xAI предоставляет Anthropic доступ к суперкомпьютеру Colossus для Claude
xAI объявила о партнёрстве с Anthropic, предоставив доступ к Colossus 1 — одному из крупнейших и наиболее быстро развёрнутых суперкомпьютеров для ИИ в мире — для усиления обучения и работы моделей Claude.

Соглашение даст Anthropic дополнительные вычислительные мощности на базе Colossus 1, оснащённого более чем 220 000 GPU NVIDIA. Сама xAI разработала Grok — ИИ-чат-бота с функциями голосового диалога, генерации изображений и видео, поиска в реальном времени и продвинутых рассуждений. Партнёрство между двумя ведущими ИИ-лабораториями знаменует беспрецедентный уровень кооперации в индустрии и может существенно ускорить развитие моделей семейства Claude.
OpenAI, AMD и Nvidia запускают новый сетевой протокол MRC
OpenAI совместно с AMD, Broadcom, Intel, Microsoft и Nvidia выпустила открытый сетевой протокол Multipath Reliable Connection, призванный ускорить и сделать надёжнее крупные кластеры обучения ИИ.
MRC — это протокол многопутевых надёжных соединений, разработанный для снижения времени простоя GPU в масштабных тренировочных кластерах. Он уже использовался при обучении ChatGPT и теперь опубликован как open-source проект. Инициатива объединила ключевых производителей чипов и облачных провайдеров, что делает MRC претендентом на отраслевой стандарт сетевого взаимодействия для ИИ-суперкомпьютеров следующего поколения.
Anthropic значительно увеличивает лимиты Claude Code и API
Anthropic удвоил 5-часовой лимит использования Claude Code для тарифов Pro, Max, Team и корпоративных пользователей. Кроме того, отменено ограничение скорости в часы пиковой нагрузки для планов Pro и Max, а также значительно увеличены лимиты скорости API для моделей Opus. Эти изменения вступают в силу немедленно и отражают растущие вычислительные возможности компании после объявленного партнёрства с xAI.
Claude Managed Agents добавляет мультиагентную оркестрацию и самообучение
Anthropic представила новые функции в Claude Managed Agents: мультиагентную оркестрацию, циклы самосовершенствования на основе правил (Outcomes), самообучение (Dreaming) и поддержку вебхуков. Мультиагентная оркестрация позволяет координировать работу нескольких ИИ-агентов для решения сложных задач, Outcomes обеспечивает автоматическую самооценку и итеративное улучшение результатов, а Dreaming даёт агентам возможность автономного обучения в фоновом режиме.
