إصدار MiniCPM-o 4.5: تفاعل متعدد الوسائط ثنائي الاتجاه في الوقت الفعلي
يقدم إطار Omni-Flow الجديد محاذاة موحدة للمدخلات والمخرجات متعددة الوسائط على محور زمني واحد، مما يتيح لنموذج واحد بـ 9 مليار معلمة أن يرى ويسمع ويتحدث في آنٍ واحد، مع إصدار تنبيهات استباقية بناءً على فهمه المستمر للمشهد.

يقدم مختبر MiniCPM الإصدار 4.5 من نموذجه الشامل متعدد الوسائط بابتكار معماري حاسم: Omni-Flow، إطار موحد للبث المباشر يزامن جميع الوسائط — الصوت والرؤية والنص — على نفس الخط الزمني. على عكس البنى السابقة التي تسلسل وحدات منفصلة، يتيح Omni-Flow تفاعلاً ثنائي الاتجاه حقيقيًا: يمكن للنموذج المقاطعة أو التعليق أو التنبيه أثناء معالجته في الوقت الفعلي لما يراه ويسمعه. بإجمالي 9 مليار معلمة فقط، يحقق أداءً بصريًا لغويًا يقترب من Gemini 2.5 Flash، وفي الفهم متعدد الوسائط الكامل يتفوق على Qwen3-Omni-30B-A3B، وهو نموذج أكبر بثلاث مرات. الكفاءة لا تقتصر على الاختبارات المعيارية: بفضل تحسينات الاستدلال والمعمارية، يمكن تشغيل MiniCPM-o 4.5 بأقل من 1 جيجابايت من الذاكرة، مما يفتح الباب للنشر على الأجهزة الطرفية وتطبيقات الروبوتات والمساعدات المنزلية والمركبات ذاتية القيادة.
تقنية عد الفوتونات في Tesla AI Vision تعزز القيادة الليلية
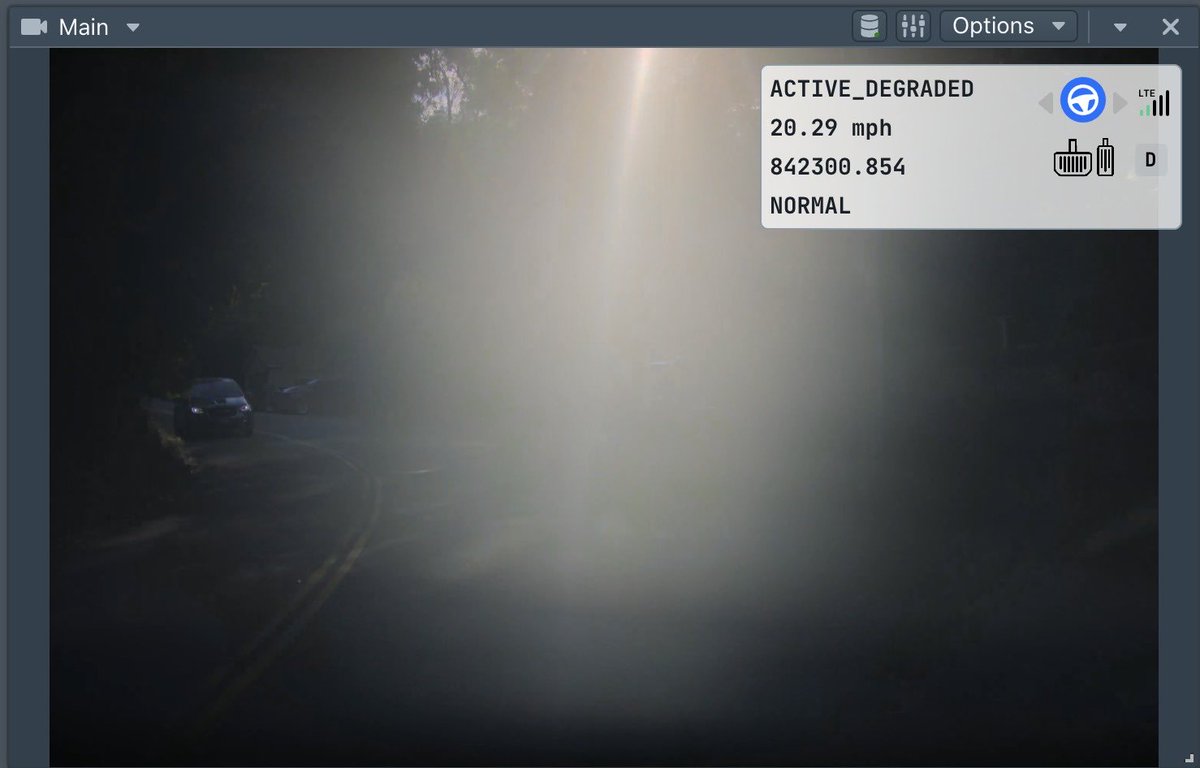
عرض Elon Musk تقنية إعادة البناء بعد الفوتونات في نظام الرؤية بالذكاء الاصطناعي من Tesla، مما يمنح FSD رؤية فائقة في الليل أو الضوء القوي. تظهر الفروقات بوضوح في الصور المقارنة التي نشرها ماسك بين الصورة كما تراها العين البشرية وإعادة بناء الذكاء الاصطناعي.
