012期--智变时代

没对上焦的一张图。
>>想聊的
最近看了一本很短的书籍《智变时代:AI驱动的新工业革命与人类未来》,其中提到/引用了两个概念让我印象深刻,这里简单罗列一下。
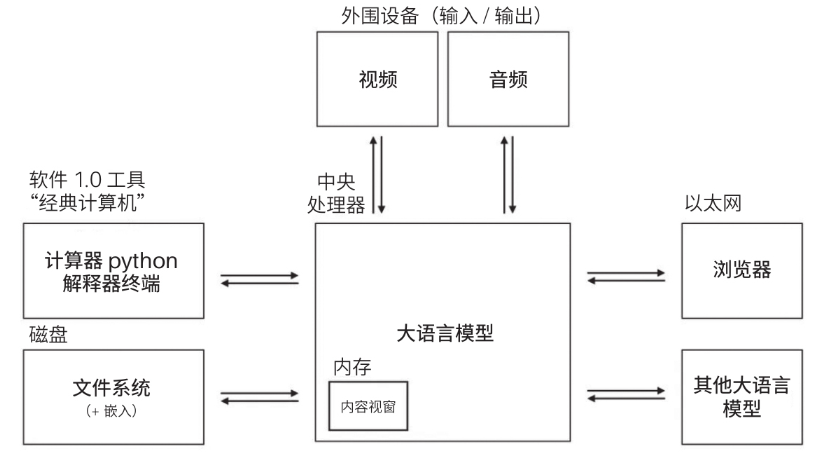
大模型看作操作系统
我们可以像使用操作系统一样来使用大语言模型,现在应该叫大型多模态模型更合适。这个系统的核心就是LMM,它就像CPU一样处理进入的数据,计算后给出结果,不同的地方电脑CPU接受十六进制汇编指令,LMM接受自然语言。
系统的内存就是LMM的上下文窗口(Context Window),一次推理运算最多能接受的Tokens数量。
在模型之外,还有操作系统的其他系统部件,例如I/O-用语音、视觉等模态感知;还有文件系统,让模型具备无限记忆的能力,毕竟模型不是数据库,它的内存是辅助计算的。
廉价诱导需求