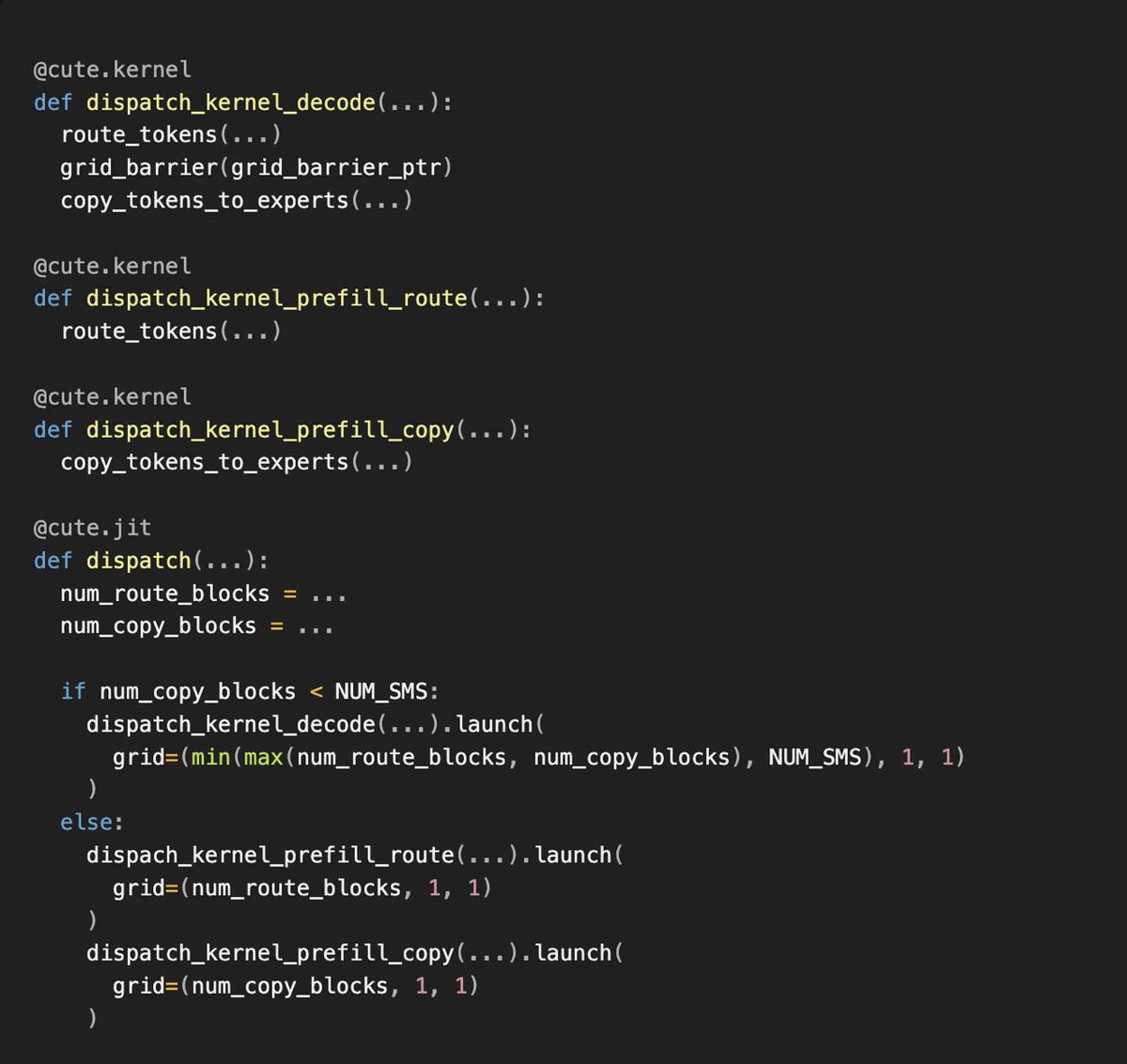
Perplexity создаёт собственный движок вывода ROSE
Perplexity разработала собственный движок вывода ROSE (Runtime-Optimized Serving Engine), способный обслуживать модели от эмбеддингов до LLM с триллионами параметров. В движок интегрирована CuTeDSL для ускоренного создания специализированных ядер GPU, что позволяет быстрее выводить новые модели в продакшен. Собственный инференс-стек снижает зависимость от сторонних решений и даёт Perplexity полный контроль над производительностью и стоимостью обслуживания моделей.
MRC — протокол, на котором тренировали ChatGPT, — теперь открыт для всего сообщества. OpenAI, AMD, Broadcom, Intel, Microsoft и Nvidia совместно опубликовали его исходный код.
— @dotey

Google DeepMind сотрудничает с EVE Online для исследований ИИ
Google DeepMind объявила о партнёрстве с разработчиком EVE Online, намереваясь использовать сложную, управляемую игроками вселенную игры в качестве безопасной среды для тестирования памяти, непрерывного обучения и долгосрочного планирования ИИ-агентов. EVE Online с её двадцатилетней экономической и политической историей представляет собой идеальный полигон для проверки способности агентов адаптироваться к динамическим изменениям.

Nvidia и ServiceNow предоставляют корпоративных автономных ИИ-агентов
Nvidia в партнёрстве с ServiceNow представила Project Arc — долго работающего десктопного агента на базе открытых технологий. Агенты способны автономно действовать в корпоративных рабочих процессах с встроенными механизмами управления, аудита и обеспечения безопасности. Решение нацелено на автоматизацию сложных enterprise-сценариев, требующих как надёжности, так и прозрачности каждого действия.
Tencent Hunyuan Hy3 Preview возглавляет рейтинг OpenRouter
Через две недели после выпуска Hy3 Preview обработал 3,66 триллиона токенов с недельным ростом 298%, заняв первое место по общему использованию, вызовам инструментов и кодированию.
Hugging Face запускает магазин приложений для роботов
Открытый магазин приложений для робота Reachy Mini содержит более 200 приложений и призван снизить порог входа в разработку робототехники по модели мобильных экосистем.
Colossus 1 насчитывает свыше 220 000 GPU Nvidia
Nvidia подтвердила, что суперкомпьютер Colossus 1, на котором будут работать модели Claude, оснащён более чем 220 000 ускорителей NVIDIA. Компания назвала партнёрство «будущим ИИ».
