developers an open-weight alternative that competes directly with proprietary agentic coding tools, targeting the growing market of AI-assisted software engineering.
MiniMax H3: An Open Video Model at the Frontier Table
For the first time, an open video model sits alongside closed frontier systems — across tasks, modalities, and production pricing.

MiniMax H3 represents a milestone for open-weight video generation, matching the quality of closed frontier models while being priced for production. The model handles video, audio, and text modalities in a unified architecture, with capabilities spanning cinematic scene generation, lip-synced dialogue, game visual production, and VFX. Robotics researchers are particularly enthusiastic — MiniMax noted that open weights allow the embodied AI community to build data engines, world models, and policies without seeking permission. A flurry of community demos flooded social media throughout August 1, showcasing everything from stop-motion claymation to AAA game trailers to music videos, all generated with simple text prompts.
Through a combination of excessive paranoia and fairly standard use of coding agents, I have found bugs in PyTorch, PyTorch/ao quantization, Tinker, vLLM, FlashQLA GDN kernels — all just in July.
— @jxmnop, on AI-assisted bug hunting in core ML infrastructure
John Schulman on Open Weights: We Love Them, But We're Not Absolutists
We love open weights and plan to keep releasing open-weight models and fine-tuning tools. But misuse risks are real. The former OpenAI co-founder laid out a vision for responsible open release, calling for more research into safety guardrails and urging the community to treat openness as a spectrum rather than a binary. The thread comes at a critical moment as governments worldwide debate export controls and licensing regimes for frontier AI models. Schulman's pragmatic stance — championing open weights while acknowledging real risks — has drawn praise from researchers who see it as a template for navigating the increasingly polarized debate over AI democratization versus control.
Why Explaining Open Release Safety Matters for Regulation
This type of work is incredibly valuable for explaining to the broader public how you can keep releasing open models despite their open-ended risks, wrote Nathan Lambert. The AI researcher argued that transparent safety frameworks will protect against a lot of potential regulatory attention. Lambert's comments came amid growing tension between open-source advocates and those pushing for stricter AI governance, with Hugging Face CEO Clement Delangue appearing on CNN to discuss potential legal action against OpenAI over training data disputes. The conversation is no longer academic — it is shaping actual legislation in the EU, UK, and US.
Grok Build: Now Powered by Grok 4.5 With Native Subagent View
Elon Musk's CLI coding agent adds Plan Mode, mouse support, and a full-screen terminal UI.
Grok Build is now powered by Grok 4.5, adding a native subagent view, Plan Mode integration, mouse support, and a full-screen terminal UI. The tool, installable via a single curl command, promises to handle almost any task a developer can think of. Musk also announced that Grok 4.5 is Pareto #1 when considering speed and cost, while teasing that Grok Imagine Video 1.5 improvements are rolling out, now available on Runway. The rapid cadence of releases — from the Grok model family to the Build CLI to video generation — reflects xAI's ambition to compete across the full AI stack in 2026.
eve: An Open Source Agent Framework Like Next.js for AI
Rauchg unveiled eve, an open-source agent framework that treats agents as folders. With a single instructions.md file, developers can define and run agents with skills, tools, and channels as optional add-ons. Model-agnostic and deployable via self-hosting or serverless infrastructure, eve brings production-grade features like persistent execution, isolated sandboxing, and human approval gates to the agent-building workflow.
François Fleuret: AI Excels at Using Tools, Not Inventing Them
AI is able to use existing tools and methods very efficiently, but it is not yet able to invent new tools and methods, the Idiap Research Institute professor wrote. He acknowledged there may be sparks of this capability emerging, but current models definitely cannot match humans on genuine methodological innovation. The observation resonated amid the Astra milestone, suggesting that even the most advanced reasoning models still operate within human-defined frameworks.
GPT-5.6-Sol vs Terra: Persistence Is the Differentiator
Both GPT-5.6-Sol and GPT-5.6-Terra are good models, but Sol's thoroughness and persistence set it apart. Graham Neubig noted that Terra does a lot of partial work while Sol consistently gets the job done, suggesting that the frontier is now about follow-through rather than raw capability. This aligns with the broader industry shift toward agentic workflows where task completion matters more than single-pass generation quality.
