Issue 003 -- The Trust Crisis with GPT

This was my first time seeing the sea, and it was a work trip that allowed me to do so. I had always planned to see it, but it never materialized until now...
>>Topics to Discuss
Maintain Skepticism
This week, I came across an article titled: A Simple GPT Mistake Cost Us $10,000. The website seems to be under construction, so the article might not be available when you check, but the title gives a good idea of what happened.
From what I remember, the author used ChatGPT to translate Prisma/TS -> Python, different types but similar logical structures. An error slipped through unnoticed, resulting in a $10,000 loss.
Since its inception, we've known that ChatGPT can hallucinate. From early classic questions like "Why did Lu Xun beat Zhou Shuren?" which GPT-3.5turbo couldn't answer well, but GPT-4 managed to clarify the relationship.
As OpenAI continues to release new products and enhance model capabilities, ChatGPT helps us more and more, leading us to possibly overlook its hallucination flaw.
- Maybe earlier with GPT-3.5, you didn't trust it fully and wrote many test cases for its code.
- But now, in the GPT-4 era, it has solved countless problems for you, and you trust it so much that you skip writing test cases, leading to significant losses at some point!
Phrases like "A thief from within is hard to guard against" and "Drowning is common among good swimmers" might describe this scenario.
Moreover, no developer can guarantee their code is bug-free; they rely on processes to ensure a product's baseline. Using GPT should follow the same principle.
Ultimately, we need to maintain a skeptical attitude, even if ChatGPT's answers are convincing and increasingly "authoritative"...
Firstly, large general models perform poorly in maintaining factual accuracy. They excel at concepts and explaining concepts, but asking a general model about someone's birthday is typically a no-go. The reason is that in the dataset, even if the correct answer is most likely, there are many similar snippets that the model can choose from. A good example is when I asked a general Llama2-7B model for AMD CEO Lisa Su's birthday - it got the year right but the actual date was related to the discovery of transistors. Lisa Su's close association with chips and transistors made it a likely candidate in the embedding space. The model hallucinated.
Secondly, it's about how these general models are trained. The dataset might be public information, correct or incorrect (cough, Reddit, Wikipedia), or even contradictory, but these models are designed to give an answer, right or wrong. Unless the question hits a "do not answer" guardrail, almost all language models tend to provide an answer, whether it's correct or not. This applies not only to facts but also to concepts derived from the dataset. For instance, in a specific model, LiDAR and radar might seem similar, or 10 million might weigh the same as 3 million - a significant difference if you're using the model for employment contracts.
How can we solve this?
- Fine-tune the model for specific domains, embedding known, curated data for fine-tuning;
- Use RAG (Retrieval-Augmented Generation) to let a verified database assist in generating outputs;
In essence, embed hard facts into the model.
>>Must Read
WWDC 2024
After over a decade of development, Apple's calculator is finally here, and it looks impressive. It feels like drafting on paper, perfect for brainstorming. There’s also an open-source version similar to Apple's calculator here.
Domain Sale Turned into Gambling Site
Recently, an independent developer sold his long-standing website, **du.com, where du stood for "read" (读书).
The domain is anonymized to avoid directing traffic, which the buyer might prefer.
Initially, it seemed like another story of independent success. However, the buyer valued the domain for its name and inherent traffic, quickly transforming it into **du(赌).com, now a gambling site.
A few months ago, I read an article titled A Registered Domain Expired and Was Taken Over by a Gambling Site, highlighting the severe consequences of such actions, especially when using someone else's registration details for illegal activities...
So, handle domain transfers with caution!
DockerHub Images Harder to Install in China
Recently, many DockerHub images have been banned, making even the installation of Docker services challenging.
>>Useful Tools
Hand-drawn Style Infinite Canvas
A niche, open-source, yet excellent infinite canvas "dgmjs" (similar to Excalidraw's hand-drawn style).
Features include:
- 💡 Intelligent shapes (scripts, constraints, extended attributes)
- 🔧 Headless components (React)
- 📑 Multi-page support
- 👥 Real-time collaboration
- 🎨 Dark mode (adaptive colors)
- 📸 Export images, JSON
- 🔤 Rich text
Free Commercial Use Icons and Vectors
A cyber-benevolent site! Over 40,000 high-quality icons and 1,500 vector illustrations, available in SVG and PNG formats.
Key point: Free and commercially usable!!! Mind-blowing~
A Progress Bar with Realistic Physical Interactions
Bubbles follow the mouse as you drag the progress bar, creating a flicking effect. Quite interesting.
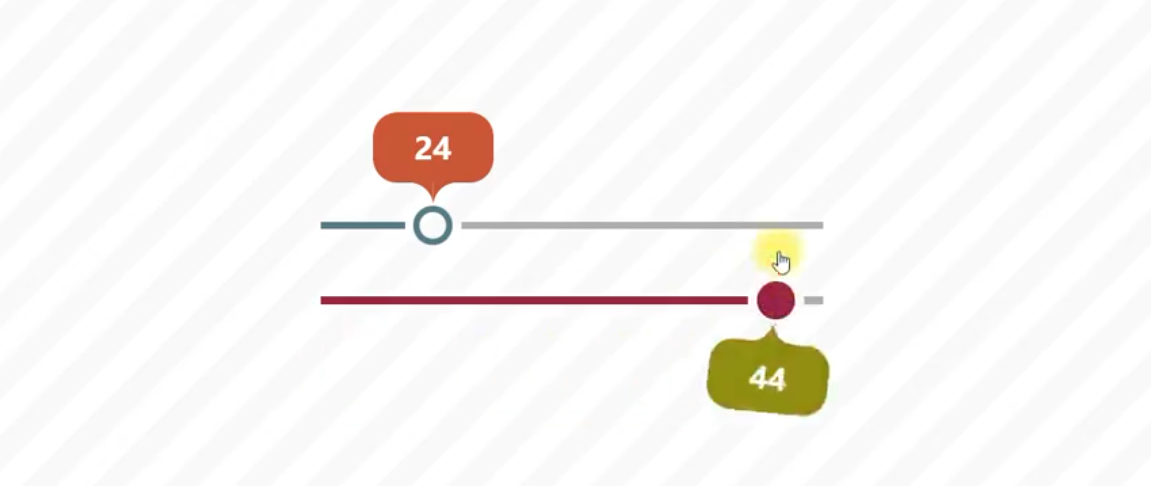
Open-source Screenshot Tool Flameshot
- Customizable appearance
- Easy to use
- In-app screenshot editing with a rich editing suite - DBus interface
- Upload to Imgur
(Compared to Pixpin, it lacks OCR recognition, but being open-source, it’s worth supporting and can be modified for fun.)
25 Free Commercial Use Calligraphy Fonts