GPT-5.5 Instant стал моделью по умолчанию в ChatGPT
OpenAI обновила GPT-5.5 Instant: снижен уровень галлюцинаций в праве, финансах и медицине, улучшено понимание изображений и разбор документов. Модель теперь используется по умолчанию.
Perplexity Agent API добавляет финансовый поиск
Разработчики могут одним вызовом инструмента получать лицензированные финансовые данные, котировки в реальном времени и цитируемые веб-источники для агентов, которым нужны проверяемые ответы.
Zyphra выпускает ZAYA1-8B с архитектурой DSMoE-MLA++
Новая 8B-модель Zyphra сочетает передовую MoE-архитектуру с глубоким RL и масштабированием на этапе вывода. Сообщество называет Zyphra одной из сильнейших открытых лабораторий.
Cursor использует ранние Composer-модели для автонастройки RL-среды
Система autoinstall в Cursor задействует предыдущие поколения Composer для автоматического развёртывания сред обучения с подкреплением, позволяя новым моделям фокусироваться на более сложных задачах.
Gaia2 от Microsoft: бенчмарк для ИИ-агентов в динамических средах
Microsoft Research представила Gaia2 — среду тестирования LLM-агентов с шумом, динамическими ограничениями и асинхронными событиями. GPT-5 показал лучший результат (42% pass@1), но провалился на задачах с жёсткими временными рамками.
SVGS: пространственно-вариативные цвета улучшают Gaussian Splatting
Метод SVGS заменяет единый цвет и непрозрачность каждого гауссиана на пространственно-вариативные функции, значительно повышая качество синтеза новых ракурсов и геометрической реконструкции.
OBLIQ-Bench: самый амбициозный бенчмарк информационного поиска
Представлен OBLIQ-Bench — новый эталон для оценки систем информационного поиска. Длинноконтекстные LLM не работают после 200 тысяч токенов, что делает бенчмарк критически важным для развития retrieval-технологий.
Мнение: партнёрство xAI с Anthropic — сигнал для Grok?
Итан Моллик отмечает, что решение xAI предоставить Colossus конкуренту может означать, что Grok не сохранит статус передовой модели. Сделка вызывает вопросы о стратегии xAI на рынке foundation-моделей.
0.1B-модель LightOn обходит крупные dense-модели на OBLIQ-Bench
Крошечная 100M-модель LightOn с late interaction превзошла на порядки более крупные dense-модели, но набрала лишь 8% nDCG@10 — оставляя огромный запас до 91% у сильнейших моделей.
Cursor 3.3: визуализация использования контекста агентами
В Cursor 3.3 появилась детальная разбивка контекстного окна агента, помогающая диагностировать проблемы и оптимизировать настройки правил, навыков, MCP и подагентов.
MiMo 2.5 Pro и GLM 5.1 лидируют в свежих бенчмарках
В последних тестах MiMo 2.5 Pro и GLM 5.1 обошли DeepSeek и Kimi, демонстрируя растущую конкуренцию среди китайских лабораторий в гонке больших языковых моделей.
GitHub-бот robobun внёс больше кода в Bun, чем его создатель
На Code w/ Code разработчики Bun раскрыли, что их GitHub-бот robobun теперь делает больше коммитов в проект, чем сам Джарред Самнер. Бот управляет задачами, issue и генерацией кода.
Глава инженерии Anthropic управляет сотнями агентов с телефона
Борис Черный рассказал, что ведёт большую часть работы через Claude App: 5–10 постоянных сессий, сотни агентов днём и тысячи сложных задач ночью, запускаемых по cron через механизм Loop.
Code w/ Claude 2026: API-трафик Anthropic вырос в 17 раз за год
На мероприятии Code w/ Claude Саймон Виллисон вёл прямой блог: годовой рост API в 17 раз, анонс партнёрства с xAI, запуск мультиагентной оркестрации и Dreaming. Новых моделей не представили.
DeepSeek V4-Pro и V4-Flash показывают почти идентичные результаты
В нескольких независимых бенчмарках V4-Pro и V4-Flash демонстрируют паритет (при этом GLM 5.1=58.1, MiMo 2.5 Pro=66.4, GPT 5.5=77.8). В статье DeepSeek подтверждается, что базовая производительность моделей почти совпадает.