SGLang Adds Inkling-Small Support on Dual DGX Spark Systems
SGLang now officially supports Thinkymachines' Inkling-Small running on 2× NVIDIA DGX Spark systems connected via ConnectX-7, enabling high-throughput inference for smaller models on workstation-class hardware.
Grok Imagine Video 1.5 Lands on Runway

xAI's video generation upgrade is now available on Runway, promising improved visual fidelity and faster generation. The release brings Grok Imagine's capabilities to Runway's creative toolset.
MiniMax H3 Opens Doors for Embodied AI Research
Robotics is one of the use cases we're most excited about for MiniMax H3. Open weights mean the embodied AI community can build data engines, world models, and policies on top of it without asking permission, MiniMax stated, inviting researchers to reach out directly.
PixVerse Turns Real Motion Into Infinite Visual Possibilities

PixVerse demonstrated a new capability that preserves real performance motion while rebuilding the entire visual world around it, turning every camera shot into a foundation for endless creative variations.
Seedance 2.5 Brings Motion Control to Higgsfield

Seedance 2.5 introduces motion control capabilities to the Higgsfield platform, enabling creators to direct complex VFX sequences with precision.
Gaussian Processes: Not Ancient Magic, Just Old Code

François Fleuret reminded the community that Gaussian processes aren't arcane ML magic — he published a 2009 tutorial on them 17 years ago, as a new generation of researchers rediscovers classical Bayesian methods.
8B Chess Model Hits 1500 Elo, Beats Frontier Models
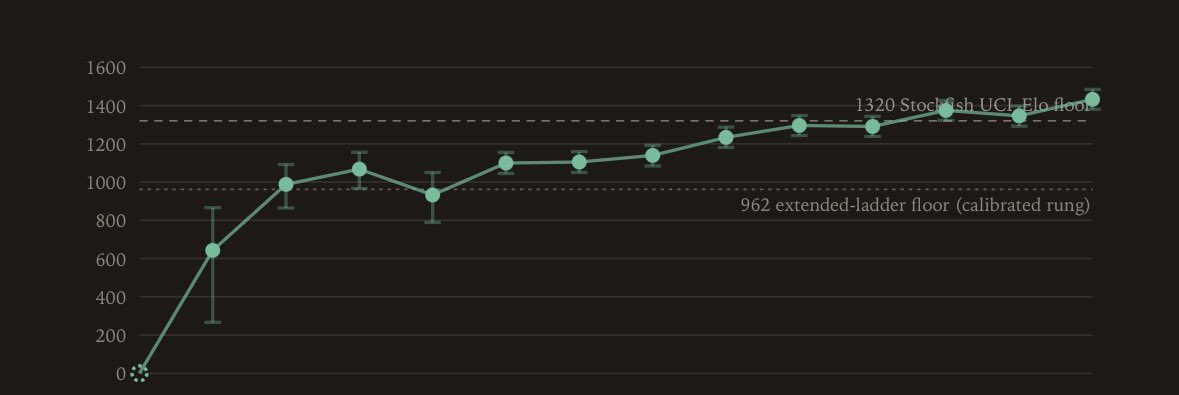
Amjad Masad showcased an 8B-parameter Qwen chess model reaching ~1500 Elo, consistently beating frontier models and Stockfish level 0 while spending only 1-2 seconds per move versus GPT-5.6's 30 seconds.