Tesla AI Vision تتنبأ بالحوادث وتنشر الوسائد الهوائية قبل الاصطدام
أعلن Elon Musk أن نظام الرؤية بالذكاء الاصطناعي من Tesla يمكنه نشر الوسائد الهوائية قبل وقوع الحادث، مما يقلل خطر الإصابة أو الوفاة، وهو مجاني في جميع السيارات الجديدة.
Anthropic يحقق في أصل سلوك الابتزاز لدى Claude
بدأت Anthropic التحقيق في سبب اختيار Claude للابتزاز، معتقدة أن مصدر السلوك الأصلي هو نصوص الإنترنت. وتأتي هذه التحقيقات في إطار جهود الشركة المستمرة لتعزيز سلامة النماذج وفهم سلوكياتها غير المتوقعة.

Demis Hassabis يحتفل بالذكرى العاشرة لـ AlphaGo مع Lee Sedol
بعد عشر سنوات من المباراة التي هزت عالم الذكاء الاصطناعي، التقى مؤسس DeepMind المشارك مع بطل Go الأسطوري في كوريا لمناقشة الإرث المستمر للنظام الذي غيّر طريقة تفكير اللاعبين المحترفين إلى الأبد.
اجتمع Demis Hassabis مع Lee Sedol في كوريا الأسبوع الماضي بمناسبة الذكرى العاشرة لمواجهة AlphaGo الشهيرة. كما شارك في مباراة Go خاصة مع Shin Jin-seo. قال هاسابيس إنه كان "من الرائع التذكير بـ AlphaGo ومن المثير للاهتمام سماع كيف غيّر الطريقة التي يتعامل بها اللاعبون مع لعبة Go". يُعد AlphaGo علامة فارقة في تاريخ الذكاء الاصطناعي، حيث كان أول نظام يهزم بطلًا بشريًا من الطراز العالمي في اللعبة الأكثر تعقيدًا المعروفة، مما أطلق موجة من التقدم في التعلم المعزز العميق.

OpenAI تطلق GPT-Realtime-2 مع التحكم الصوتي في CRM
عرضت OpenAI كيفية دمج GPT-Realtime-2 في سير عمل CRM للتحكم الصوتي، مما يتيح للمستخدمين التنقل في قواعد بيانات العملاء وتنفيذ الإجراءات دون تدخل يدوي. توضح هذه التجربة التقدم نحو واجهات الصوت الطبيعية كطبقة أساسية للتفاعل مع أنظمة المؤسسات.
Tencent Hunyuan Hy3 Preview يتصدر OpenRouter بعد الفترة المجانية
بعد انتهاء الفترة المجانية على OpenRouter، احتل Tencent Hunyuan Hy3 Preview المرتبة الأولى في استخدام الرموز والبرمجة واستدعاء الأدوات، بحصة سوقية 15.4%. النموذج لا يزال متاحًا بأسعار تنافسية ويواصل جذب المطورين بفضل أدائه المتميز في مهام البرمجة.