该悖论陈述了当某样东西变得更高效时,人们会消费更多的这种东西。杰文斯观察到,当蒸汽机的效率提高时,使用更少的煤炭就可以做更多的事情,但实际上煤炭的消费量增加了。
增加对潜在需求的供应,例如智能的供应,人们就会更频繁地使用这些服务。
>>该看的
Node v22.7.0发布,支持直接运行TS
NodeJS 22.7.0发布了,增加了之前提到的 --experimental-transform-types 来支持 TypeScript 语法。
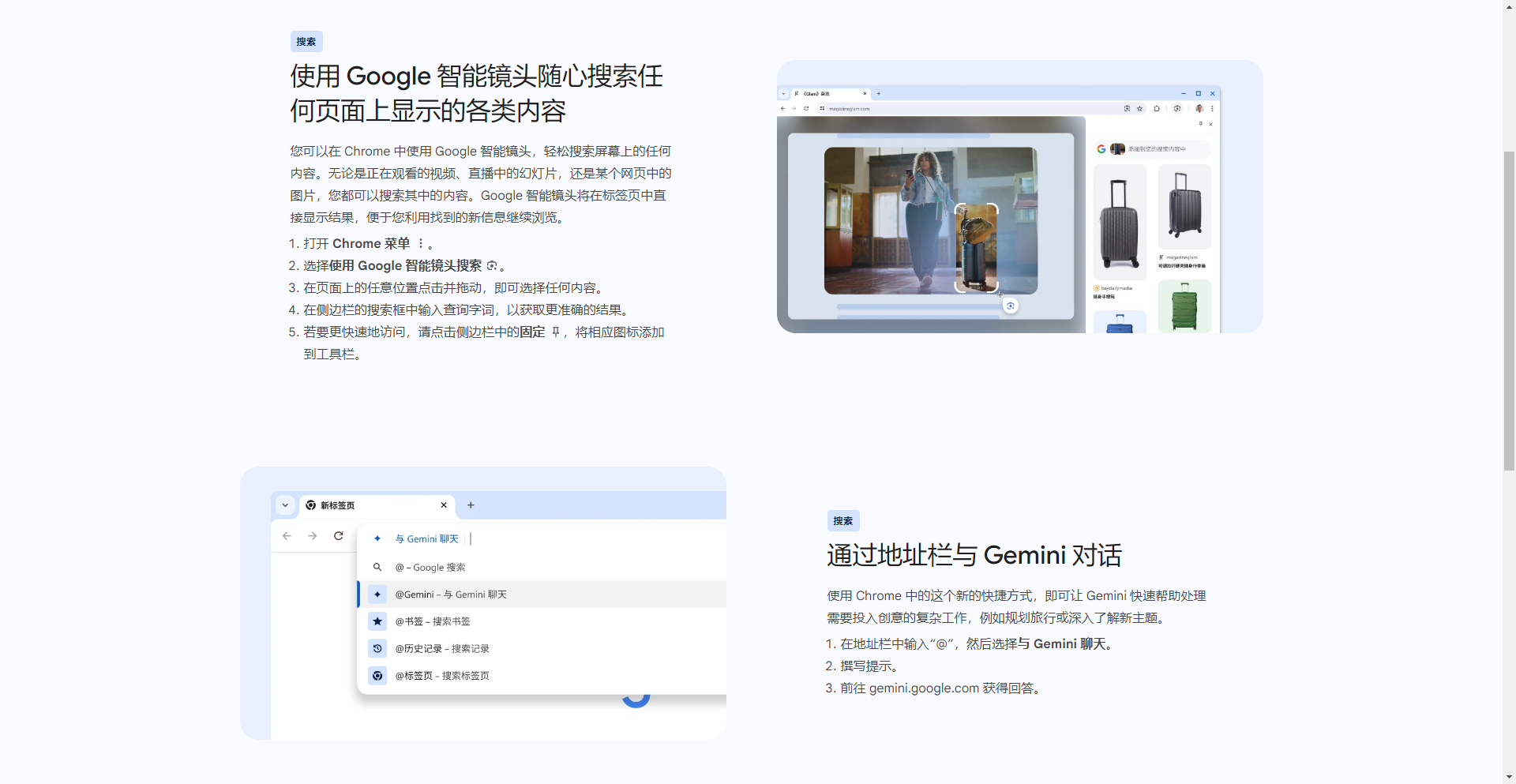
Chrome128新功能
- 使用 Google 智能镜头随心搜索任何页面上显示的各类内容
- 通过地址栏与 Gemini 对话
>>好用的
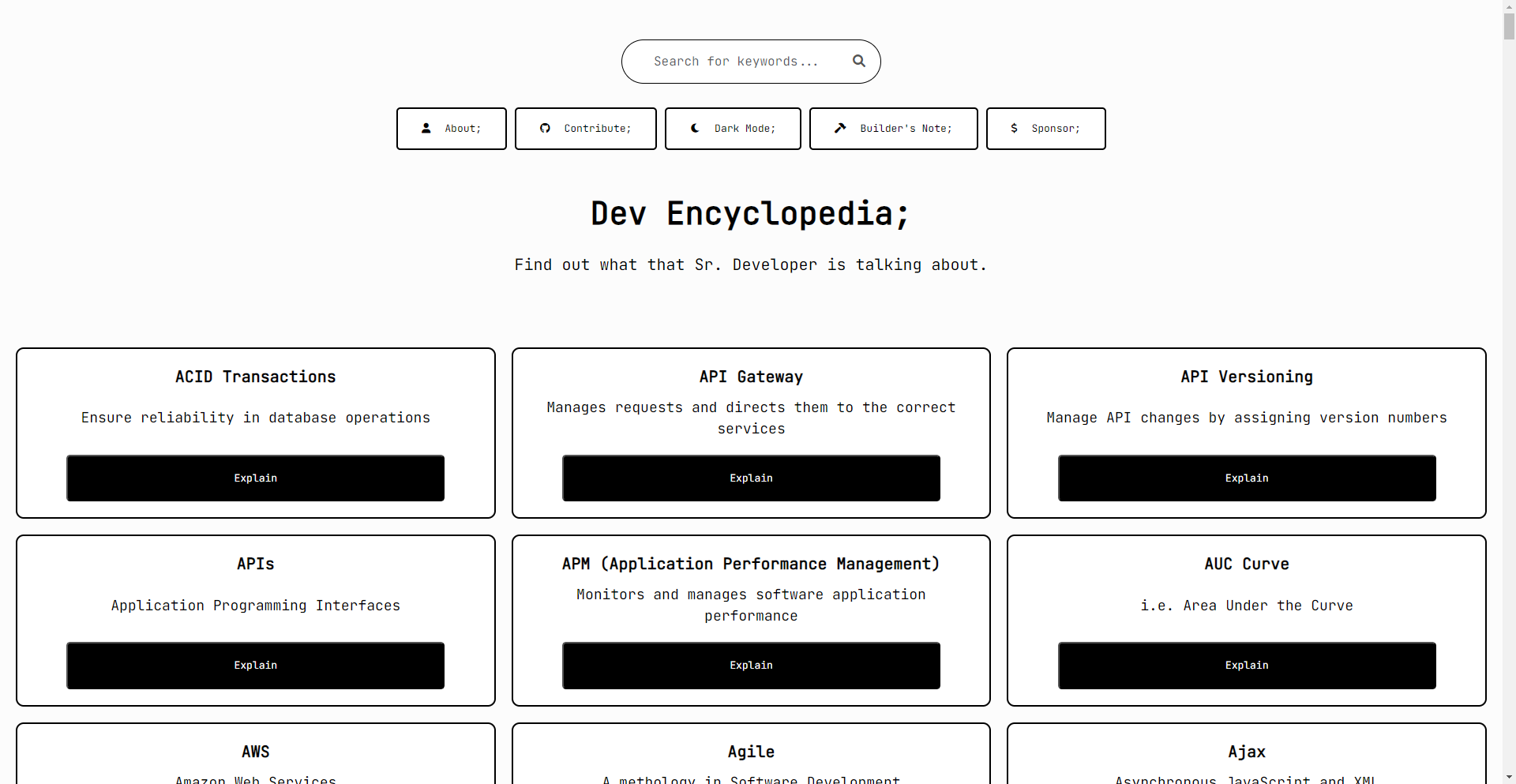
开发者的百科全书
面向开发者的维基百科!