Other previews:



Very interesting, but no simplified Chinese versions.
Navigation Sites for Independent Developers
Here are some navigation sites developed by community friends, all very good, collecting many useful tools and websites!
- Navigation for Independent Developers
- Overseas Tools Stack for Independent Developers
- Overseas Toolbox for Independent Developers
Andrew Ng's translation-agent
Translation Agent: Subjective Translation Using Reflective Workflow
This is a Python demo showcasing the workflow of a reflective agent for machine translation. Steps:
- Prompt an LLM to translate text from
source_languagetotarget_language; - Have the LLM reflect on the translation and provide constructive suggestions for improvement;
- Use the suggestions to refine the translation.
>>Interesting Finds
Explore the Sounds of Forests Around the World
There is also a more comprehensive world sounds map for those interested.
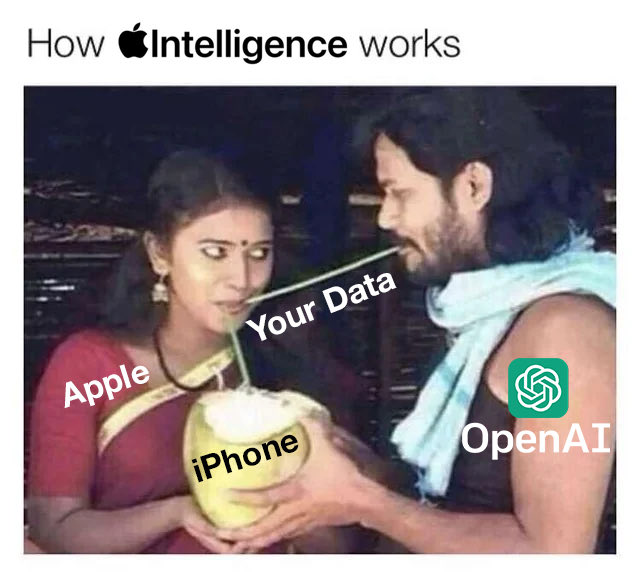
Elon Musk Mocks Apple Event
After WWDC 2024, Musk posted this image mocking Apple's use of OpenAI's services:
>>Worth Reading
Good Code Is Rarely Read
The goal when writing code is to make it as rarely read as possible. This might sound counterintuitive, but if your code is very easy to use without needing deep understanding, it’s good code. It should be well-structured and well-named so its purpose and functionality are immediately apparent. This minimizes the need for others to read and interpret the code, allowing them to use it more effectively.
Top 10 GitHub Copilot Features
Quick reference:
- Workspace agent
- Ask code questions
- Complete remaining code
- Refactor and improve code
- Fix errors and warnings
- Generate unit test cases
- Generate commit messages
- Language translation
- Rename suggestions
- VSCode agent
Check if there are any features you didn’t know about and increase your coding efficiency!
A Quick and Easy Guide to Markdown
A great tutorial for beginners to learn Markdown syntax.
Design a LEGO Orrery

How to Be a Better Software Engineering Leader
Advanced Prompt Techniques: Controlling LLM Output with Pseudocode
Prompting is essentially a control command for LLMs. We can go beyond traditional natural language descriptions and use pseudocode to precisely control LLM output and define its execution logic.