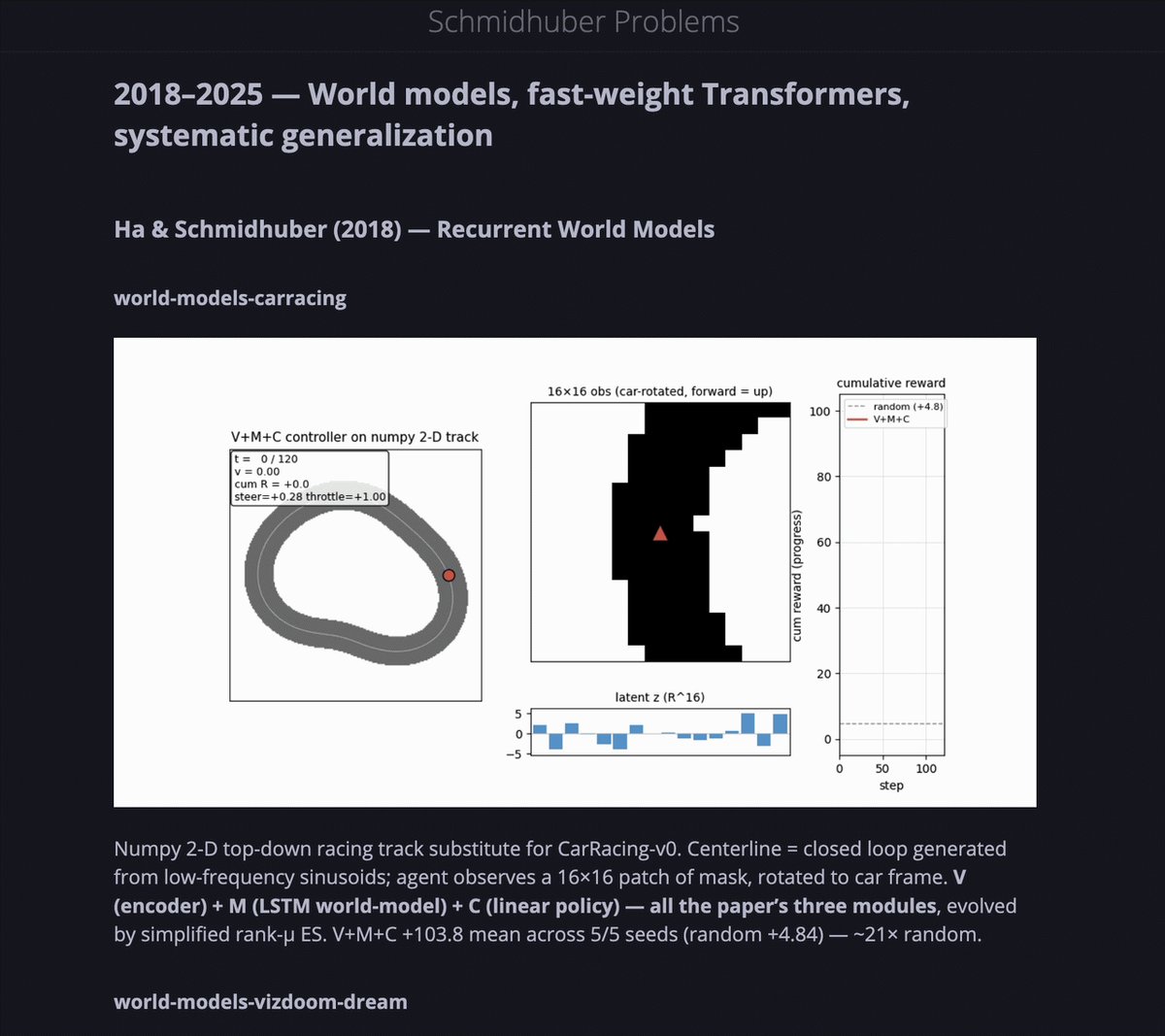
مساعد برمجة بالذكاء الاصطناعي يعيد إنتاج جميع أوراق Schmidhuber بـ NumPy خالص
مشروع Yaroslav Bulatov استخدم مساعد برمجة بالذكاء الاصطناعي لإعادة إنتاج 58 ورقة بحثية لـ Jürgen Schmidhuber من 1989 إلى 2025، بما في ذلك الورقة المؤثرة "World Models" مع تنفيذ كامل لـ VAE و RNN. جميعها تعمل على كمبيوتر محمول.