- 清晰的定义:将复杂的术语分解为简单的解释;
- 实用示例:提供示例以帮助阐明概念;
- 开源:无广告,旨在考虑开发者社区;
全且好看的3D图标库
- 100% 免费用于商业和个人用途,遵循 CC0
- 1440+ 渲染图像
- 支持多种格式下载(如PNG、Figma、Blender等)
- 每个图标包含4种预定义颜色样式、3个摄像机角度与高质量渲染
Markdown存储的TODO软件
一款基于Markdown存储的可自部署的TODO管理软件
部署后简单看了下,它是通过一个lanes.json文件拿到所有的lanes(TODO的分组区域) 然后每个lanes是一个文件夹,里面有每个TODO项的Markdown文件
lanes.json -> 假设为['Today', 'Week', 'Month']
tasks目录
├─Today
│ ├─http://XXX1.md
│ └─http://XXX2.md
├─Week
└─Month目录结构还是比较清晰的,界面总体来说也是中规中矩,每个TODO项支持Markdown编辑,也支持tag分类。
bio主页模板
一个简约好看的可自部署的bio主页模板
放放个人简介,短链接还是很不错的。
即时渲染的Markdown编辑器库
开源的社区论坛
OpenAI都在用的开源的社区论坛仓库,目前40K+⭐️
才发现OpenAI Community是用的这个开源仓库构建的🫡
然后仔细看了看,发现很多知名的网站都是用的这个,怪不得感觉有点像~

更多
- Dasel:从 JSON、TOML、YAML、XML 和 CSV 中选择、放置和删除数据
- 一站式开源高质量数据提取工具
- 100个句子记完7000个雅思单词
- 字体文件中的代码高亮
- 日志库
- 羽毛球运动分析助手
- github bot自动修复issues
- 社交媒体视频下载
- 使用 Vue 响应式 API 开发 VSCode 扩展
- JS版本的Jupyter Notebook
>>有趣的
"抄底"
>>可读的
代码库在语义搜索方面独特地难以处理
在代码库上进行语义搜索效果更好,如果你先将代码翻译成自然语言,然后再生成嵌入向量。 如果你以更“紧凑”的方式进行分块——按功能级别而不是按文件级别,这样效果会更好。这是因为噪音会在很大程度上对检索质量产生负面影响。
我构建了我第一个副业项目,但是我讨厌它
笔者在文章中分享了自己创建的第一个成功的副项目的经历,尽管这个项目为他带来了超过15,000美元的收入,但他对其维护感到疲惫不堪。起初,他经历了销售的兴奋,但随着客户数量的增加,问题也随之而来:无尽的客户请求、退款、争议和诈骗,让他感到筋疲力尽。
为了减轻负担,笔者最终选择了自动化大部分工作流程,包括自动处理付款和访问权限。他意识到,维护副项目的压力与他对项目的热情之间的矛盾,促使他在某种程度上与项目脱离了关系。尽管项目的收入逐渐下降,但他通过设定边界和自动化工作,找回了乐趣。
文章的最后,笔者总结了从这次经历中获得的教训,包括要设定界限以防止精疲力竭、使用“销售代理”来简化交易流程、以及在客户服务中保持友善的重要性。这次副项目虽然没有带来预期的经济回报,但却为他未来的项目积累了宝贵的经验。