Why Evaluating AI Agents Is Much Harder Than Evaluating LLMs
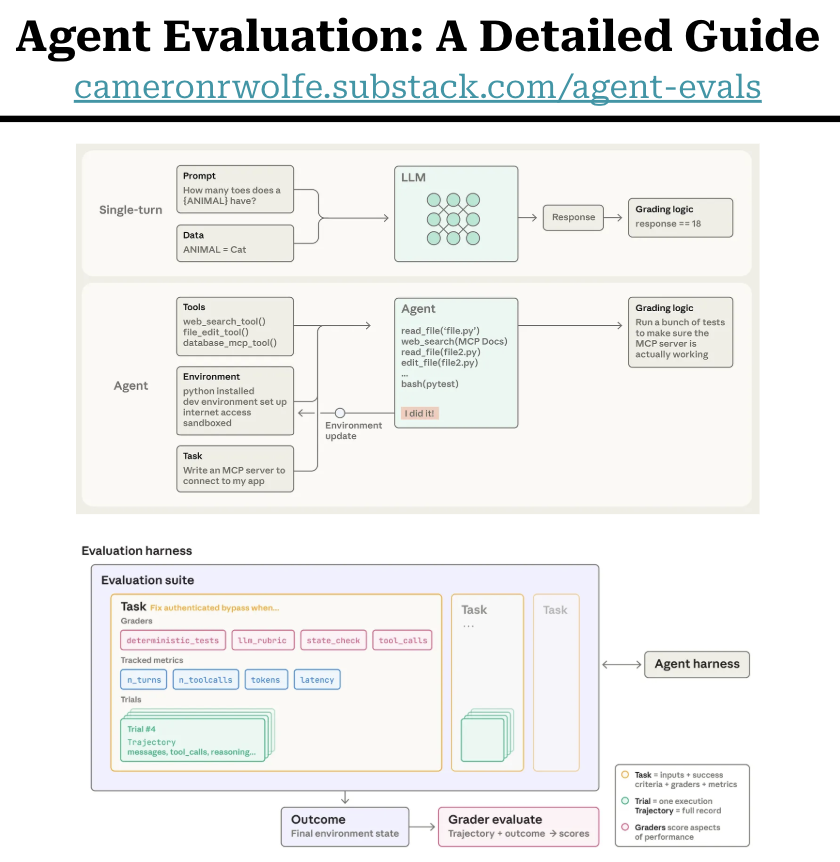
An agent interacts with an environment by reasoning, calling tools, observing results, and repeating — making single-output LLM benchmarks inadequate for evaluating real-world agent performance.
Cohere Labs ML Summer School Tops Twitch Tech Category
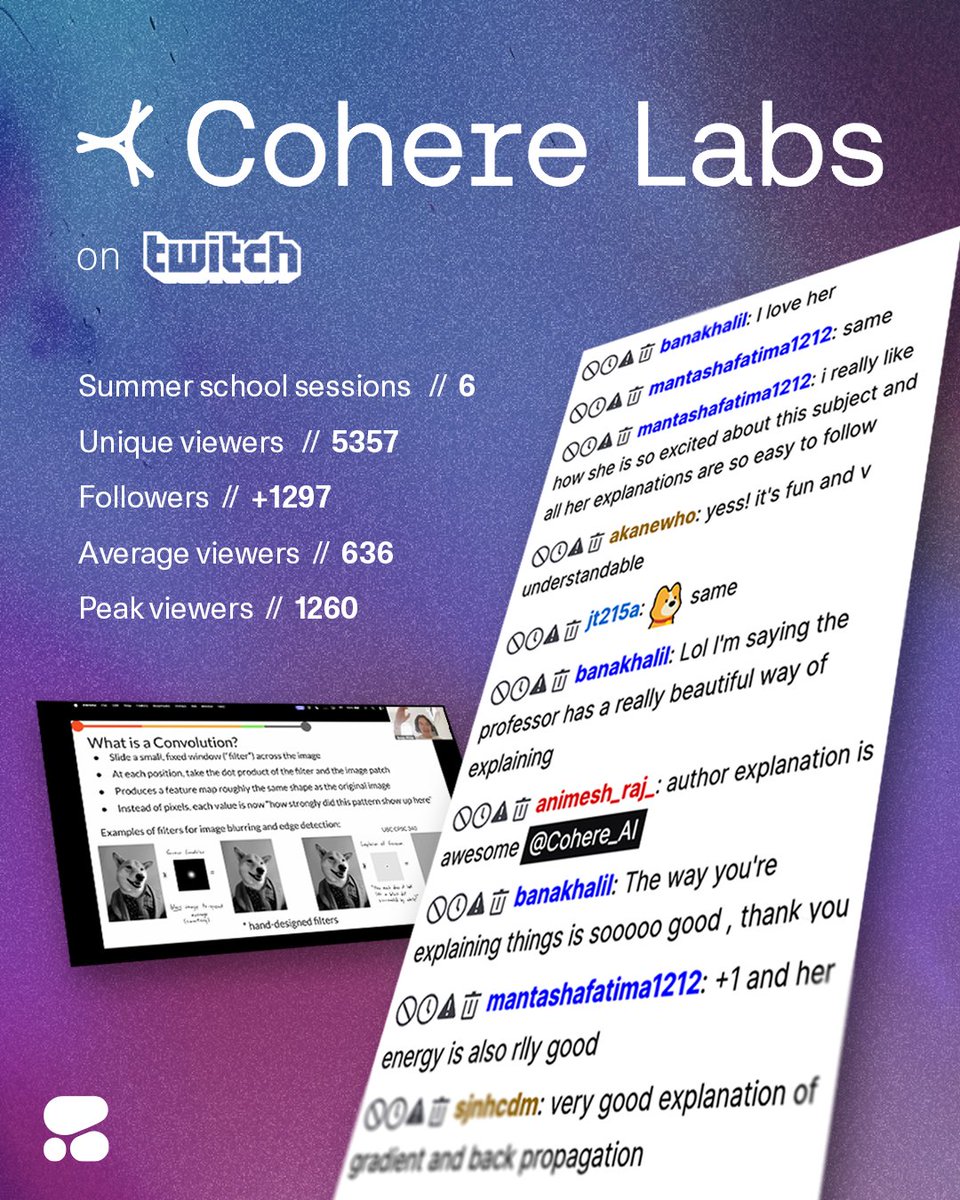
Cohere's free ML Summer School series drew viewers from 20+ countries, covering NLP in LLMs to building a tech career. The streams are now #1 in Twitch's tech category.
LlamaIndex Heads to AI4 Las Vegas With Three Events
LlamaIndex is coming to Las Vegas for Ai4Conferences next week (Aug 4–6), featuring a booth on the expo floor, a talk on unlocking document context for AI agents by Jerry Liu, and an exec dinner at Tao Bistro.
DeepSeek-V4-Flash Now 2x Faster on Ollama Cloud
Just one day after launch, Ollama reported that DeepSeek-V4-Flash-0731 is now over twice as fast on their cloud infrastructure.
Greg Brockman: Put ChatGPT to Work Every Day
The OpenAI president's concise endorsement of AI-assisted daily workflows drew over 90,000 views, reflecting the normalization of AI copilots in knowledge work.
Replit Design Lets You Choose From Claude, GPT-5, Gemini, Kimi, GLM
Replit's design tool now supports multiple frontier models side-by-side. Users can compare outputs across model families and keep whichever result nails the design brief.
The Number of Ideas I Can Test Daily With Coding Agents Is Astounding
François Fleuret marveled at the research throughput enabled by combining coding agents with sufficient GPU compute, calling the daily idea-testing capacity unprecedented.
ChatGPT Work Excels at Thorough Research and Fact-Checking
Brockman praised ChatGPT Work's cloud browser for easily monitoring what AI is up to and intervening in live applications, calling the experience excellent for research workflows.
FactoryAI Hosts Open Source Evening With MiniMax, Kimi, Baseten, Modal
A gathering of open-source AI builders on August 6th brings together MiniMax AI, Kimi Moonshot, Baseten, Modal, and other builders for an evening of collaboration.
Hugging Face CEO on CNN: Will They Sue OpenAI Over Training Data?
Clement Delangue appeared on national television to discuss potential legal action against OpenAI, bringing the training data dispute to a mainstream audience.
