Issue 012 -- Era of Intelligent Transformation

A photo that is out of focus.
>> Topics to Discuss
I recently read a short book titled “智变时代:AI驱动的新工业革命与人类未来” It mentions/quotes two concepts that left a deep impression on me, which I will briefly list here.
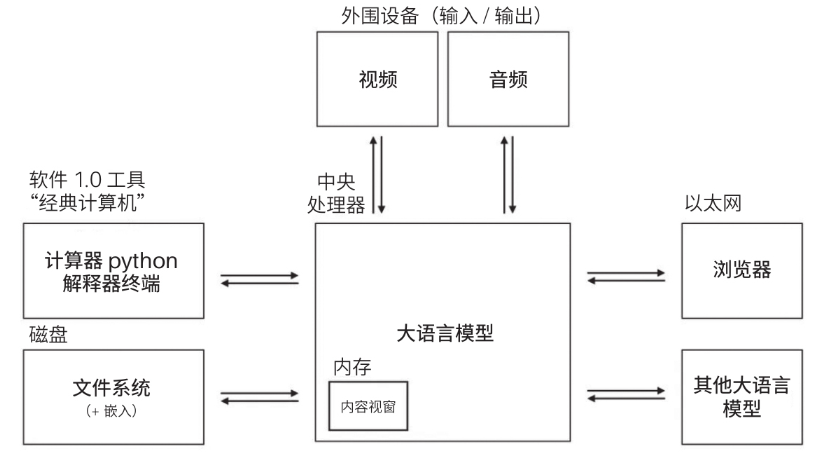
Large Models as Operating Systems
We can use large language models (now more appropriately referred to as large multimodal models) in the same way we use operating systems. The core of this system is the LMM, which processes incoming data like a CPU and provides results after computation. The difference is that while a computer's CPU accepts hexadecimal assembly instructions, the LMM accepts natural language.
The system's memory is represented by the LMM's context window, which indicates the maximum number of tokens that can be processed in a single inference operation.
Outside of the model, there are other system components typical of an operating system, such as I/O for perception through modalities like voice and vision; and a file system that grants the model the ability for infinite memory. After all, the model is not a database; its memory is an aid to computation.