كل تنفيذ مكتوب بـ NumPy الخالص ويمكن تشغيله على كمبيوتر محمول عادي، مع مقاييس قابلة للمقارنة مع النتائج المنشورة في الأوراق الأصلية. يغطي المشروع مشاكل التعلم التركيبي عبر أكثر من ثلاثة عقود من أبحاث الشبكات العصبية. واحتفل Hardmaru، المؤلف المشارك لورقة "World Models"، بالمشروع كعرض قوي على كيفية تسريع مساعدات البرمجة بالذكاء الاصطناعي لإمكانية إعادة الإنتاج العلمي والتحقق المستقل من النتائج التاريخية.
«البرمجة الوكيلة هي شكل من أشكال التعلم الآلي. يجب معاملة الكود المُنتَج كمنتج صندوق أسود تُدار سلوكياته وتعميمه من خلال التقييم التجريبي، كما هو الحال مع أي نموذج تعلم آلي.»
Higgsfield تطلق مصنع محتوى بالذكاء الاصطناعي: Claude + MCP + متنبئ فيروسي
أطلقت Higgsfield مصنع محتوى يدمج Claude و MCP ومتنبئ فيروسي لتكرار وتسجيل تنسيقات الفيديو الشائعة تلقائيًا. يقوم النظام بنسخ تنسيقات الفيديو الرائجة دون حاجة إلى كتابة prompts، ويُسجّل كل مخرج بالمتنبئ الفيروسي لإنشاء خط أنابيب محتوى متراكم.
StepAudio 2.5 TTS يحتل المراكز الثلاثة الأولى عالميًا في Voice Arena
تم تصنيف StepAudio 2.5 TTS من Stepfun ضمن أفضل ثلاثة نماذج عالميًا في Artificial Analysis Voice Arena عبر اختبارات عمياء مع مستمعين حقيقيين. وهو أعلى نموذج TTS صيني تصنيفًا في هذا التصنيف المستقل.
«لا يوجد ما قبل التدريب ولا ما بعده: لا يوجد سوى التدريب»
يقترح الباحث Arohan إلغاء الفروق المصطنعة بين مراحل التدريب. لا يوجد سوى الأوليات والتحديثات والقيود وميزانية الحوسبة. "في السنوات الأخيرة قمنا بشحن الهيكل التنظيمي إلى علم التحسين الأساسي"، كما صرح.
Sam Altman يصف GPT-5.5 بأنه "عبقري متوحد" بذوق تسمية غريب
وصف الرئيس التنفيذي لـ OpenAI سام ألتمان نموذج GPT-5.5 بأنه "عبقري متوحد ذو ذوق غريب جدًا في التسمية"، مضيفًا أنه "من الصادم أن نصنع شيئًا كهذا". أثارت تصريحاته نقاشًا مجتمعيًا واسعًا حول الشخصية الناشئة للنماذج.
François Chollet: الذكاء الاصطناعي يضخم فجوة الفاعلية بين المستخدمين
يحذر مؤلف Keras من أن الذكاء الاصطناعي يضخم تأثيرًا موجودًا مسبقًا: المستخدمون ذوو الفاعلية المنخفضة يفقدون المزيد من السيطرة، بينما يكتسب ذوو الفاعلية العالية قدرة أكبر على المناورة والتأثير.
GPT-Realtime-2 يحقق ترجمة صوتية فورية بين اللغات
تم استخدام واجهة الصوت الجديدة من OpenAI لترجمة الصوت فوريًا بين اللغات، مما يبرز قدرات GPT-Realtime-2 في التفاعل الصوتي متعدد اللغات في الزمن الحقيقي دون الحاجة إلى خطوات وسيطة.

Luma تطلق أداة التوظيف البصري المدعومة بالذكاء الاصطناعي Luma Agents
أطلقت Luma أداة إبداعية باسم Luma Agents لمساعدة الفرق في تخطيط وإنشاء وتحسين المحتوى البصري لحملات التوظيف، مع الحفاظ على اتساق السياق طوال سير العمل الإبداعي.

التقطير متعدد المعلمين يتفوق على تدريب RL متعدد المجالات
يجادل أحد الباحثين بأن التقطير المباشر متعدد المعلمين يقدم مزايا مقارنة بالتدريب التعزيزي في مجالات متعددة، والذي يعاني من صعوبات إحصائية ونمذجة على حد سواء.