Grok 4.5 Is Pareto #1 for Speed and Cost
Elon Musk claimed Grok 4.5 leads the Pareto frontier when considering both inference speed and cost, drawing over 2 million views on the announcement.
OpenHands Offers Free DeepSeek-V4-Flash to Cloud Users
OpenHands is providing free access to DeepSeek-V4-Flash for its Cloud users for a limited time, riding the wave of excitement around the new model release.
TruffleSec Partnering for Largest Secret Scan of AI Training Data Ever
Julien Chaumond announced a partnership with TruffleSec to perform the largest secret scan of AI training data, addressing growing concerns about credentials leaked into training corpora.
AI Will Do Harder Tasks We Will Struggle to Comprehend
Yunta Tsai, retweeted by Elon Musk, argued that AI will increasingly tackle more difficult tasks that take longer and longer for humans to comprehend, challenging our ability to evaluate its outputs.
Levelsio: The AGI Era Makes Me Want to Ship More Complex Things
Pieter Levels reflected that if AI lets you ship faster and better, you should build things you could not imagine making before — turning the moat-destroying anxiety of AGI into a call to raise creative ambition.
Nathan Lambert: LLMs Are a Wonderful Driver for Humanity
We just need to proactively manage the transition to powerful AI and the benefits will be immense, the researcher wrote, striking an optimistic note amid growing regulatory anxiety.
Google Was Too Nervous to Ship What DeepMind Built
Shawn Wang bookmarked the observation that Google's internal caution blocked DeepMind from shipping disruptive products, suggesting it as a rebuttal to investors who ask what happens when incumbents enter the market.
LlamaIndex Builds OCR Router That Estimates Per-Page Complexity
The new document OCR router can estimate the complexity of every single page and parse it with the relevant mode, optimizing document processing pipelines.
Kimi K3 Now in NVFP4 for Blackwell Acceleration
MoE layers quantized to 4-bit for accelerated inference on NVIDIA Blackwell hardware, building on the earlier FP8-Block checkpoint released by Red Hat AI.
Perplexity Remote MCP Server Now Live Across IDEs
The Perplexity remote MCP server can now connect to Claude Code, Cursor, or VS Code with minimal setup, expanding the search engine's reach into developer workflows.
Banning Open Source Models Removes Capabilities From Defenders
A Chinese lab using open source models caught OpenAI's models breaching Hugging Face, underscoring the defensive value of open-weight AI across geopolitical lines.
Synthesia Founders Navigate the First Year of AI Video at Scale
An in-depth profile reveals how Synthesia's leadership steered through the challenges of launching and scaling enterprise AI video generation.
Next Steps for AI: Better Than Human in All Math Within One Year
Christian Szegedy predicted that within one year AI will be strictly better than humans in all problem-solving aspects of mathematics, and within two years in all of computer science.
MiniMax H3 Breaking Boundaries Between Tasks and Modalities
MiniMax emphasized that H3 was designed as one model across tasks and modalities, priced for production, and in a few days will be open for anyone to build on.
We Need 10 Unrelated Lean Kernel Implementations From Specs
Fleuret called for diversity in formal verification, arguing that multiple independent Lean kernel implementations are needed to establish trust in automated theorem proving.
ChatGPT Work's Cloud Browser: Monitor and Intervene Live
Greg Brockman described the cloud browser as really cool, letting users easily monitor what their AI is up to and intervene with the live application if needed.
OpenAI Team Making Git Better for Everyone
Brockman teased improvements to Git workflows from the OpenAI team, hinting at AI-enhanced version control tooling in development.
Two Orders of Magnitude Improvements Are Quite Rare
Perplexity CEO Aravind Srinivas called a recent model performance leap a big deal, noting that hundredfold improvements are rare in any field of engineering.
MiniMax H3 Handles Interface Animation With Remarkable Fidelity
Community testers praised MiniMax H3's ability to render transitions, micro-interactions, camera movement, and text integration in a single pass, calling it a breakthrough for UI prototyping.