Cheap Induced Demand
This paradox states that when something becomes more efficient, people tend to consume more of it. Jevons observed that as the efficiency of the steam engine improved, it required less coal to accomplish more tasks, yet coal consumption increased.
By increasing the supply of potential demand, such as intelligent services, people will use these services more frequently.
>> Must Read
Node v22.7.0 Released, Supports Directly Running TS
NodeJS 22.7.0 has been released, introducing the previously mentioned --experimental-transform-types to support TypeScript syntax.
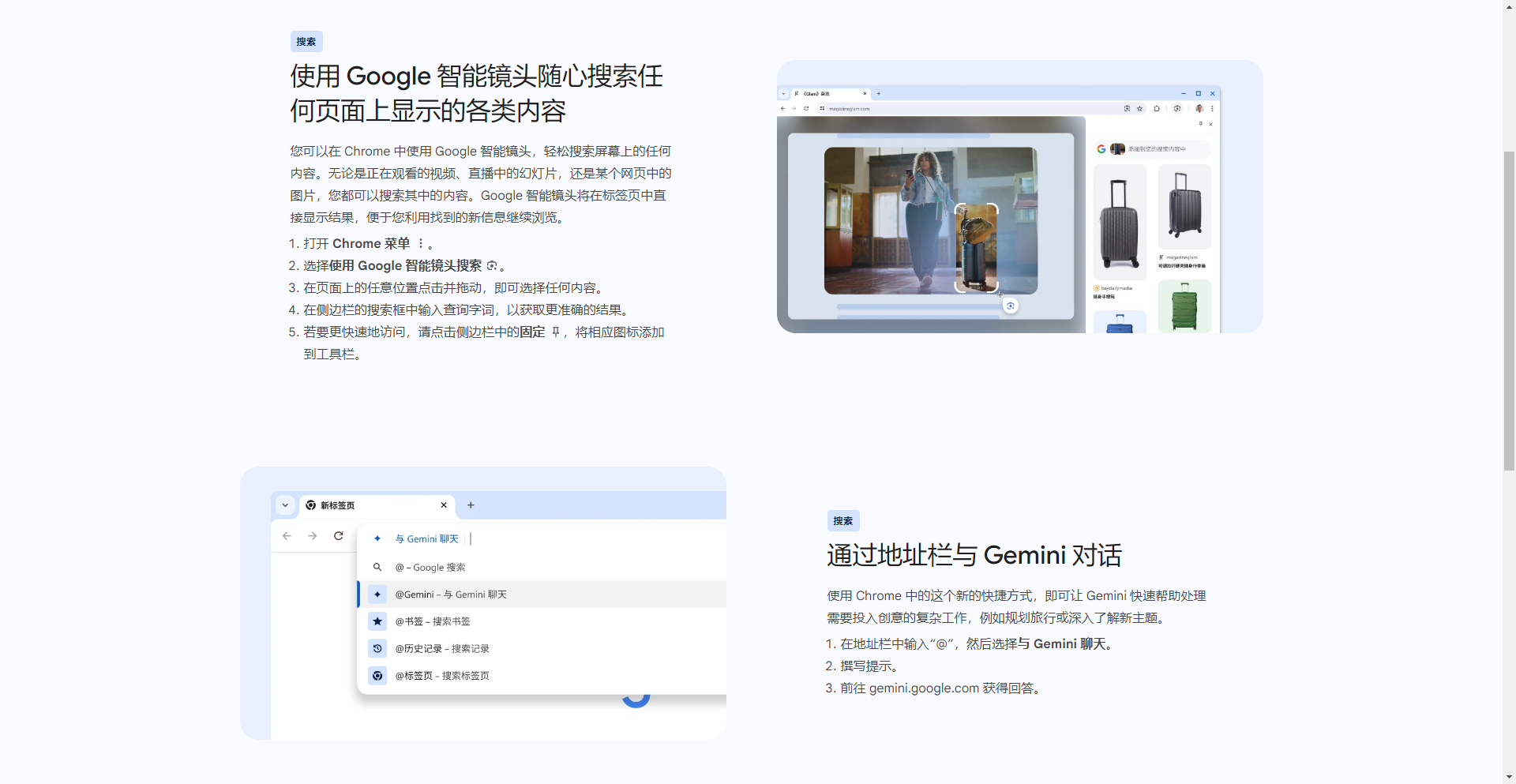
New Features in Chrome 128
- Use Google Lens to search for various content displayed on any page.
- Chat with Gemini through the address bar.
>> Useful Tools
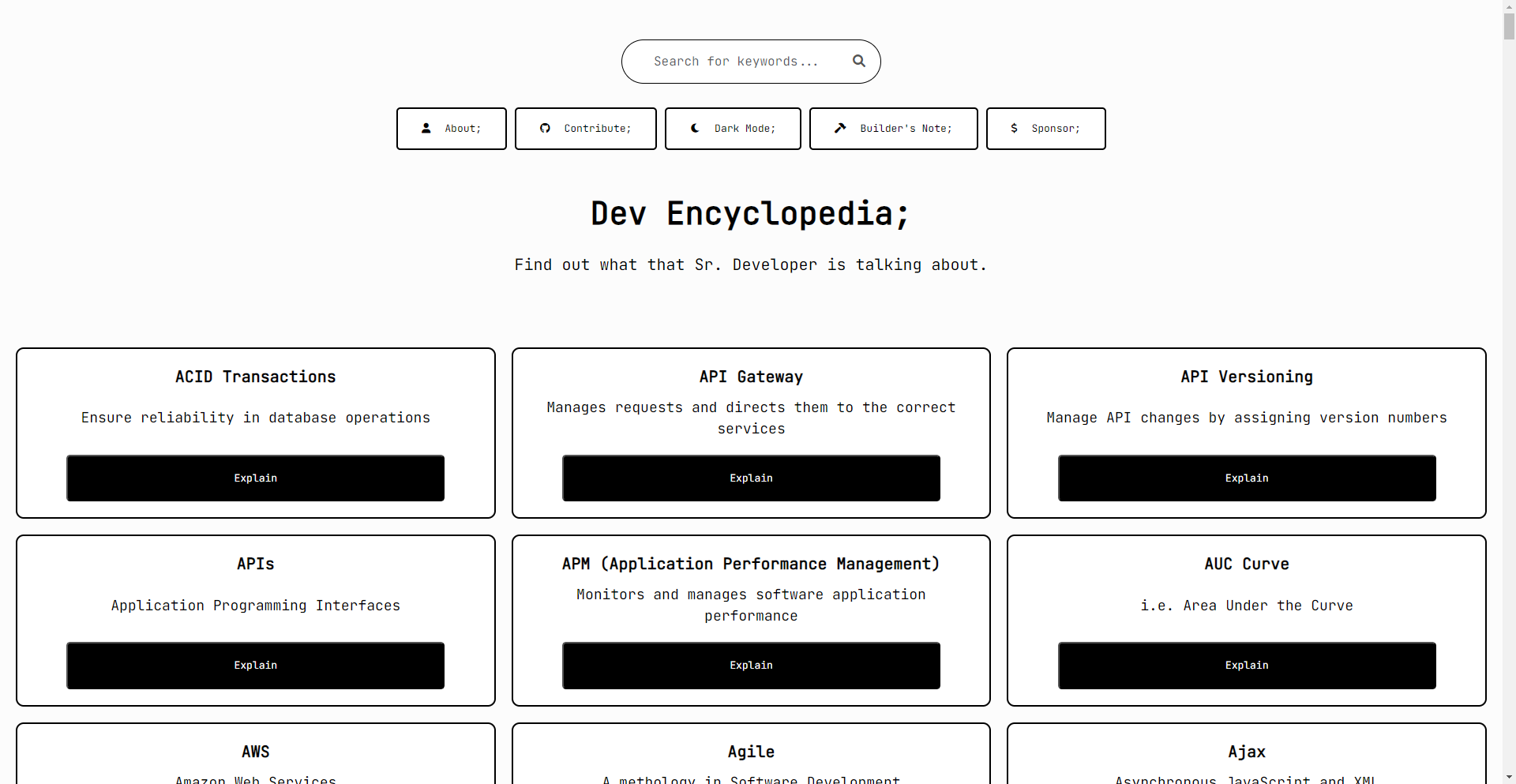
Developer's Encyclopedia
A Wikipedia for developers!