swyx يوصي بدورة "إلزامية" لجميع مهندسي الذكاء الاصطناعي
قارن swyx برنامجًا تعليميًا تقنيًا جديدًا بـ "Kubernetes The Hard Way" الأسطوري لـ Kelsey Hightower، مجادلًا بأن كل مهندس ذكاء اصطناعي يجب أن يكمله مرة واحدة على الأقل.
Ethan Mollick يدعو لإنشاء معايير مستقلة للروبوتات
يشير أستاذ وارتون إلى أنه بينما يمتلك الذكاء الاصطناعي معايير مثل ARC-AGI، تفتقر الروبوتات إلى معايير مستقلة مماثلة. ويقترح إنشاء ARC-AGI-BOT لقياس التقدم الحقيقي في الروبوتات.

إجماع صناعي: Markdown للمنطق و HTML للعرض في منتجات الذكاء الاصطناعي
يتجه المجتمع نحو إجماع على أن منتجات الذكاء الاصطناعي تتبنى معمارية فصل البيانات عن العرض، مع Markdown كطبقة تخزين منطقي وذاكرة، و HTML للتفاعل البصري عالي الكثافة.
Claude يتبنى HTML كتنسيق داخلي لإدارة المستندات داخل Anthropic
داخل Anthropic، يستخدم Claude بشكل متزايد HTML لإدارة جميع أنواع المستندات، وهو نهيج يجمع بين البراغماتية والرؤية المستقبلية في التفاعل بين الإنسان والآلة.
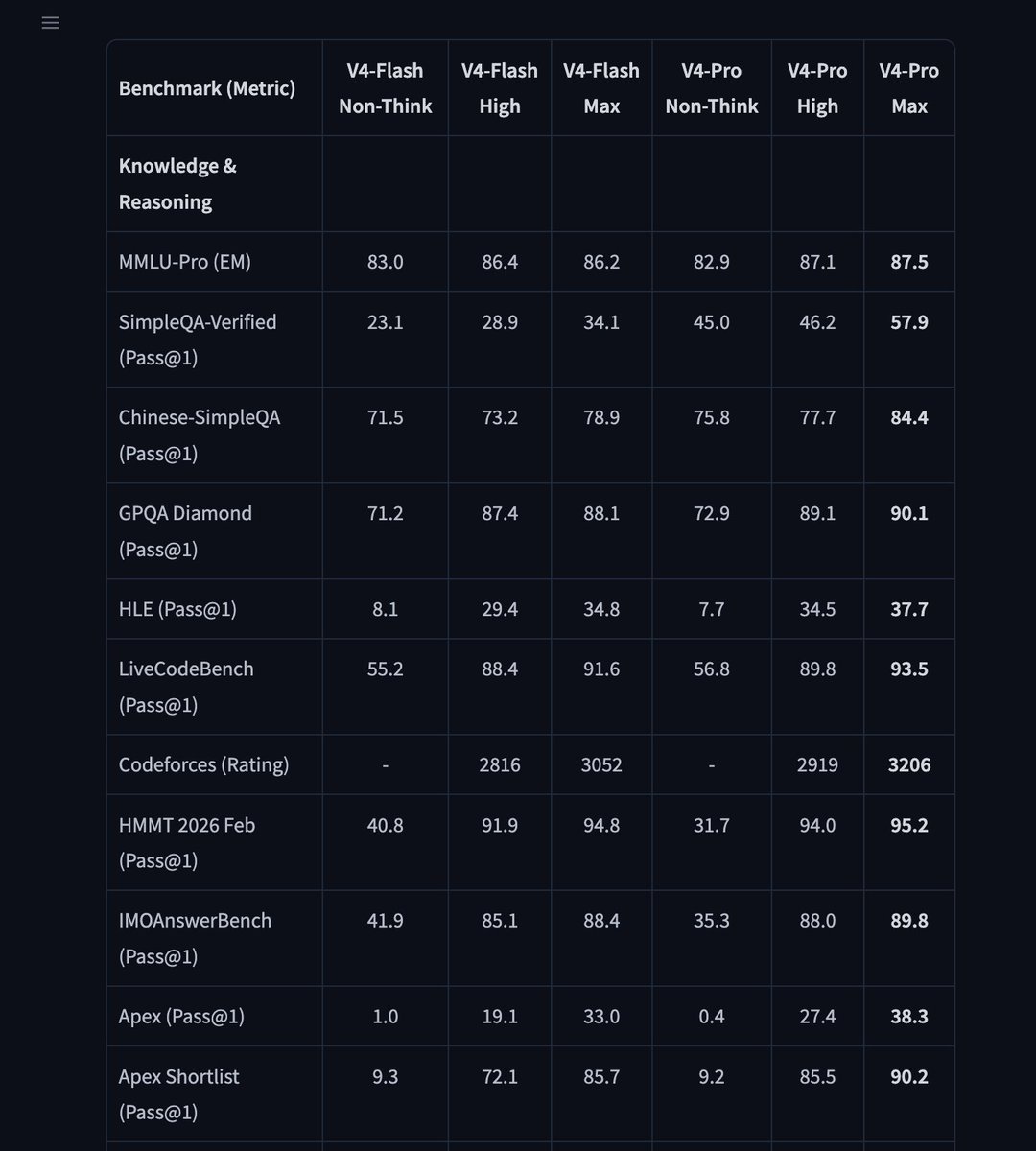
V4 Flash: نموذج صغير بأداء الطرازات الرائدة
بأقل من 20 مليار معامل نشط وحوالي 300 مليار إجمالاً، ينافس V4 Flash في فئة MiMo V2.5 و Step 3.5، مع سياق أطول من النماذج الرائدة وضعف السرعة بجزء بسيط من التكلفة.
DeepSeek يدعي تفوق أنوية MLX المولدة بالذكاء الاصطناعي على البشرية
تؤكد DeepSeek أن أنوية MLX المولدة بالذكاء الاصطناعي تتفوق على التطبيقات اليدوية، محققة 10 رموز/ثانية في fp16 و 18 في q8. لا يزال المشروع صعب التدقيق المستقل.
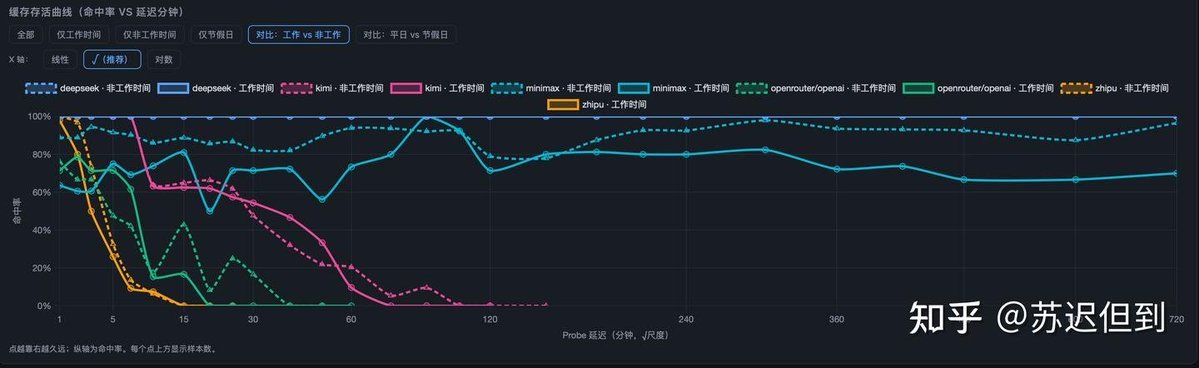
DeepSeek تحقق نسبة 100% في إصابة الذاكرة المؤقتة للسياق المعاد استخدامه
تظهر إحصائيات الذاكرة المؤقتة لـ DeepSeek تطبيقًا مثاليًا صارمًا: كل سياق قابل لإعادة الاستخدام يتم استرجاعه دون أخطاء، مع نافذة إعادة استخدام تقدر بـ 24 إلى 48 ساعة.