- Clear Definitions: Breaks down complex terms into simple explanations.
- Practical Examples: Provides examples to clarify concepts.
- Open Source: Ad-free and designed with the developer community in mind.
Comprehensive and Aesthetic 3D Icon Library
- 100% free for commercial and personal use, following CC0.
- Over 1440 rendered images.
- Supports multiple download formats (PNG, Figma, Blender, etc.).
- Each icon includes four predefined color styles, three camera angles, and high-quality renders.
Markdown-Based TODO Software
A self-deployable TODO management software that uses Markdown for storage.
After a quick look post-deployment, it retrieves all lanes (TODO group areas) via a lanes.json file. Each lane is a folder containing Markdown files for each TODO item.
lanes.json -> Assume it as ['Today', 'Week', 'Month']
tasks directory
├─Today
│ ├─http://XXX1.md
│ └─http://XXX2.md
├─Week
└─MonthThe directory structure is quite clear, and the interface is generally standard. Each TODO item supports Markdown editing and tag categorization.
Bio Homepage Template
A minimalist and aesthetically pleasing self-deployable bio homepage template.
Great for showcasing personal profiles and short links.
Real-Time Rendering Markdown Editor Library
Open Source Community Forum
An open-source community forum repository used by OpenAI, currently with over 40K stars.
I just discovered that the OpenAI Community is built using this open-source repository 🫡
Upon closer inspection, I found that many well-known websites use it, which explains the familiarity~

More
- Dasel: Select, Place, and Delete Data from JSON, TOML, YAML, XML, and CSV
- All-in-One Open Source High-Quality Data Extraction Tool
- Memorize 7000 IELTS Words with 100 Sentences
- Code Highlighting in Font Files
- Logging Library
- Badminton Sports Analysis Assistant
- GitHub Bot for Automatic Issue Fixing
- Social Media Video Downloader
- Developing VSCode Extensions with Vue's Reactive API
- JS Version of Jupyter Notebook
>> Interesting Finds
"Bottom Fishing"
>> Worth Reading
Codebases Uniquely Challenging for Semantic Search
Semantic search works better on codebases if you first translate the code into natural language, then generate embedding vectors. It is more effective to chunk in a "tighter" way—by functionality rather than by file level—because noise significantly impacts retrieval quality.
I Built My First Side Project, But I Hate It
The author shares their experience of creating their first successful side project, which brought in over $15,000 in revenue, yet they feel exhausted maintaining it. Initially, they experienced the thrill of sales, but as the number of customers increased, so did the issues: endless customer requests, refunds, disputes, and scams left them drained.
To alleviate the burden, the author ultimately chose to automate most workflows, including automated payment processing and access management. They realized that the stress of maintaining the side project conflicted with their enthusiasm for it, leading them to somewhat detach from the project. Despite a gradual decline in revenue, they regained enjoyment through setting boundaries and automating tasks.
In conclusion, the author summarizes the lessons learned from this experience, including the importance of setting boundaries to prevent burnout, using "sales agents" to streamline the transaction process, and maintaining friendliness in customer service. Although the side project did not yield the expected financial returns, it provided valuable experience for future projects.
More
- I'm Tired of My Software Career, What Should I Do Next?
- AI Companies are Pivoting from Creating Deities to Building Products, Good.
- Lessons Learned While Working for Mark Zuckerberg
- Good Refactoring vs. Bad Refactoring
- The Philosophy of Dogs: I Wag My Tail, Therefore I Am
- Finding Memory Leaks in Web Tools
- Postgres as a Search Engine
- Implementing React from Scratch