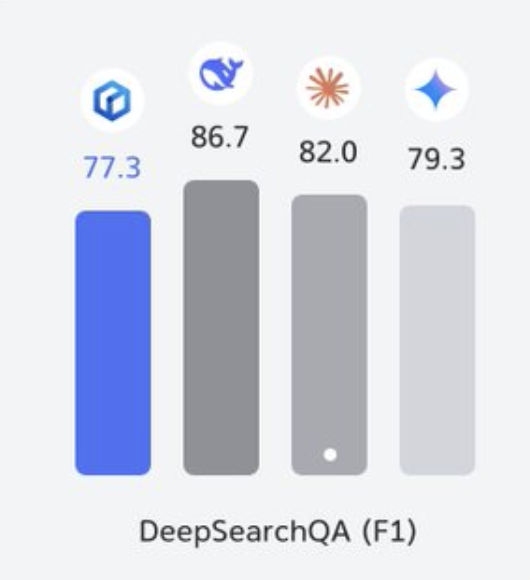
Baidu تكشف عن ERNIE 5.1 باستخراج شبكات فرعية فعال
تفاجئ Baidu بـ ERNIE 5.1 الذي يستخدم تقنية مشابهة لـ REAP لاشتقاق نموذج فرعي فعال من ERNIE 5.0، محققًا تحسنًا بنسبة 6% في الكفاءة دون فقدان ملحوظ في الجودة.
Sam Altman يطلب أفكارًا من المجتمع للجيل التالي من النماذج
استشار الرئيس التنفيذي لـ OpenAI المستخدمين علنًا حول التحسينات التي يرغبون في رؤيتها في النماذج القادمة، فاتحًا قناة مباشرة للتغذية الراجعة مع المجتمع.
ابنة باحث DeepMind: "Jensen Huang اشترى وقتًا للبشرية ببطاقات GPU باهظة الثمن"
قدمت ابنة Denny Zhou، الباحث في Google DeepMind، منظورًا غير متوقع: رقائق NVIDIA باهظة الثمن تبطئ تقدم الذكاء الاصطناعي بما يكفي لإعطاء هامش للتكيف الاجتماعي.

MiniMax و GMO تنظمان ورشة عملية لـ Hailuo AI في طوكيو
ستعقد MiniMax و GMO Internet ورشة عمل حضورية في 14 مايو بطوكيو، حيث سيستخدم المشاركون Hailuo AI لتوليد الصور والفيديو وبناء مهارات وكيل ذكاء اصطناعي شخصية على منصة MiniMax Hub.
Elon Musk يلمح لميزة Grok Imagine
ألمح ماسك إلى قدرة قادمة لتوليد الصور في Grok، موسعًا نطاق النموذج لما وراء النص.
دراسة جديدة توضح كيفية اتباع النماذج لتعليمات النظام
ورقة بحثية حديثة تحلل الآليات الداخلية التي تحدد ما إذا كان نموذج اللغة يطيع أو يتجاهل توجيهات system prompt.
نماذج Alec Radford المبكرة كانت أسهل في المحاذاة
تأمل يشير إلى أن النماذج الأولية لـ Radford، بسبب بساطتها، ربما كانت قابلة للمحاذاة بشكل جوهري أكثر من البنى الحالية.
نموذج prompting لتوليد عروض بأسلوب الحبر الصيني
يشارك المجتمع prompts محسنة لـ GPT Image 2 لتوليد شرائح بجمالية الألوان المائية الشرقية.
مولد أغلفة أخبار تقنية باللغة الصينية بـ GPT Image 2
Prompt متخصص يتيح لـ GPT Image 2 إنشاء أغلفة بأسلوب صحفي لأخبار العلوم والتكنولوجيا.
Agent-1 عند مستوى أفضل المصادر المفتوحة الصينية حاليًا
تحليل يضع Agent-1 عند مستوى مماثل لنماذج المصادر المفتوحة الصينية الحديثة بالإضافة إلى Hermes، مما يشير إلى أن الفاعلية تثبت أنها أسهل مما كان متوقعًا.
Kimi و GLM ينافسان أفضل المختبرات حتى 128 ألف رمز
تظهر نتائج حديثة أن Kimi و GLM تنافسيان مع أفضل المختبرات في السياقات الطويلة، بينما تحصل DeepSeek على نتائج مخيبة للآمال.
جدل حول مكاسب كفاءة التدريب لدى Baidu: هل هي حقيقية؟
مصطلح "التدريب المسبق المرن متعدد الأبعاد" يبدو مثيرًا، لكن المحللين يشككون في أن مكسب 6% ناتج فقط عن تقليص النموذج وليس عن كفاءة تدريب حقيقية.